 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturBench: Benchmarking Machine Learning Models for Cellular Perturbation Analysis
Aug 20, 2024



We present a comprehensive framework for predicting the effects of perturbations in single cells, designed to standardize benchmarking in this rapidly evolving field. Our framework, PerturBench, includes a user-friendly platform, diverse datasets, metrics for fair model comparison, and detailed performance analysis. Extensive evaluations of published and baseline models reveal limitations like mode or posterior collapse, and underscore the importance of rank metrics that assess the ordering of perturbations alongside traditional measures like RMSE. Our findings show that simple models can outperform more complex approaches. This benchmarking exercise sets new standards for model evaluation, supports robust model development, and advances the potential of these models to use high-throughput and high-content genetic and chemical screens for disease target discovery.
Game Theoretic Rating in N-player general-sum games with Equilibria
Oct 05, 2022



Rating strategies in a game is an important area of research in game theory and artificial intelligence, and can be applied to any real-world competitive or cooperative setting. Traditionally, only transitive dependencies between strategies have been used to rate strategies (e.g. Elo), however recent work has expanded ratings to utilize game theoretic solutions to better rate strategies in non-transitive games. This work generalizes these ideas and proposes novel algorithms suitable for N-player, general-sum rating of strategies in normal-form games according to the payoff rating system. This enables well-established solution concepts, such as equilibria, to be leveraged to efficiently rate strategies in games with complex strategic interactions, which arise in multiagent training and real-world interactions between many agents. We empirically validate our methods on real world normal-form data (Premier League) and multiagent reinforcement learning agent evaluation.
NeuPL: Neural Population Learning
Feb 15, 2022



Learning in strategy games (e.g. StarCraft, poker) requires the discovery of diverse policies. This is often achieved by iteratively training new policies against existing ones, growing a policy population that is robust to exploit. This iterative approach suffers from two issues in real-world games: a) under finite budget, approximate best-response operators at each iteration needs truncating, resulting in under-trained good-responses populating the population; b) repeated learning of basic skills at each iteration is wasteful and becomes intractable in the presence of increasingly strong opponents. In this work, we propose Neural Population Learning (NeuPL) as a solution to both issues. NeuPL offers convergence guarantees to a population of best-responses under mild assumptions. By representing a population of policies within a single conditional model, NeuPL enables transfer learning across policies. Empirically, we show the generality, improved performance and efficiency of NeuPL across several test domains. Most interestingly, we show that novel strategies become more accessible, not less, as the neural population expands.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022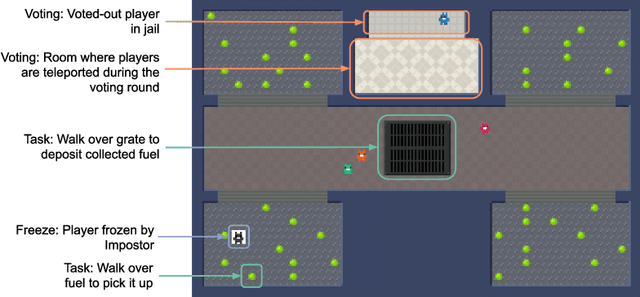

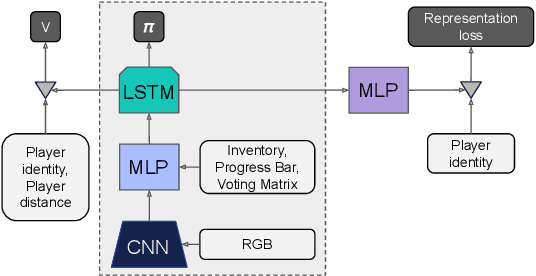
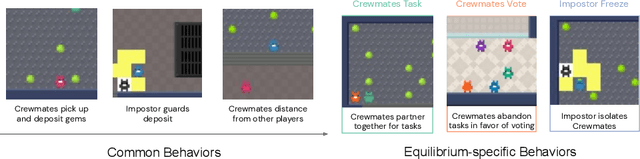
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
A PAC-Bayesian Analysis of Distance-Based Classifiers: Why Nearest-Neighbour works!
Sep 28, 2021


