 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr Genre: Reinforcement Learning from Decoupled LLM Feedback for Generic Text Rewriting
Mar 09, 2025Generic text rewriting is a prevalent large language model (LLM) application that covers diverse real-world tasks, such as style transfer, fact correction, and email editing. These tasks vary in rewriting objectives (e.g., factual consistency vs. semantic preservation), making it challenging to develop a unified model that excels across all dimensions. Existing methods often specialize in either a single task or a specific objective, limiting their generalizability. In this work, we introduce a generic model proficient in factuality, stylistic, and conversational rewriting tasks. To simulate real-world user rewrite requests, we construct a conversational rewrite dataset, ChatRewrite, that presents ``natural''-sounding instructions, from raw emails using LLMs. Combined with other popular rewrite datasets, including LongFact for the factuality rewrite task and RewriteLM for the stylistic rewrite task, this forms a broad benchmark for training and evaluating generic rewrite models. To align with task-specific objectives, we propose Dr Genre, a Decoupled-reward learning framework for Generic rewriting, that utilizes objective-oriented reward models with a task-specific weighting. Evaluation shows that \approach delivers higher-quality rewrites across all targeted tasks, improving objectives including instruction following (agreement), internal consistency (coherence), and minimal unnecessary edits (conciseness).
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Knowledge Prompts: Injecting World Knowledge into Language Models through Soft Prompts
Oct 10, 2022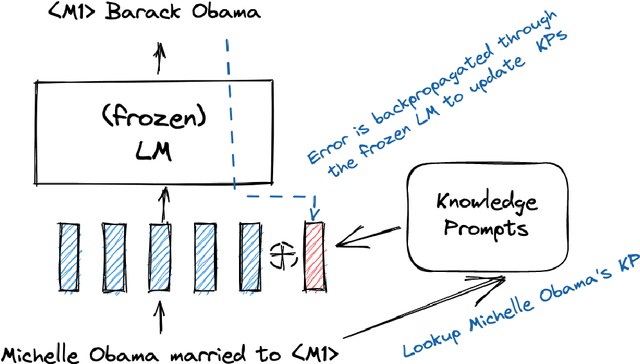


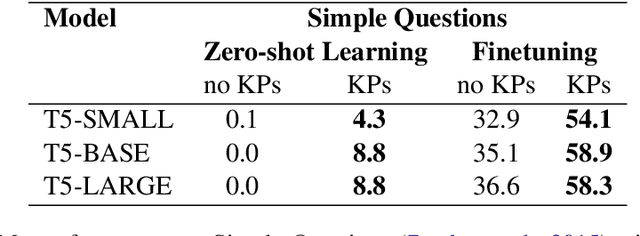
Soft prompts have been recently proposed as a tool for adapting large frozen language models (LMs) to new tasks. In this work, we repurpose soft prompts to the task of injecting world knowledge into LMs. We introduce a method to train soft prompts via self-supervised learning on data from knowledge bases. The resulting soft knowledge prompts (KPs) are task independent and work as an external memory of the LMs. We perform qualitative and quantitative experiments and demonstrate that: (1) KPs can effectively model the structure of the training data; (2) KPs can be used to improve the performance of LMs in different knowledge intensive tasks.