 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Uncertainty Estimation with Delta Variances
Feb 20, 2025

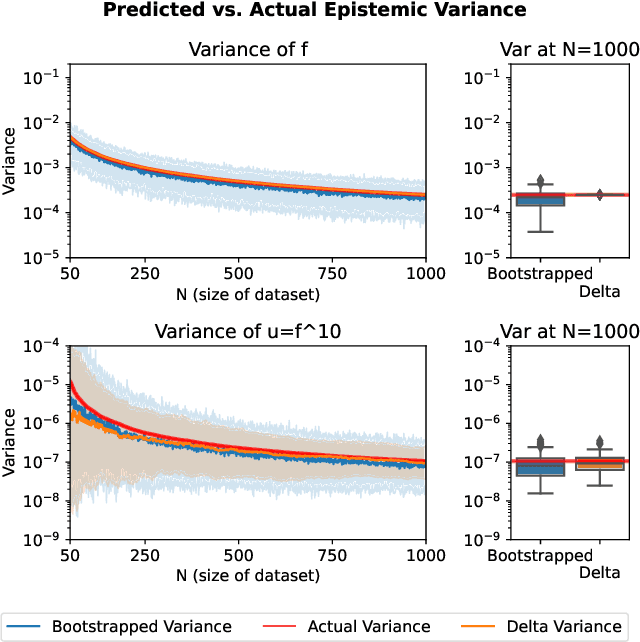

Decision makers may suffer from uncertainty induced by limited data. This may be mitigated by accounting for epistemic uncertainty, which is however challenging to estimate efficiently for large neural networks. To this extent we investigate Delta Variances, a family of algorithms for epistemic uncertainty quantification, that is computationally efficient and convenient to implement. It can be applied to neural networks and more general functions composed of neural networks. As an example we consider a weather simulator with a neural-network-based step function inside -- here Delta Variances empirically obtain competitive results at the cost of a single gradient computation. The approach is convenient as it requires no changes to the neural network architecture or training procedure. We discuss multiple ways to derive Delta Variances theoretically noting that special cases recover popular techniques and present a unified perspective on multiple related methods. Finally we observe that this general perspective gives rise to a natural extension and empirically show its benefit.
Exploration via Epistemic Value Estimation
Mar 07, 2023

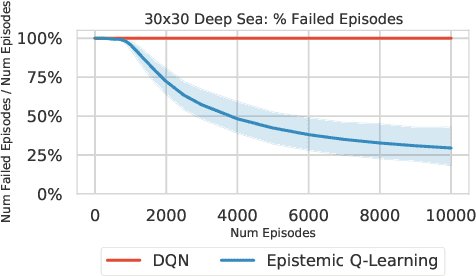
How to efficiently explore in reinforcement learning is an open problem. Many exploration algorithms employ the epistemic uncertainty of their own value predictions -- for instance to compute an exploration bonus or upper confidence bound. Unfortunately the required uncertainty is difficult to estimate in general with function approximation. We propose epistemic value estimation (EVE): a recipe that is compatible with sequential decision making and with neural network function approximators. It equips agents with a tractable posterior over all their parameters from which epistemic value uncertainty can be computed efficiently. We use the recipe to derive an epistemic Q-Learning agent and observe competitive performance on a series of benchmarks. Experiments confirm that the EVE recipe facilitates efficient exploration in hard exploration tasks.
