 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data
Feb 04, 2026Achieving generalizable manipulation in unconstrained environments requires the robot to proactively resolve information uncertainty, i.e., the capability of active perception. However, existing methods are often confined in limited types of sensing behaviors, restricting their applicability to complex environments. In this work, we formalize active perception as a non-Markovian process driven by information gain and decision branching, providing a structured categorization of visual active perception paradigms. Building on this perspective, we introduce CoMe-VLA, a cognitive and memory-aware vision-language-action (VLA) framework that leverages large-scale human egocentric data to learn versatile exploration and manipulation priors. Our framework integrates a cognitive auxiliary head for autonomous sub-task transitions and a dual-track memory system to maintain consistent self and environmental awareness by fusing proprioceptive and visual temporal contexts. By aligning human and robot hand-eye coordination behaviors in a unified egocentric action space, we train the model progressively in three stages. Extensive experiments on a wheel-based humanoid have demonstrated strong robustness and adaptability of our proposed method across diverse long-horizon tasks spanning multiple active perception scenarios.
Behavior Tokens Speak Louder: Disentangled Explainable Recommendation with Behavior Vocabulary
Dec 17, 2025
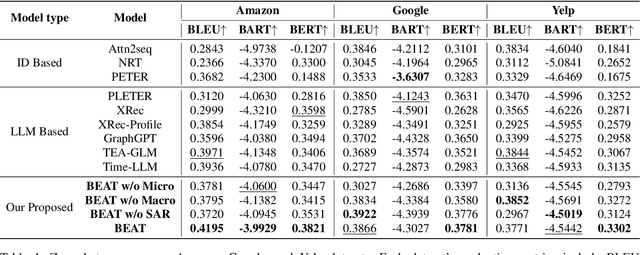


Recent advances in explainable recommendations have explored the integration of language models to analyze natural language rationales for user-item interactions. Despite their potential, existing methods often rely on ID-based representations that obscure semantic meaning and impose structural constraints on language models, thereby limiting their applicability in open-ended scenarios. These challenges are intensified by the complex nature of real-world interactions, where diverse user intents are entangled and collaborative signals rarely align with linguistic semantics. To overcome these limitations, we propose BEAT, a unified and transferable framework that tokenizes user and item behaviors into discrete, interpretable sequences. We construct a behavior vocabulary via a vector-quantized autoencoding process that disentangles macro-level interests and micro-level intentions from graph-based representations. We then introduce multi-level semantic supervision to bridge the gap between behavioral signals and language space. A semantic alignment regularization mechanism is designed to embed behavior tokens directly into the input space of frozen language models. Experiments on three public datasets show that BEAT improves zero-shot recommendation performance while generating coherent and informative explanations. Further analysis demonstrates that our behavior tokens capture fine-grained semantics and offer a plug-and-play interface for integrating complex behavior patterns into large language models.
Dr Genre: Reinforcement Learning from Decoupled LLM Feedback for Generic Text Rewriting
Mar 09, 2025Generic text rewriting is a prevalent large language model (LLM) application that covers diverse real-world tasks, such as style transfer, fact correction, and email editing. These tasks vary in rewriting objectives (e.g., factual consistency vs. semantic preservation), making it challenging to develop a unified model that excels across all dimensions. Existing methods often specialize in either a single task or a specific objective, limiting their generalizability. In this work, we introduce a generic model proficient in factuality, stylistic, and conversational rewriting tasks. To simulate real-world user rewrite requests, we construct a conversational rewrite dataset, ChatRewrite, that presents ``natural''-sounding instructions, from raw emails using LLMs. Combined with other popular rewrite datasets, including LongFact for the factuality rewrite task and RewriteLM for the stylistic rewrite task, this forms a broad benchmark for training and evaluating generic rewrite models. To align with task-specific objectives, we propose Dr Genre, a Decoupled-reward learning framework for Generic rewriting, that utilizes objective-oriented reward models with a task-specific weighting. Evaluation shows that \approach delivers higher-quality rewrites across all targeted tasks, improving objectives including instruction following (agreement), internal consistency (coherence), and minimal unnecessary edits (conciseness).