 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePufferLib: Making Reinforcement Learning Libraries and Environments Play Nice
Jun 11, 2024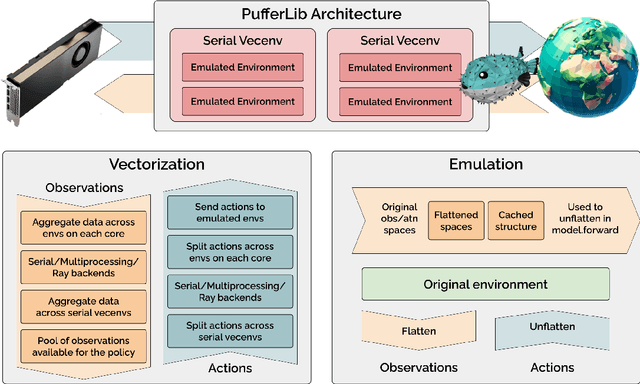
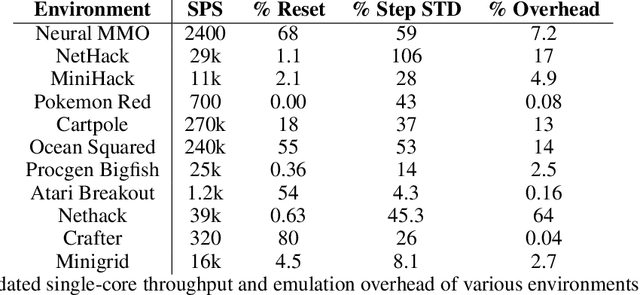

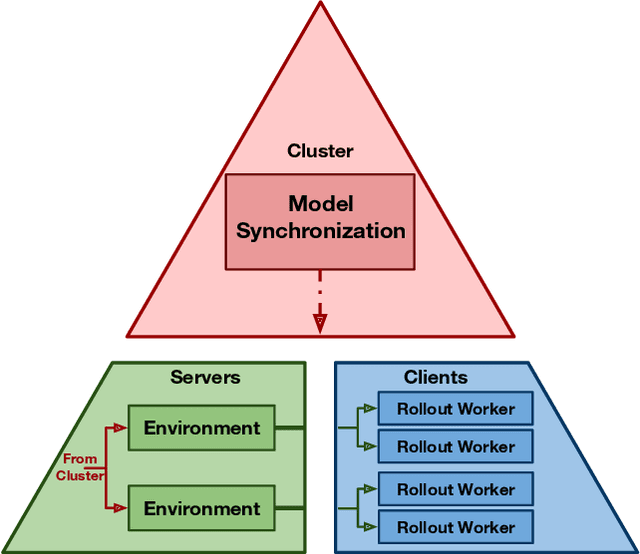
You have an environment, a model, and a reinforcement learning library that are designed to work together but don't. PufferLib makes them play nice. The library provides one-line environment wrappers that eliminate common compatibility problems and fast vectorization to accelerate training. With PufferLib, you can use familiar libraries like CleanRL and SB3 to scale from classic benchmarks like Atari and Procgen to complex simulators like NetHack and Neural MMO. We release pip packages and prebuilt images with dependencies for dozens of environments. All of our code is free and open-source software under the MIT license, complete with baselines, documentation, and support at pufferai.github.io.