Chaining Value Functions for Off-Policy Learning
Feb 02, 2022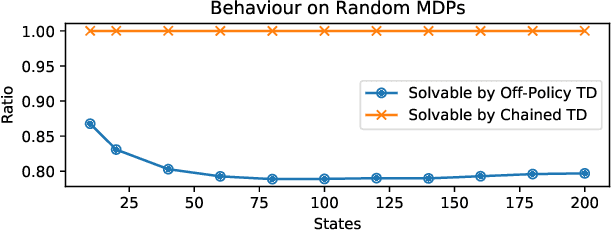
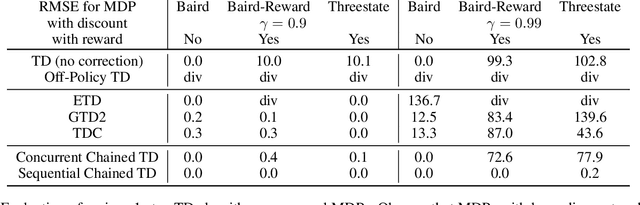
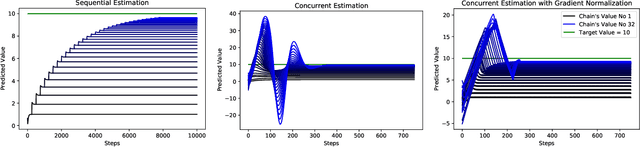
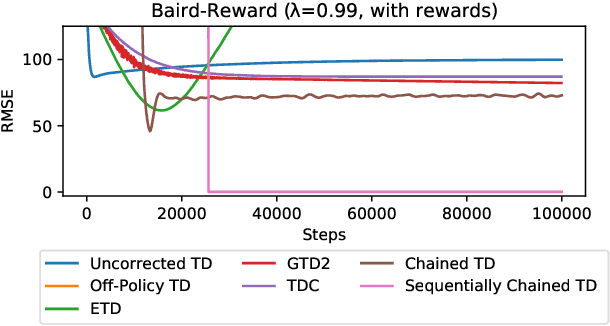
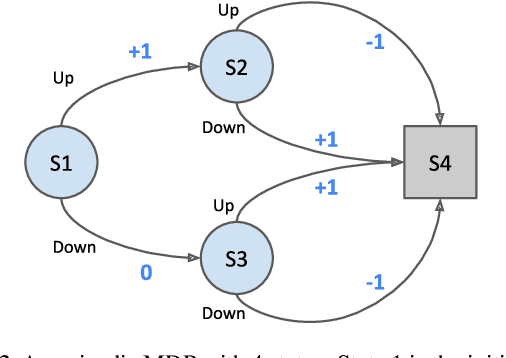
To accumulate knowledge and improve its policy of behaviour, a reinforcement learning agent can learn `off-policy' about policies that differ from the policy used to generate its experience. This is important to learn counterfactuals, or because the experience was generated out of its own control. However, off-policy learning is non-trivial, and standard reinforcement-learning algorithms can be unstable and divergent. In this paper we discuss a novel family of off-policy prediction algorithms which are convergent by construction. The idea is to first learn on-policy about the data-generating behaviour, and then bootstrap an off-policy value estimate on this on-policy estimate, thereby constructing a value estimate that is partially off-policy. This process can be repeated to build a chain of value functions, each time bootstrapping a new estimate on the previous estimate in the chain. Each step in the chain is stable and hence the complete algorithm is guaranteed to be stable. Under mild conditions this comes arbitrarily close to the off-policy TD solution when we increase the length of the chain. Hence it can compute the solution even in cases where off-policy TD diverges. We prove that the proposed scheme is convergent and corresponds to an iterative decomposition of the inverse key matrix. Furthermore it can be interpreted as estimating a novel objective -- that we call a `k-step expedition' -- of following the target policy for finitely many steps before continuing indefinitely with the behaviour policy. Empirically we evaluate the idea on challenging MDPs such as Baird's counter example and observe favourable results.
