 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity Through Exclusion (DTE): Niche Identification for Reinforcement Learning through Value-Decomposition
Feb 03, 2023



Many environments contain numerous available niches of variable value, each associated with a different local optimum in the space of behaviors (policy space). In such situations it is often difficult to design a learning process capable of evading distraction by poor local optima long enough to stumble upon the best available niche. In this work we propose a generic reinforcement learning (RL) algorithm that performs better than baseline deep Q-learning algorithms in such environments with multiple variably-valued niches. The algorithm we propose consists of two parts: an agent architecture and a learning rule. The agent architecture contains multiple sub-policies. The learning rule is inspired by fitness sharing in evolutionary computation and applied in reinforcement learning using Value-Decomposition-Networks in a novel manner for a single-agent's internal population. It can concretely be understood as adding an extra loss term where one policy's experience is also used to update all the other policies in a manner that decreases their value estimates for the visited states. In particular, when one sub-policy visits a particular state frequently this decreases the value predicted for other sub-policies for going to that state. Further, we introduce an artificial chemistry inspired platform where it is easy to create tasks with multiple rewarding strategies utilizing different resources (i.e. multiple niches). We show that agents trained this way can escape poor-but-attractive local optima to instead converge to harder-to-discover higher value strategies in both the artificial chemistry environments and in simpler illustrative environments.
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Jul 14, 2021
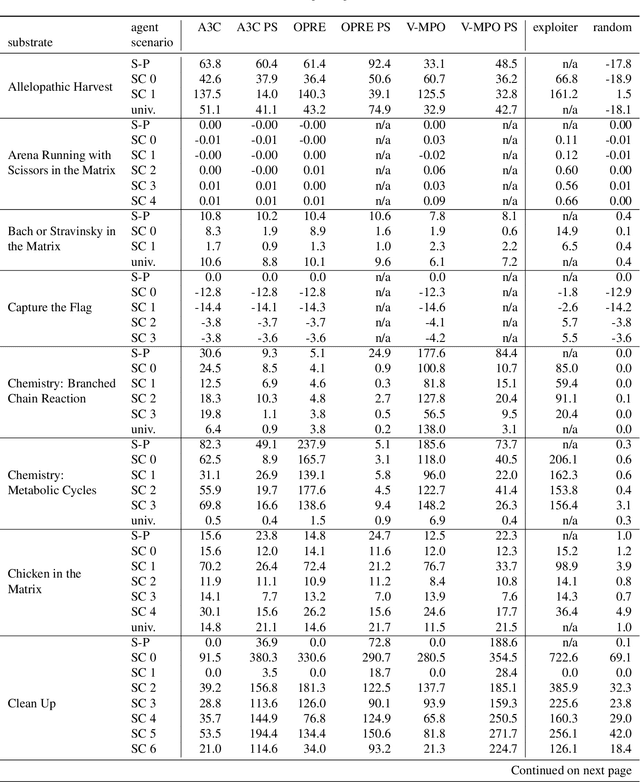
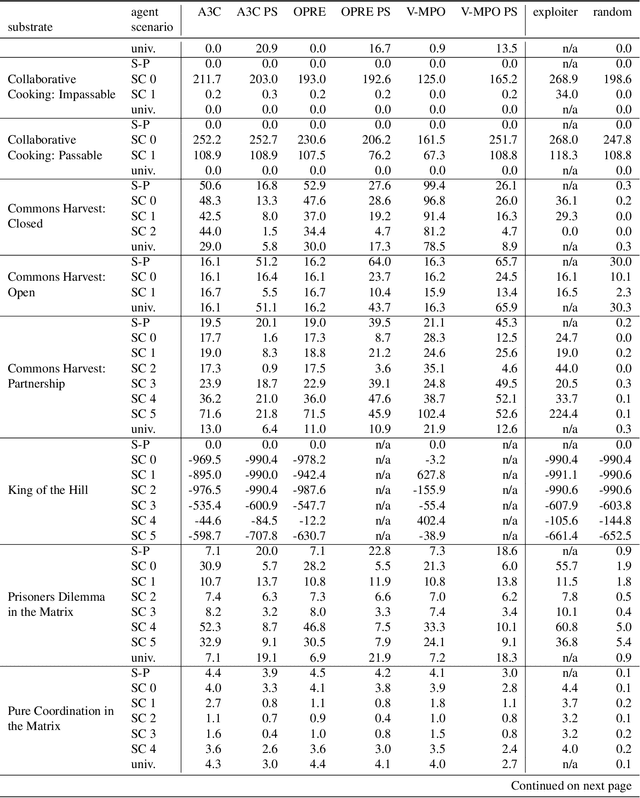
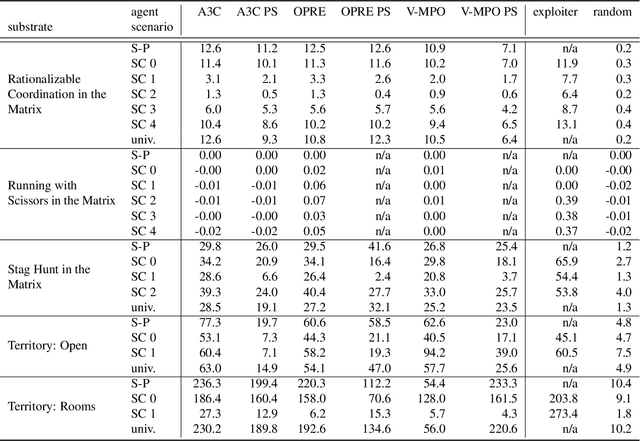
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
* Accepted to ICML 2021 and presented as a long talk; 33 pages; 9 figures
Malthusian Reinforcement Learning
Dec 17, 2018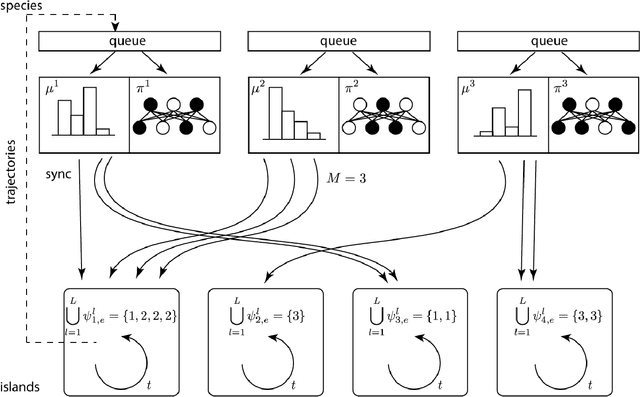
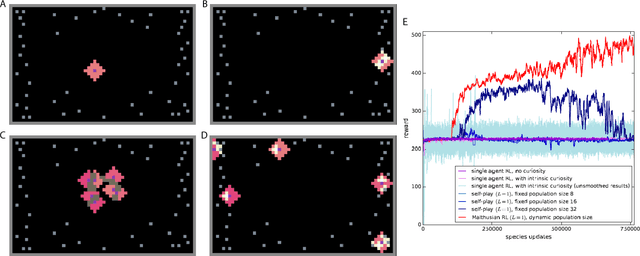
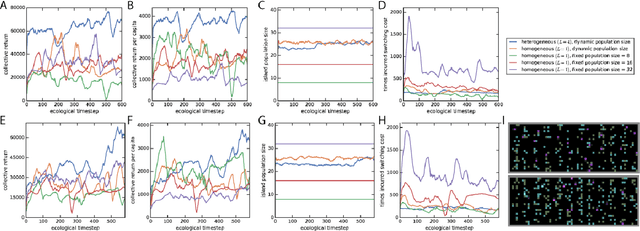
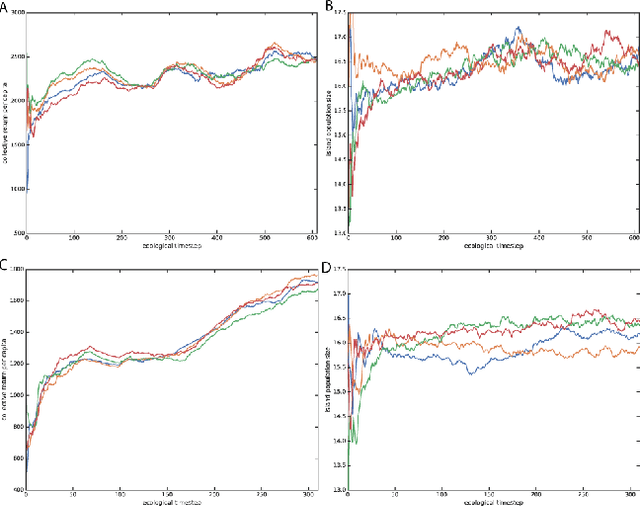
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.