 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity Through Exclusion (DTE): Niche Identification for Reinforcement Learning through Value-Decomposition
Feb 03, 2023



Many environments contain numerous available niches of variable value, each associated with a different local optimum in the space of behaviors (policy space). In such situations it is often difficult to design a learning process capable of evading distraction by poor local optima long enough to stumble upon the best available niche. In this work we propose a generic reinforcement learning (RL) algorithm that performs better than baseline deep Q-learning algorithms in such environments with multiple variably-valued niches. The algorithm we propose consists of two parts: an agent architecture and a learning rule. The agent architecture contains multiple sub-policies. The learning rule is inspired by fitness sharing in evolutionary computation and applied in reinforcement learning using Value-Decomposition-Networks in a novel manner for a single-agent's internal population. It can concretely be understood as adding an extra loss term where one policy's experience is also used to update all the other policies in a manner that decreases their value estimates for the visited states. In particular, when one sub-policy visits a particular state frequently this decreases the value predicted for other sub-policies for going to that state. Further, we introduce an artificial chemistry inspired platform where it is easy to create tasks with multiple rewarding strategies utilizing different resources (i.e. multiple niches). We show that agents trained this way can escape poor-but-attractive local optima to instead converge to harder-to-discover higher value strategies in both the artificial chemistry environments and in simpler illustrative environments.
Neural MMO v1.3: A Massively Multiagent Game Environment for Training and Evaluating Neural Networks
Jan 31, 2020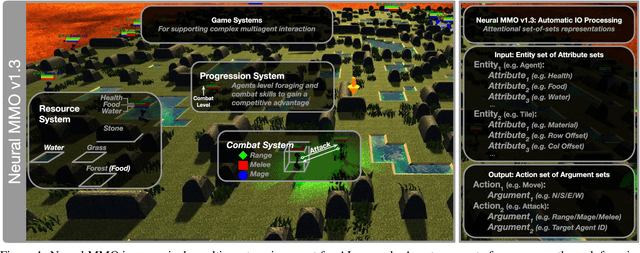
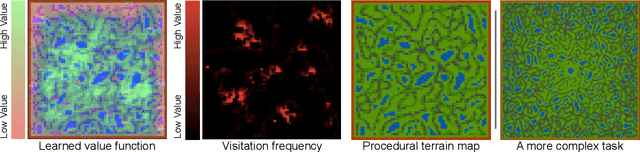
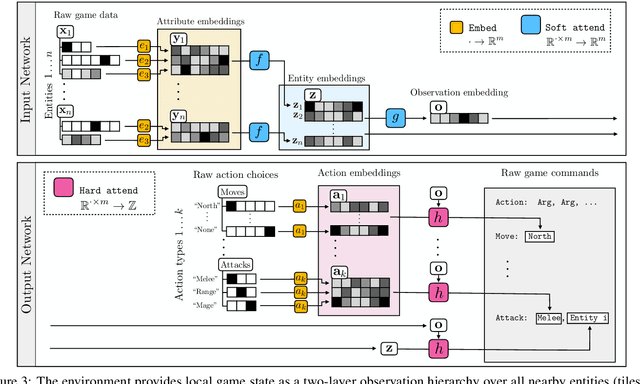
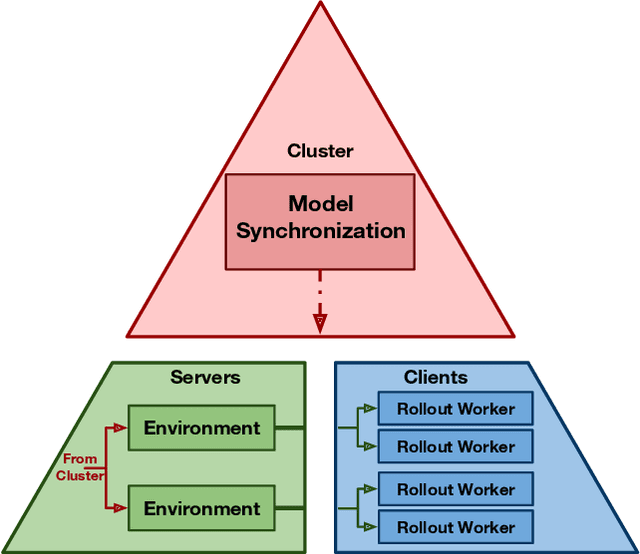
Progress in multiagent intelligence research is fundamentally limited by the number and quality of environments available for study. In recent years, simulated games have become a dominant research platform within reinforcement learning, in part due to their accessibility and interpretability. Previous works have targeted and demonstrated success on arcade, first person shooter (FPS), real-time strategy (RTS), and massive online battle arena (MOBA) games. Our work considers massively multiplayer online role-playing games (MMORPGs or MMOs), which capture several complexities of real-world learning that are not well modeled by any other game genre. We present Neural MMO, a massively multiagent game environment inspired by MMOs and discuss our progress on two more general challenges in multiagent systems engineering for AI research: distributed infrastructure and game IO. We further demonstrate that standard policy gradient methods and simple baseline models can learn interesting emergent exploration and specialization behaviors in this setting.