Learning and Planning in Complex Action Spaces
Apr 13, 2021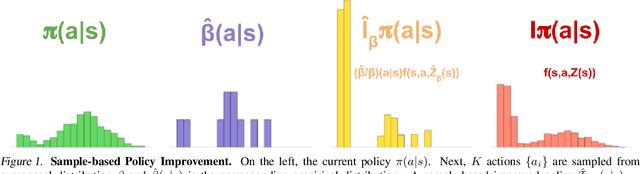
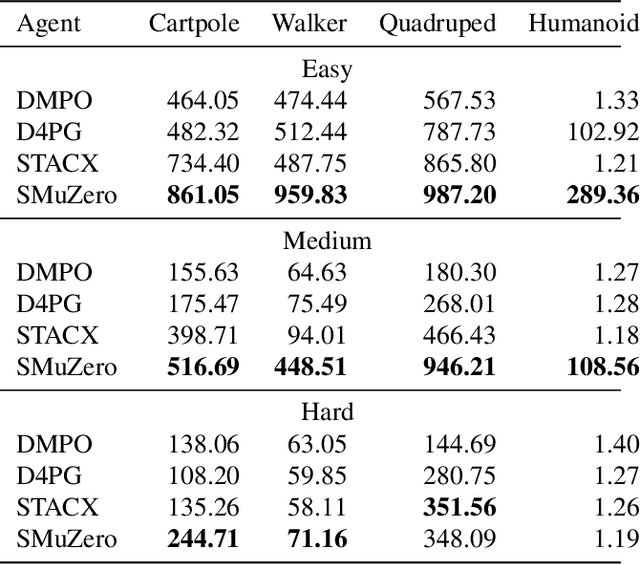
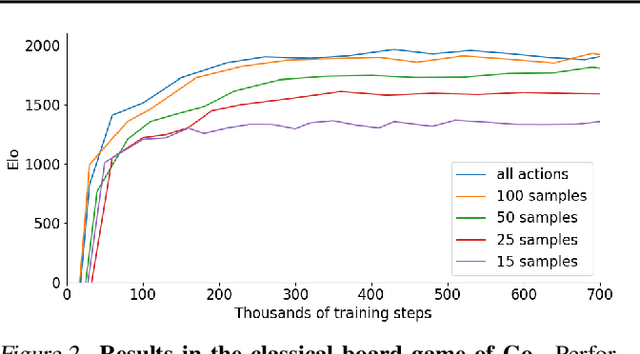
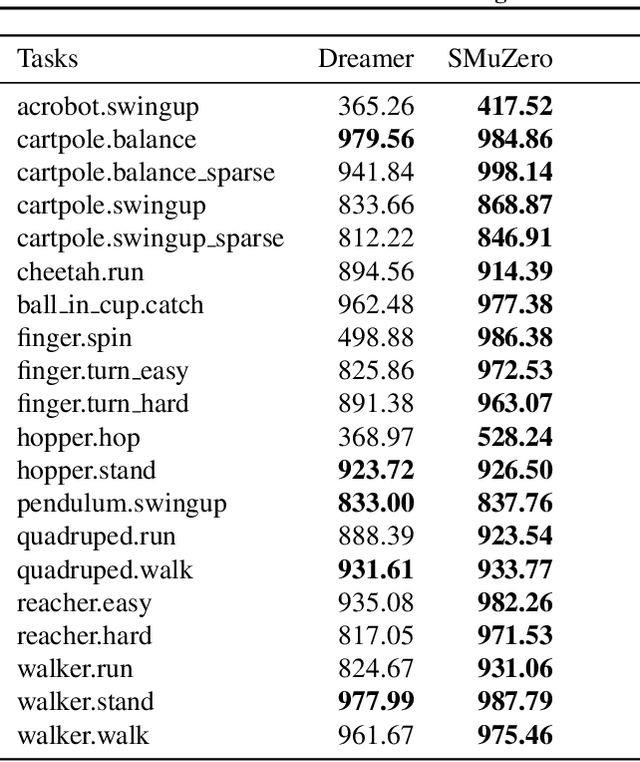
Many important real-world problems have action spaces that are high-dimensional, continuous or both, making full enumeration of all possible actions infeasible. Instead, only small subsets of actions can be sampled for the purpose of policy evaluation and improvement. In this paper, we propose a general framework to reason in a principled way about policy evaluation and improvement over such sampled action subsets. This sample-based policy iteration framework can in principle be applied to any reinforcement learning algorithm based upon policy iteration. Concretely, we propose Sampled MuZero, an extension of the MuZero algorithm that is able to learn in domains with arbitrarily complex action spaces by planning over sampled actions. We demonstrate this approach on the classical board game of Go and on two continuous control benchmark domains: DeepMind Control Suite and Real-World RL Suite.
