 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data
Feb 04, 2026Achieving generalizable manipulation in unconstrained environments requires the robot to proactively resolve information uncertainty, i.e., the capability of active perception. However, existing methods are often confined in limited types of sensing behaviors, restricting their applicability to complex environments. In this work, we formalize active perception as a non-Markovian process driven by information gain and decision branching, providing a structured categorization of visual active perception paradigms. Building on this perspective, we introduce CoMe-VLA, a cognitive and memory-aware vision-language-action (VLA) framework that leverages large-scale human egocentric data to learn versatile exploration and manipulation priors. Our framework integrates a cognitive auxiliary head for autonomous sub-task transitions and a dual-track memory system to maintain consistent self and environmental awareness by fusing proprioceptive and visual temporal contexts. By aligning human and robot hand-eye coordination behaviors in a unified egocentric action space, we train the model progressively in three stages. Extensive experiments on a wheel-based humanoid have demonstrated strong robustness and adaptability of our proposed method across diverse long-horizon tasks spanning multiple active perception scenarios.
Player-Centric Multimodal Prompt Generation for Large Language Model Based Identity-Aware Basketball Video Captioning
Jul 27, 2025Existing sports video captioning methods often focus on the action yet overlook player identities, limiting their applicability. Although some methods integrate extra information to generate identity-aware descriptions, the player identities are sometimes incorrect because the extra information is independent of the video content. This paper proposes a player-centric multimodal prompt generation network for identity-aware sports video captioning (LLM-IAVC), which focuses on recognizing player identities from a visual perspective. Specifically, an identity-related information extraction module (IRIEM) is designed to extract player-related multimodal embeddings. IRIEM includes a player identification network (PIN) for extracting visual features and player names, and a bidirectional semantic interaction module (BSIM) to link player features with video content for mutual enhancement. Additionally, a visual context learning module (VCLM) is designed to capture the key video context information. Finally, by integrating the outputs of the above modules as the multimodal prompt for the large language model (LLM), it facilitates the generation of descriptions with player identities. To support this work, we construct a new benchmark called NBA-Identity, a large identity-aware basketball video captioning dataset with 9,726 videos covering 9 major event types. The experimental results on NBA-Identity and VC-NBA-2022 demonstrate that our proposed model achieves advanced performance. Code and dataset are publicly available at https://github.com/Zeyu1226-mt/LLM-IAVC.
Prohibited Items Segmentation via Occlusion-aware Bilayer Modeling
Jun 13, 2025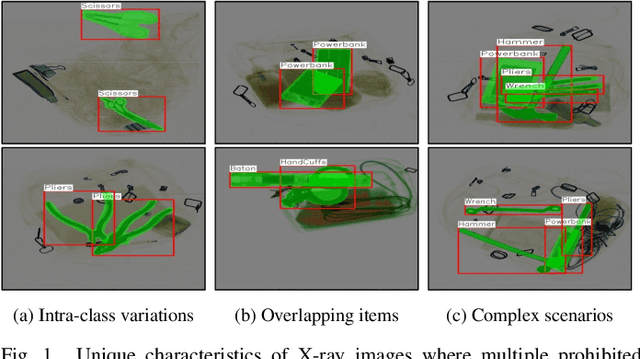
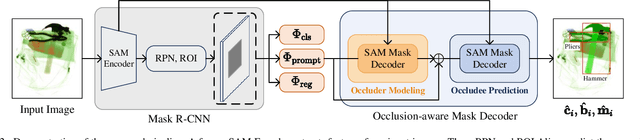
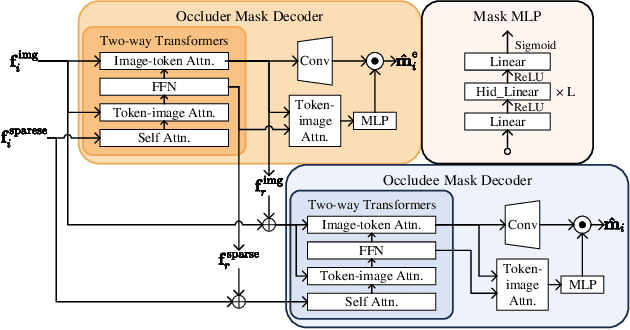

Instance segmentation of prohibited items in security X-ray images is a critical yet challenging task. This is mainly caused by the significant appearance gap between prohibited items in X-ray images and natural objects, as well as the severe overlapping among objects in X-ray images. To address these issues, we propose an occlusion-aware instance segmentation pipeline designed to identify prohibited items in X-ray images. Specifically, to bridge the representation gap, we integrate the Segment Anything Model (SAM) into our pipeline, taking advantage of its rich priors and zero-shot generalization capabilities. To address the overlap between prohibited items, we design an occlusion-aware bilayer mask decoder module that explicitly models the occlusion relationships. To supervise occlusion estimation, we manually annotated occlusion areas of prohibited items in two large-scale X-ray image segmentation datasets, PIDray and PIXray. We then reorganized these additional annotations together with the original information as two occlusion-annotated datasets, PIDray-A and PIXray-A. Extensive experimental results on these occlusion-annotated datasets demonstrate the effectiveness of our proposed method. The datasets and codes are available at: https://github.com/Ryh1218/Occ
LongCaptioning: Unlocking the Power of Long Caption Generation in Large Multimodal Models
Feb 21, 2025Large multimodal models (LMMs) have shown remarkable performance in video understanding tasks and can even process videos longer than one hour. However, despite their ability to handle long inputs, generating outputs with corresponding levels of richness remains a challenge. In this paper, we explore the issue of long outputs in LMMs using video captioning as a proxy task, and we find that open-source LMMs struggle to consistently generate outputs exceeding about 300 words. Through controlled experiments, we find that the scarcity of paired examples with long-captions during training is the primary factor limiting the model's output length. However, manually annotating long-caption examples is time-consuming and expensive. To address this, we propose the LongCaption-Agent, a framework that synthesizes long caption data by aggregating multi-level descriptions. Using LongCaption-Agent, we curated a new long-caption dataset, LongCaption-10K. We also develop LongCaption-Bench, a benchmark designed to comprehensively evaluate the quality of long captions generated by LMMs. By incorporating LongCaption-10K into training, we enable LMMs to generate captions exceeding 1,000 words, while maintaining high output quality. In LongCaption-Bench, our 8B parameter model achieved state-of-the-art performance, even surpassing larger proprietary models. We will release the dataset and code after publication.