The NeurIPS 2022 Neural MMO Challenge: A Massively Multiagent Competition with Specialization and Trade
Nov 07, 2023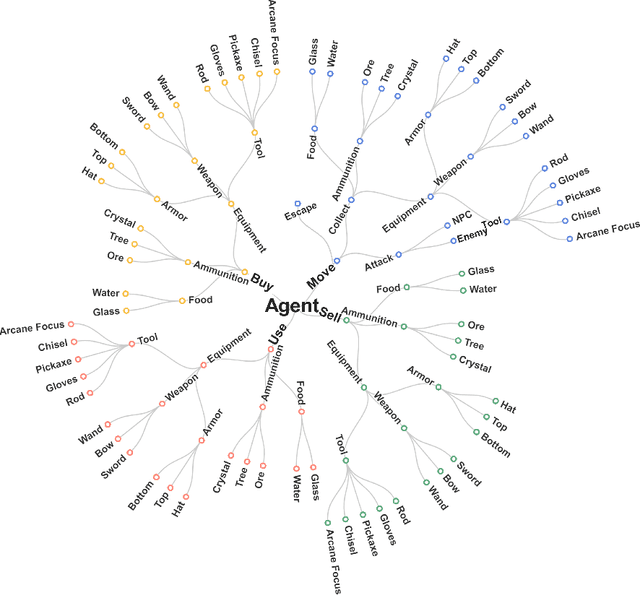



In this paper, we present the results of the NeurIPS-2022 Neural MMO Challenge, which attracted 500 participants and received over 1,600 submissions. Like the previous IJCAI-2022 Neural MMO Challenge, it involved agents from 16 populations surviving in procedurally generated worlds by collecting resources and defeating opponents. This year's competition runs on the latest v1.6 Neural MMO, which introduces new equipment, combat, trading, and a better scoring system. These elements combine to pose additional robustness and generalization challenges not present in previous competitions. This paper summarizes the design and results of the challenge, explores the potential of this environment as a benchmark for learning methods, and presents some practical reinforcement learning training approaches for complex tasks with sparse rewards. Additionally, we have open-sourced our baselines, including environment wrappers, benchmarks, and visualization tools for future research.
Reward Scale Robustness for Proximal Policy Optimization via DreamerV3 Tricks
Oct 26, 2023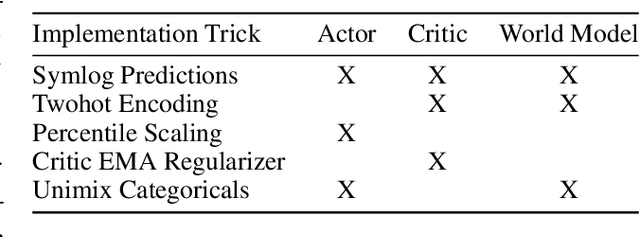
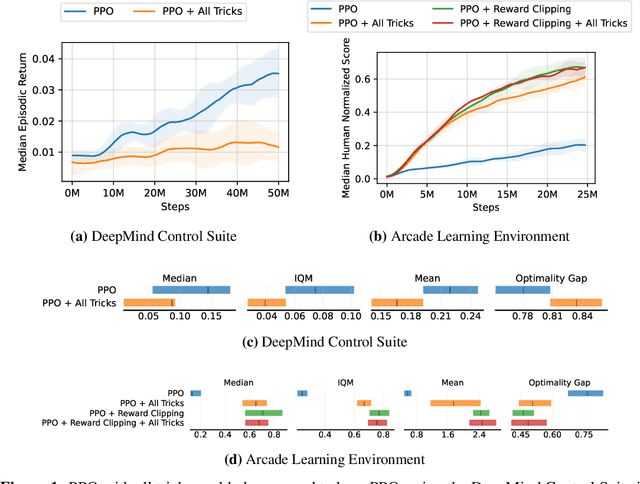
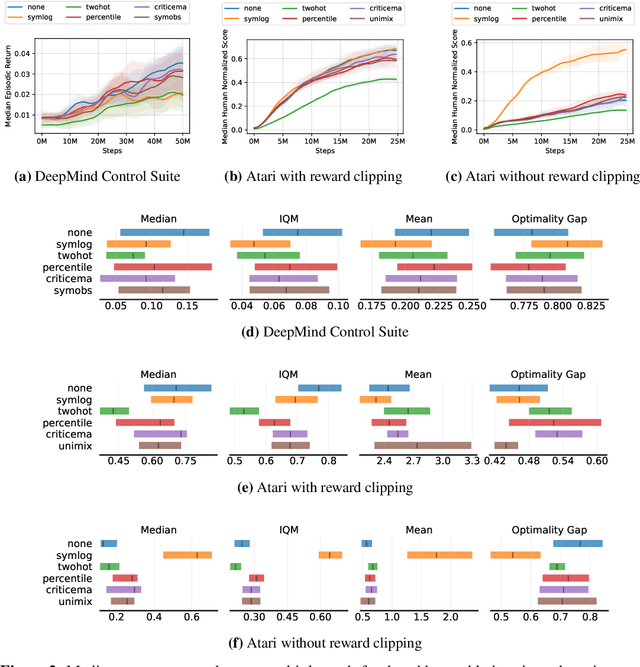
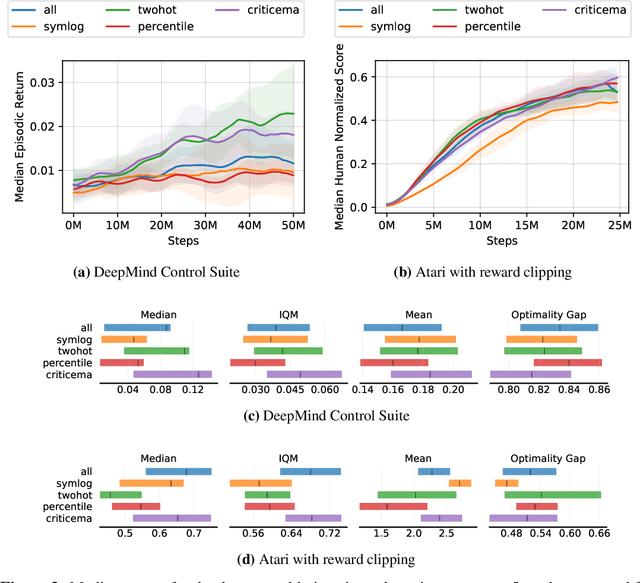
Most reinforcement learning methods rely heavily on dense, well-normalized environment rewards. DreamerV3 recently introduced a model-based method with a number of tricks that mitigate these limitations, achieving state-of-the-art on a wide range of benchmarks with a single set of hyperparameters. This