Muesli: Combining Improvements in Policy Optimization
Apr 13, 2021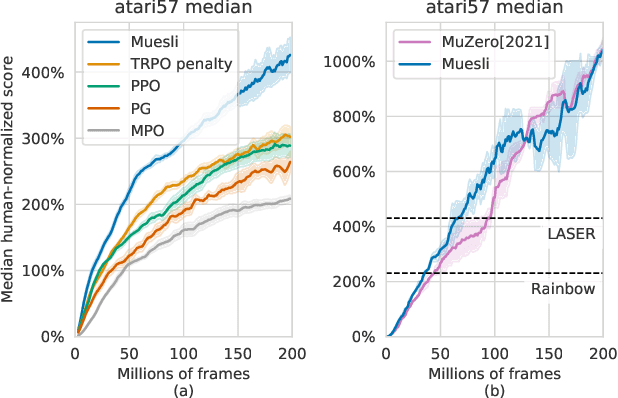

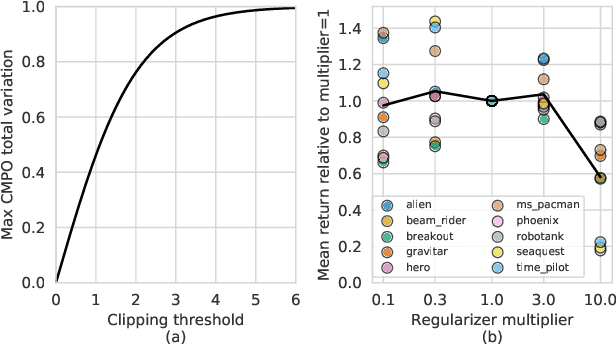
We propose a novel policy update that combines regularized policy optimization with model learning as an auxiliary loss. The update (henceforth Muesli) matches MuZero's state-of-the-art performance on Atari. Notably, Muesli does so without using deep search: it acts directly with a policy network and has computation speed comparable to model-free baselines. The Atari results are complemented by extensive ablations, and by additional results on continuous control and 9x9 Go.
AlgebraNets
Jun 16, 2020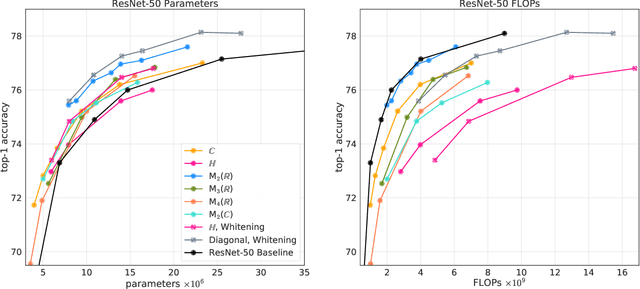
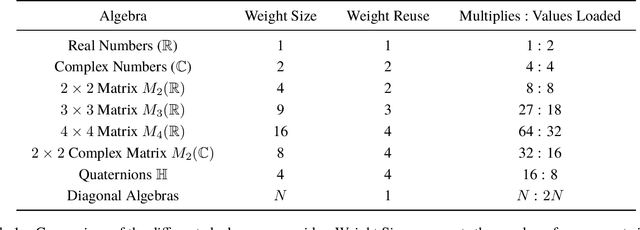
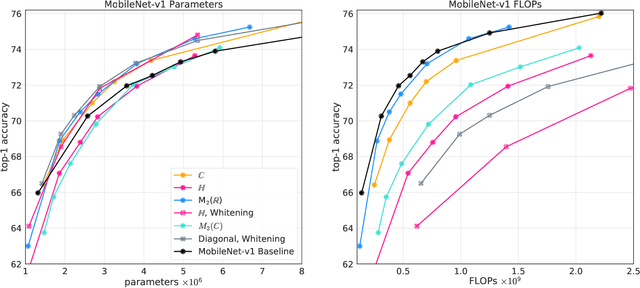

Neural networks have historically been built layerwise from the set of functions in ${f: \mathbb{R}^n \to \mathbb{R}^m }$, i.e. with activations and weights/parameters represented by real numbers, $\mathbb{R}$. Our work considers a richer set of objects for activations and weights, and undertakes a comprehensive study of alternative algebras as number representations by studying their performance on two challenging problems: large-scale image classification using the ImageNet dataset and language modeling using the enwiki8 and WikiText-103 datasets. We denote this broader class of models as AlgebraNets. Our findings indicate that the conclusions of prior work, which explored neural networks constructed from $\mathbb{C}$ (complex numbers) and $\mathbb{H}$ (quaternions) on smaller datasets, do not always transfer to these challenging settings. However, our results demonstrate that there are alternative algebras which deliver better parameter and computational efficiency compared with $\mathbb{R}$. We consider $\mathbb{C}$, $\mathbb{H}$, $M_{2}(\mathbb{R})$ (the set of $2\times2$ real-valued matrices), $M_{2}(\mathbb{C})$, $M_{3}(\mathbb{R})$ and $M_{4}(\mathbb{R})$. Additionally, we note that multiplication in these algebras has higher compute density than real multiplication, a useful property in situations with inherently limited parameter reuse such as auto-regressive inference and sparse neural networks. We therefore investigate how to induce sparsity within AlgebraNets. We hope that our strong results on large-scale, practical benchmarks will spur further exploration of these unconventional architectures which challenge the default choice of using real numbers for neural network weights and activations.
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Nov 19, 2019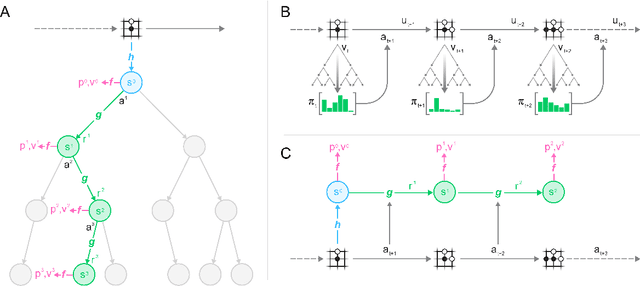
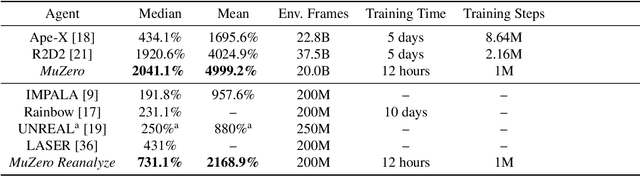
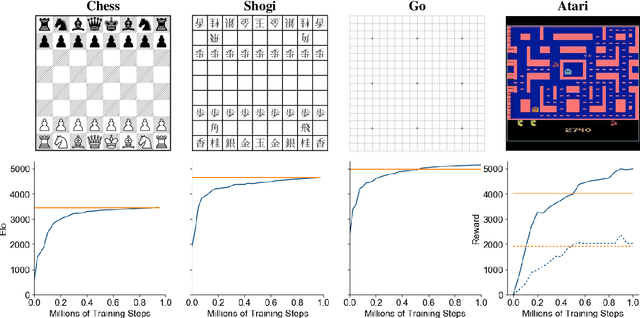
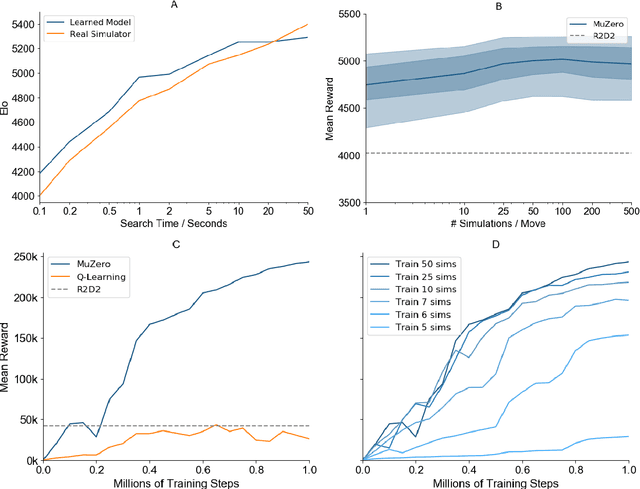
Constructing agents with planning capabilities has long been one of the main challenges in the pursuit of artificial intelligence. Tree-based planning methods have enjoyed huge success in challenging domains, such as chess and Go, where a perfect simulator is available. However, in real-world problems the dynamics governing the environment are often complex and unknown. In this work we present the MuZero algorithm which, by combining a tree-based search with a learned model, achieves superhuman performance in a range of challenging and visually complex domains, without any knowledge of their underlying dynamics. MuZero learns a model that, when applied iteratively, predicts the quantities most directly relevant to planning: the reward, the action-selection policy, and the value function. When evaluated on 57 different Atari games - the canonical video game