 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration via Epistemic Value Estimation
Paper and Code
Mar 07, 2023

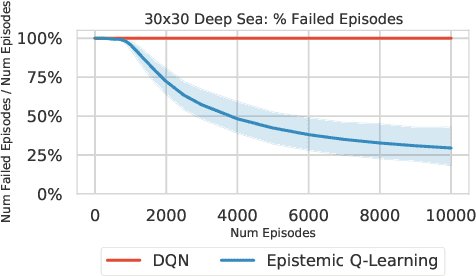
How to efficiently explore in reinforcement learning is an open problem. Many exploration algorithms employ the epistemic uncertainty of their own value predictions -- for instance to compute an exploration bonus or upper confidence bound. Unfortunately the required uncertainty is difficult to estimate in general with function approximation. We propose epistemic value estimation (EVE): a recipe that is compatible with sequential decision making and with neural network function approximators. It equips agents with a tractable posterior over all their parameters from which epistemic value uncertainty can be computed efficiently. We use the recipe to derive an epistemic Q-Learning agent and observe competitive performance on a series of benchmarks. Experiments confirm that the EVE recipe facilitates efficient exploration in hard exploration tasks.