result sparked discussion about the generality of the tricks, since they appear to be applicable to other reinforcement learning algorithms. Our work applies DreamerV3's tricks to PPO and is the first such empirical study outside of the original work. Surprisingly, we find that the tricks presented do not transfer as general improvements to PPO. We use a high quality PPO reference implementation and present extensive ablation studies totaling over 10,000 A100 hours on the Arcade Learning Environment and the DeepMind Control Suite. Though our experiments demonstrate that these tricks do not generally outperform PPO, we identify cases where they succeed and offer insight into the relationship between the implementation tricks. In particular, PPO with these tricks performs comparably to PPO on Atari games with reward clipping and significantly outperforms PPO without reward clipping.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

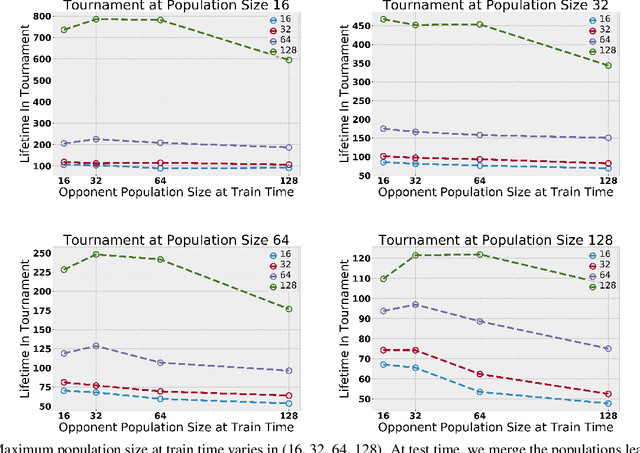
We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
The Neural MMO Platform for Massively Multiagent Research
Oct 14, 2021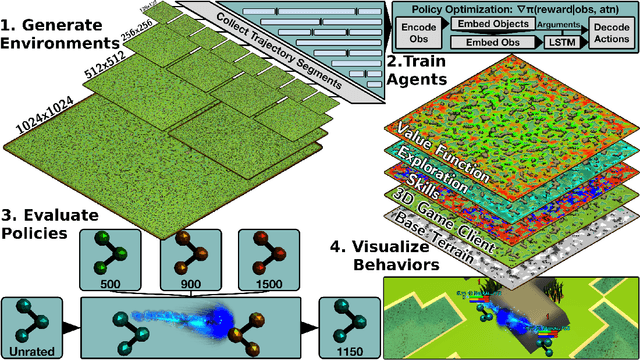
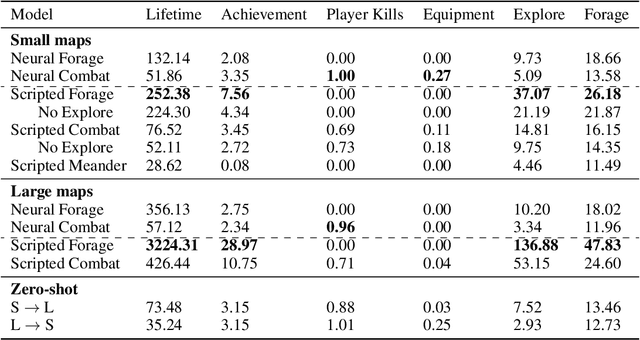

Neural MMO is a computationally accessible research platform that combines large agent populations, long time horizons, open-ended tasks, and modular game systems. Existing environments feature subsets of these properties, but Neural MMO is the first to combine them all. We present Neural MMO as free and open source software with active support, ongoing development, documentation, and additional training, logging, and visualization tools to help users adapt to this new setting. Initial baselines on the