environment for testing AI techniques, in which model-based planning approaches have historically struggled - our new algorithm achieved a new state of the art. When evaluated on Go, chess and shogi, without any knowledge of the game rules, MuZero matched the superhuman performance of the AlphaZero algorithm that was supplied with the game rules.
Gated Linear Networks
Sep 30, 2019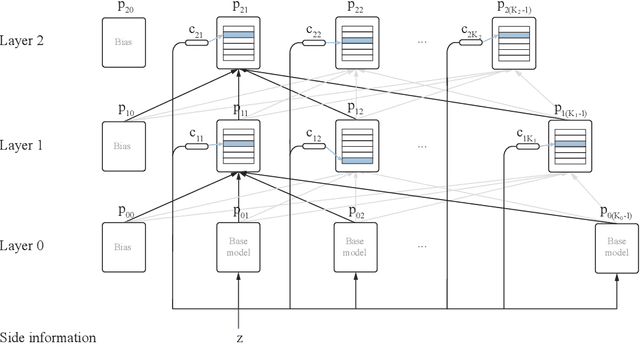
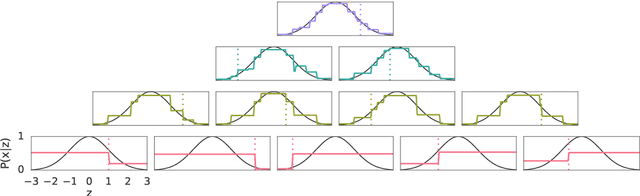
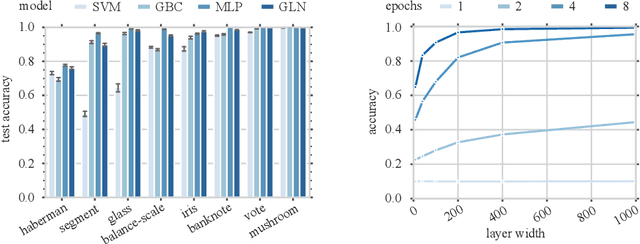
This paper presents a family of backpropagation-free neural architectures, Gated Linear Networks (GLNs),that are well suited to online learning applications where sample efficiency is of paramount importance. The impressive empirical performance of these architectures has long been known within the data compression community, but a theoretically satisfying explanation as to how and why they perform so well has proven difficult. What distinguishes these architectures from other neural systems is the distributed and local nature of their credit assignment mechanism; each neuron directly predicts the target and has its own set of hard-gated weights that are locally adapted via online convex optimization. By providing an interpretation, generalization and subsequent theoretical analysis, we show that sufficiently large GLNs are universal in a strong sense: not only can they model any compactly supported, continuous density function to arbitrary accuracy, but that any choice of no-regret online convex optimization technique will provably converge to the correct solution with enough data. Empirically we show a collection of single-pass learning results on established machine learning benchmarks that are competitive with results obtained with general purpose batch learning techniques.