Abstract We present PAC-Bayesian bounds for the generalisation error of the K-nearest-neighbour classifier (K-NN). This is achieved by casting the K-NN classifier into a kernel space framework in the limit of vanishing kernel bandwidth. We establish a relation between prior measures over the coefficients in the kernel expansion and the induced measure on the weight vectors in kernel space. Defining a sparse prior over the coefficients allows the application of a PAC-Bayesian folk theorem that leads to a generalisation bound that is a function of the number of redundant training examples: those that can be left out without changing the solution. The presented bound requires to quantify a prior belief in the sparseness of the solution and is evaluated after learning when the actual redundancy level is known. Even for small sample size (m ~ 100) the bound gives non-trivial results when both the expected sparseness and the actual redundancy are high.
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Jul 14, 2021
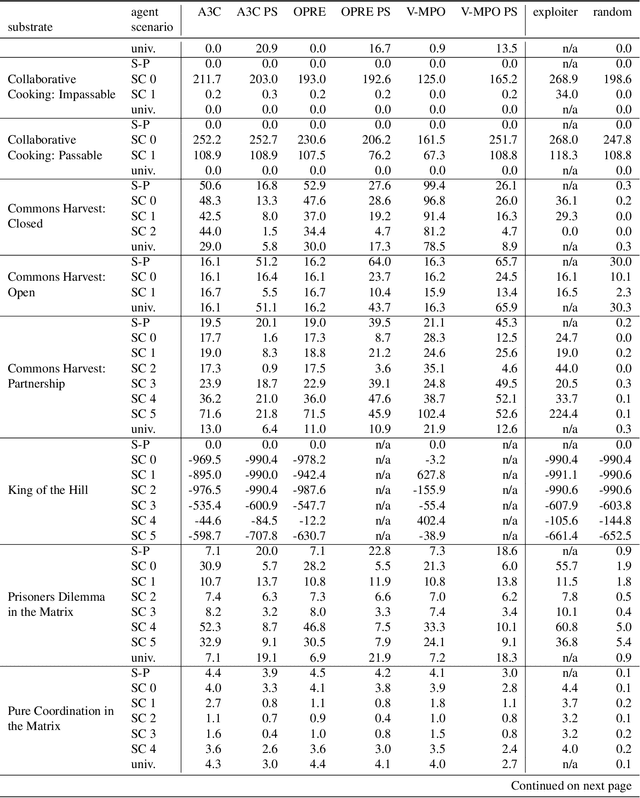
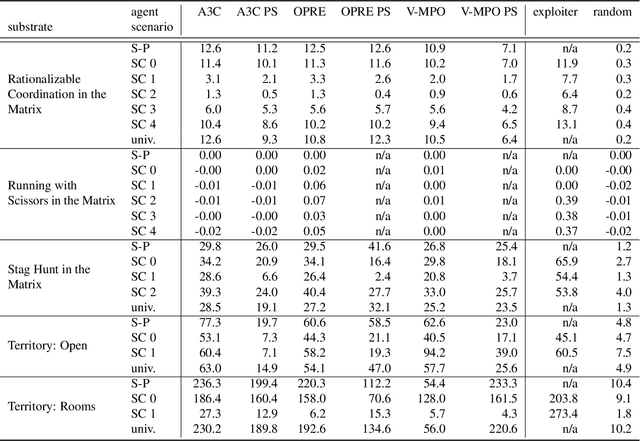
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
* Accepted to ICML 2021 and presented as a long talk; 33 pages; 9 figures
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Jun 22, 2021



Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021

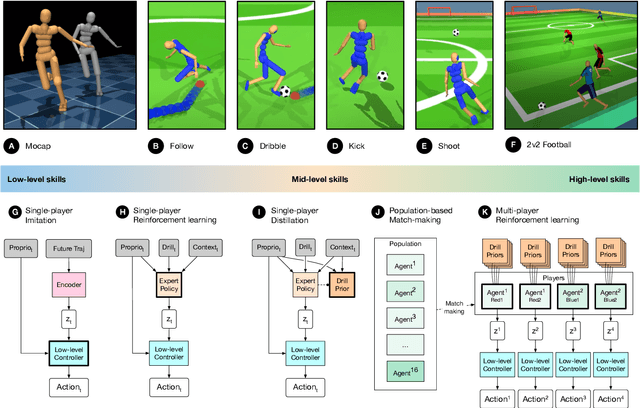

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Deep reinforcement learning models the emergent dynamics of human cooperation
Mar 08, 2021


Collective action demands that individuals efficiently coordinate how much, where, and when to cooperate. Laboratory experiments have extensively explored the first part of this process, demonstrating that a variety of social-cognitive mechanisms influence how much individuals choose to invest in group efforts. However, experimental research has been unable to shed light on how social cognitive mechanisms contribute to the where and when of collective action. We leverage multi-agent deep reinforcement learning to model how a social-cognitive mechanism--specifically, the intrinsic motivation to achieve a good reputation--steers group behavior toward specific spatial and temporal strategies for collective action in a social dilemma. We also collect behavioral data from groups of human participants challenged with the same dilemma. The model accurately predicts spatial and temporal patterns of group behavior: in this public goods dilemma, the intrinsic motivation for reputation catalyzes the development of a non-territorial, turn-taking strategy to coordinate collective action.
EigenGame Unloaded: When playing games is better than optimizing
Feb 08, 2021



We build on the recently proposed EigenGame that views eigendecomposition as a competitive game. EigenGame's updates are biased if computed using minibatches of data, which hinders convergence and more sophisticated parallelism in the stochastic setting. In this work, we propose an unbiased stochastic update that is asymptotically equivalent to EigenGame, enjoys greater parallelism allowing computation on datasets of larger sample sizes, and outperforms EigenGame in experiments. We present applications to finding the principal components of massive datasets and performing spectral clustering of graphs. We analyze and discuss our proposed update in the context of EigenGame and the shift in perspective from optimization to games.