platform demonstrate that agents trained in large populations explore more and learn a progression of skills. We raise other more difficult problems such as many-team cooperation as open research questions which Neural MMO is well-suited to answer. Finally, we discuss current limitations of the platform, potential mitigations, and plans for continued development.
Neural MMO v1.3: A Massively Multiagent Game Environment for Training and Evaluating Neural Networks
Jan 31, 2020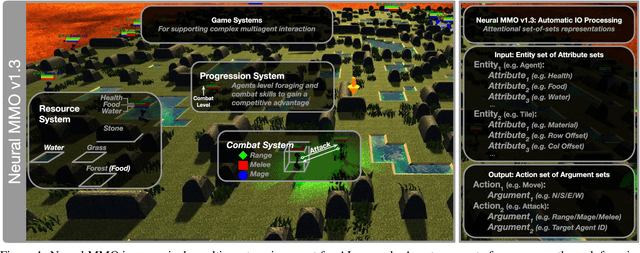
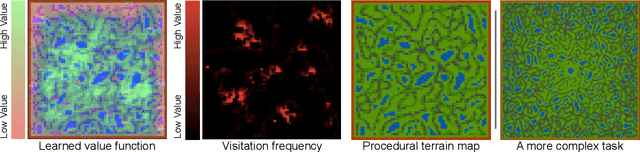
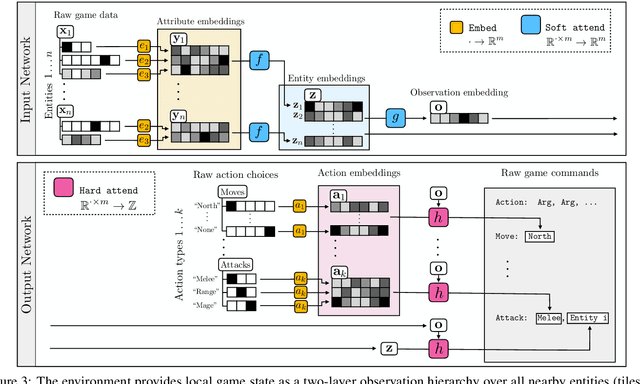
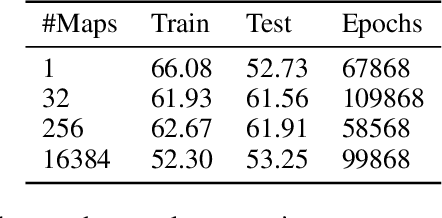
Progress in multiagent intelligence research is fundamentally limited by the number and quality of environments available for study. In recent years, simulated games have become a dominant research platform within reinforcement learning, in part due to their accessibility and interpretability. Previous works have targeted and demonstrated success on arcade, first person shooter (FPS), real-time strategy (RTS), and massive online battle arena (MOBA) games. Our work considers massively multiplayer online role-playing games (MMORPGs or MMOs), which capture several complexities of real-world learning that are not well modeled by any other game genre. We present Neural MMO, a massively multiagent game environment inspired by MMOs and discuss our progress on two more general challenges in multiagent systems engineering for AI research: distributed infrastructure and game IO. We further demonstrate that standard policy gradient methods and simple baseline models can learn interesting emergent exploration and specialization behaviors in this setting.