Off-Policy Actor-Critic with Shared Experience Replay
Sep 25, 2019

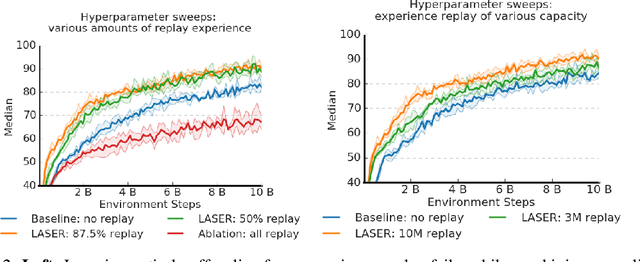
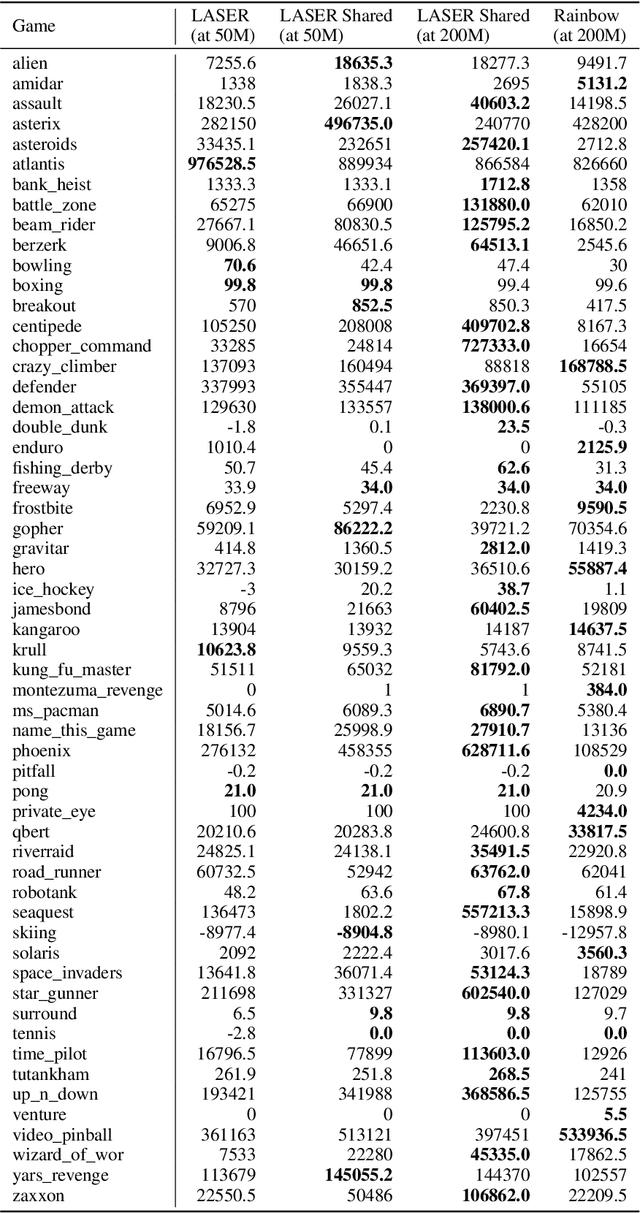
We investigate the combination of actor-critic reinforcement learning algorithms with uniform large-scale experience replay and propose solutions for two challenges: (a) efficient actor-critic learning with experience replay (b) stability of very off-policy learning. We employ those insights to accelerate hyper-parameter sweeps in which all participating agents run concurrently and share their experience via a common replay module. To this end we analyze the bias-variance tradeoffs in V-trace, a form of importance sampling for actor-critic methods. Based on our analysis, we then argue for mixing experience sampled from replay with on-policy experience, and propose a new trust region scheme that scales effectively to data distributions where V-trace becomes unstable. We provide extensive empirical validation of the proposed solution. We further show the benefits of this setup by demonstrating state-of-the-art data efficiency on Atari among agents trained up until 200M environment frames.
