 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaining Value Functions for Off-Policy Learning
Paper and Code
Feb 02, 2022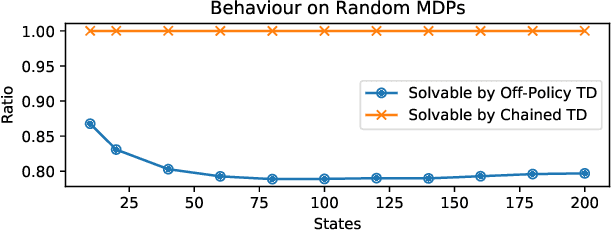
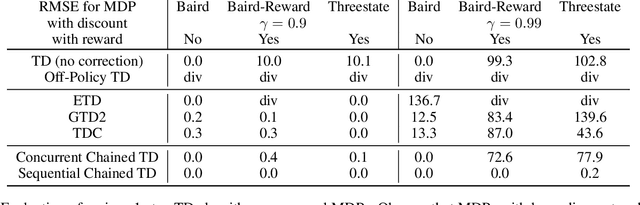
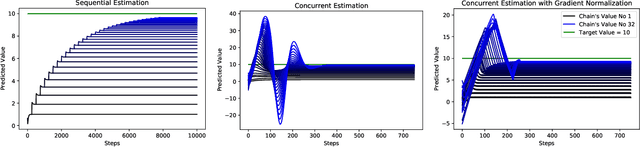
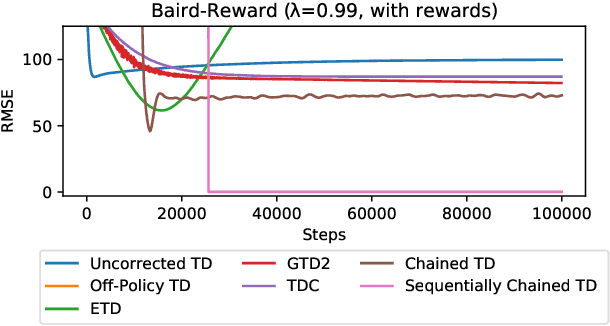
To accumulate knowledge and improve its policy of behaviour, a reinforcement learning agent can learn `off-policy' about policies that differ from the policy used to generate its experience. This is important to learn counterfactuals, or because the experience was generated out of its own control. However, off-policy learning is non-trivial, and standard reinforcement-learning algorithms can be unstable and divergent. In this paper we discuss a novel family of off-policy prediction algorithms which are convergent by construction. The idea is to first learn on-policy about the data-generating behaviour, and then bootstrap an off-policy value estimate on this on-policy estimate, thereby constructing a value estimate that is partially off-policy. This process can be repeated to build a chain of value functions, each time bootstrapping a new estimate on the previous estimate in the chain. Each step in the chain is stable and hence the complete algorithm is guaranteed to be stable. Under mild conditions this comes arbitrarily close to the off-policy TD solution when we increase the length of the chain. Hence it can compute the solution even in cases where off-policy TD diverges. We prove that the proposed scheme is convergent and corresponds to an iterative decomposition of the inverse key matrix. Furthermore it can be interpreted as estimating a novel objective -- that we call a `k-step expedition' -- of following the target policy for finitely many steps before continuing indefinitely with the behaviour policy. Empirically we evaluate the idea on challenging MDPs such as Baird's counter example and observe favourable results.