GAN You Do the GAN GAN?
Apr 01, 2019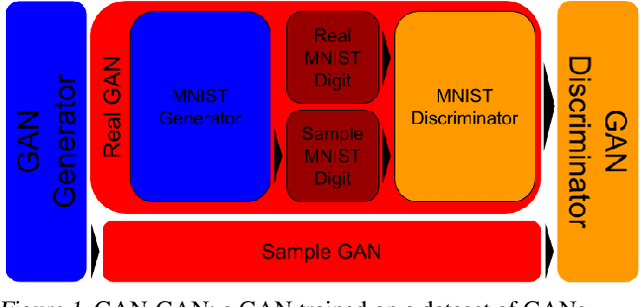
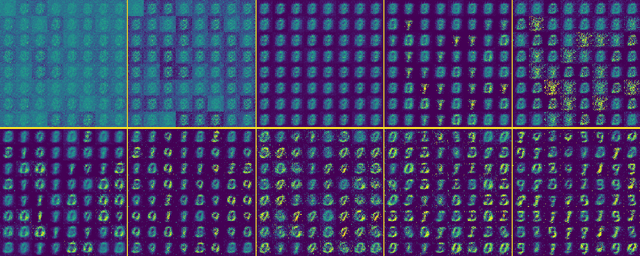

Generative Adversarial Networks (GANs) have become a dominant class of generative models. In recent years, GAN variants have yielded especially impressive results in the synthesis of a variety of forms of data. Examples include compelling natural and artistic images, textures, musical sequences, and 3D object files. However, one obvious synthesis candidate is missing. In this work, we answer one of deep learning's most pressing questions: GAN you do the GAN GAN? That is, is it possible to train a GAN to model a distribution of GANs? We release the full source code for this project under the MIT license.
Neural MMO: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents
Mar 02, 2019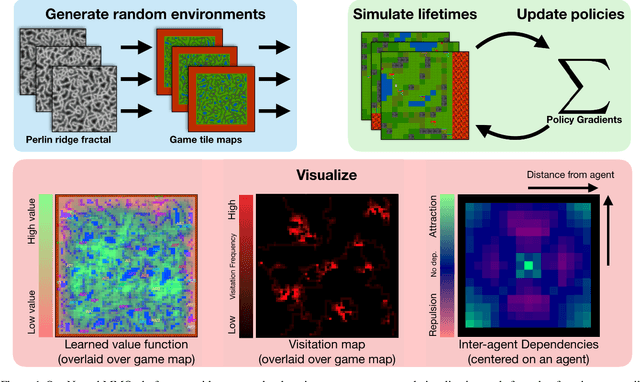


The emergence of complex life on Earth is often attributed to the arms race that ensued from a huge number of organisms all competing for finite resources. We present an artificial intelligence research environment, inspired by the human game genre of MMORPGs (Massively Multiplayer Online Role-Playing Games, a.k.a. MMOs), that aims to simulate this setting in microcosm. As with MMORPGs and the real world alike, our environment is persistent and supports a large and variable number of agents. Our environment is well suited to the study of large-scale multiagent interaction: it requires that agents learn robust combat and navigation policies in the presence of large populations attempting to do the same. Baseline experiments reveal that population size magnifies and incentivizes the development of skillful behaviors and results in agents that outcompete agents trained in smaller populations. We further show that the policies of agents with unshared weights naturally diverge to fill different niches in order to avoid competition.