Multi-task Deep Reinforcement Learning with PopArt
Sep 12, 2018
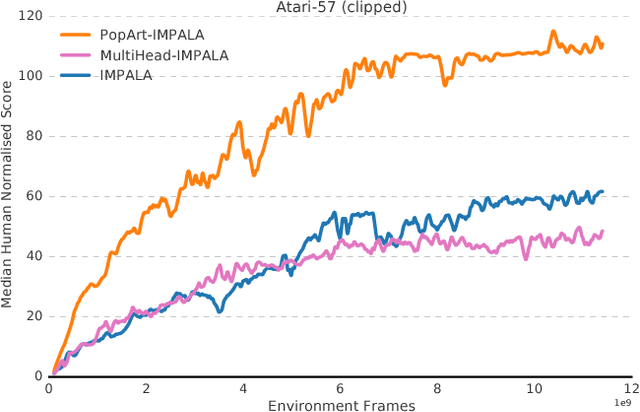

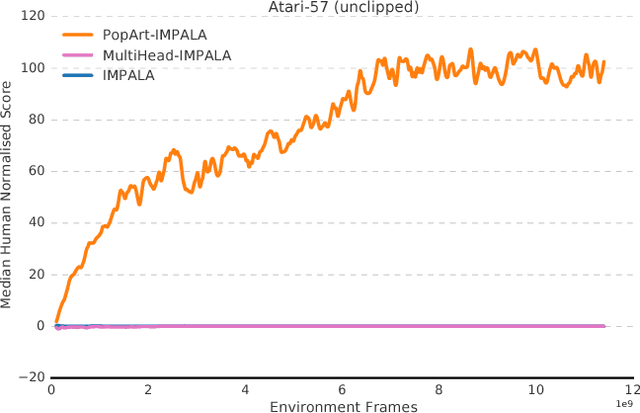
The reinforcement learning community has made great strides in designing algorithms capable of exceeding human performance on specific tasks. These algorithms are mostly trained one task at the time, each new task requiring to train a brand new agent instance. This means the learning algorithm is general, but each solution is not; each agent can only solve the one task it was trained on. In this work, we study the problem of learning to master not one but multiple sequential-decision tasks at once. A general issue in multi-task learning is that a balance must be found between the needs of multiple tasks competing for the limited resources of a single learning system. Many learning algorithms can get distracted by certain tasks in the set of tasks to solve. Such tasks appear more salient to the learning process, for instance because of the density or magnitude of the in-task rewards. This causes the algorithm to focus on those salient tasks at the expense of generality. We propose to automatically adapt the contribution of each task to the agent's updates, so that all tasks have a similar impact on the learning dynamics. This resulted in state of the art performance on learning to play all games in a set of 57 diverse Atari games. Excitingly, our method learned a single trained policy - with a single set of weights - that exceeds median human performance. To our knowledge, this was the first time a single agent surpassed human-level performance on this multi-task domain. The same approach also demonstrated state of the art performance on a set of 30 tasks in the 3D reinforcement learning platform DeepMind Lab.