DDRprog: A CLEVR Differentiable Dynamic Reasoning Programmer
Mar 30, 2018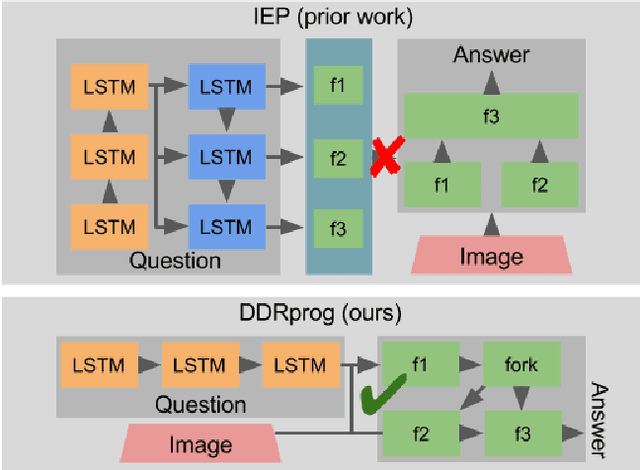
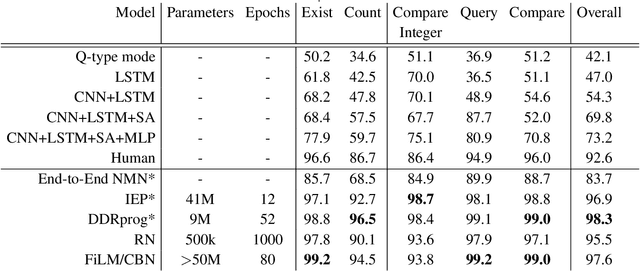
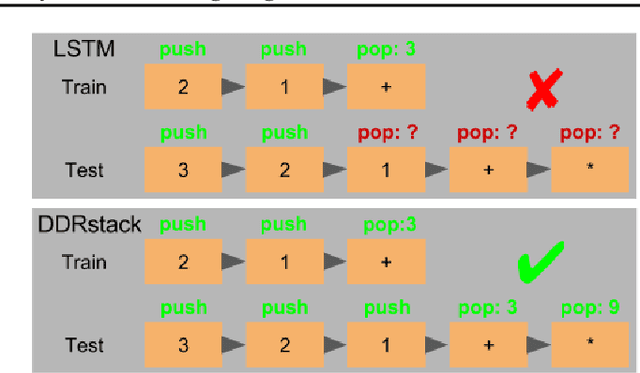
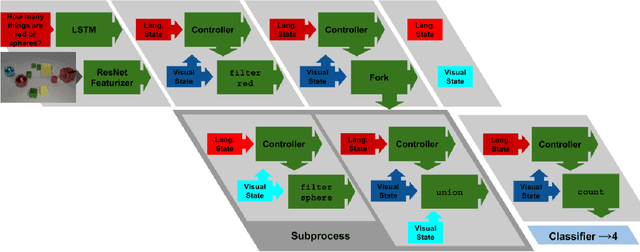
We present a novel Dynamic Differentiable Reasoning (DDR) framework for jointly learning branching programs and the functions composing them; this resolves a significant nondifferentiability inhibiting recent dynamic architectures. We apply our framework to two settings in two highly compact and data efficient architectures: DDRprog for CLEVR Visual Question Answering and DDRstack for reverse Polish notation expression evaluation. DDRprog uses a recurrent controller to jointly predict and execute modular neural programs that directly correspond to the underlying question logic; it explicitly forks subprocesses to handle logical branching. By effectively leveraging additional structural supervision, we achieve a large improvement over previous approaches in subtask consistency and a small improvement in overall accuracy. We further demonstrate the benefits of structural supervision in the RPN setting: the inclusion of a stack assumption in DDRstack allows our approach to generalize to long expressions where an LSTM fails the task.
Effective Approaches to Batch Parallelization for Dynamic Neural Network Architectures
Jul 08, 2017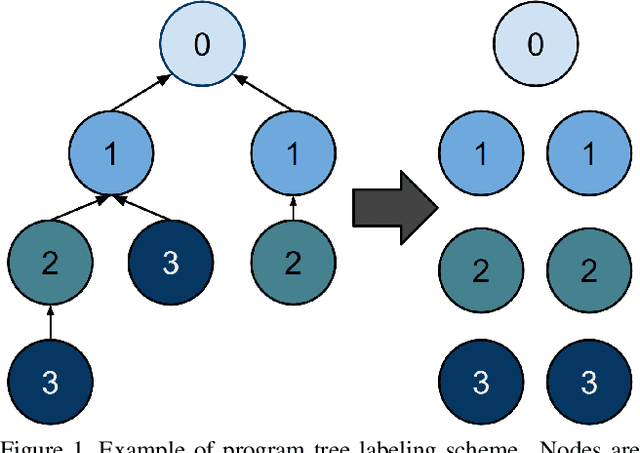
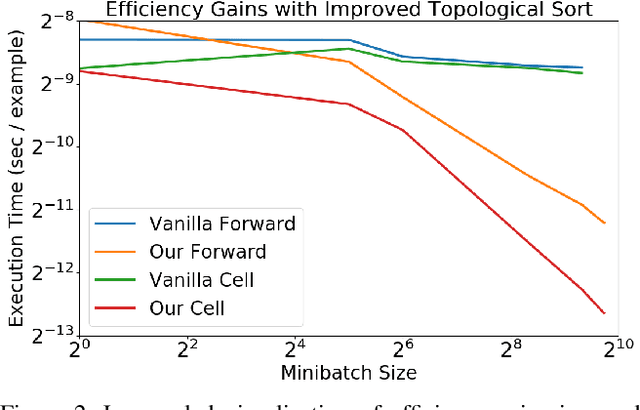
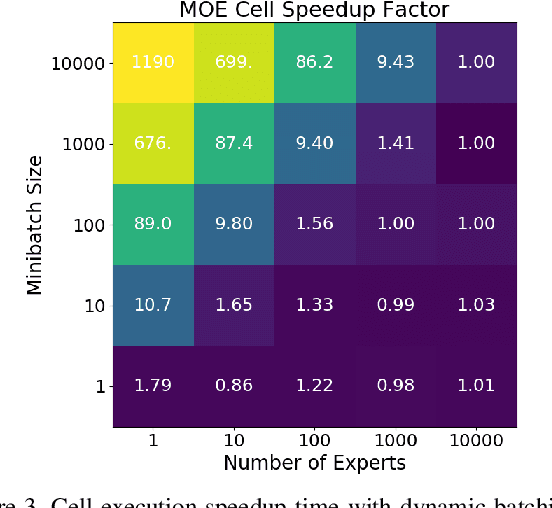
We present a simple dynamic batching approach applicable to a large class of dynamic architectures that consistently yields speedups of over 10x. We provide performance bounds when the architecture is not known a priori and a stronger bound in the special case where the architecture is a predetermined balanced tree. We evaluate our approach on Johnson et al.'s recent visual question answering (VQA) result of his CLEVR dataset by Inferring and Executing Programs (IEP). We also evaluate on sparsely gated mixture of experts layers and achieve speedups of up to 1000x over the naive implementation.