Multimodal LLMs Can Reason about Aesthetics in Zero-Shot
Jan 15, 2025We present the first study on how Multimodal LLMs' (MLLMs) reasoning ability shall be elicited to evaluate the aesthetics of artworks. To facilitate this investigation, we construct MM-StyleBench, a novel high-quality dataset for benchmarking artistic stylization. We then develop a principled method for human preference modeling and perform a systematic correlation analysis between MLLMs' responses and human preference. Our experiments reveal an inherent hallucination issue of MLLMs in art evaluation, associated with response subjectivity. ArtCoT is proposed, demonstrating that art-specific task decomposition and the use of concrete language boost MLLMs' reasoning ability for aesthetics. Our findings offer valuable insights into MLLMs for art and can benefit a wide range of downstream applications, such as style transfer and artistic image generation. Code available at https://github.com/songrise/MLLM4Art.
Artist: Aesthetically Controllable Text-Driven Stylization without Training
Jul 22, 2024Diffusion models entangle content and style generation during the denoising process, leading to undesired content modification when directly applied to stylization tasks. Existing methods struggle to effectively control the diffusion model to meet the aesthetic-level requirements for stylization. In this paper, we introduce \textbf{Artist}, a training-free approach that aesthetically controls the content and style generation of a pretrained diffusion model for text-driven stylization. Our key insight is to disentangle the denoising of content and style into separate diffusion processes while sharing information between them. We propose simple yet effective content and style control methods that suppress style-irrelevant content generation, resulting in harmonious stylization results. Extensive experiments demonstrate that our method excels at achieving aesthetic-level stylization requirements, preserving intricate details in the content image and aligning well with the style prompt. Furthermore, we showcase the highly controllability of the stylization strength from various perspectives. Code will be released, project home page: https://DiffusionArtist.github.io
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
Mar 14, 2024Prompt-tuning has demonstrated parameter-efficiency in fusing unimodal foundation models for multimodal tasks. However, its limited adaptivity and expressiveness lead to suboptimal performance when compared with other tuning methods. In this paper, we address this issue by disentangling the vanilla prompts to adaptively capture dataset-level and instance-level features. Building upon this disentanglement, we introduce the mixture of prompt experts (MoPE) technique to enhance expressiveness. MoPE leverages multimodal pairing priors to route the most effective prompt on a per-instance basis. Compared to vanilla prompting, our MoPE-based conditional prompting exhibits greater expressiveness for multimodal fusion, scaling better with the training data and the overall number of trainable parameters. We also study a regularization term for expert routing, leading to emergent expert specialization, where different experts focus on different concepts, enabling interpretable soft prompting. Extensive experiments across three multimodal datasets demonstrate that our method achieves state-of-the-art results, matching or even surpassing the performance of fine-tuning, while requiring only 0.8% of the trainable parameters. Code will be released: https://github.com/songrise/MoPE.
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Dec 07, 2023Learning scene graphs from natural language descriptions has proven to be a cheap and promising scheme for Scene Graph Generation (SGG). However, such unstructured caption data and its processing are troubling the learning an acurrate and complete scene graph. This dilema can be summarized as three points. First, traditional language parsers often fail to extract meaningful relationship triplets from caption data. Second, grounding unlocalized objects in parsed triplets will meet ambiguity in visual-language alignment. Last, caption data typically are sparse and exhibit bias to partial observations of image content. These three issues make it hard for the model to generate comprehensive and accurate scene graphs. To fill this gap, we propose a simple yet effective framework, GPT4SGG, to synthesize scene graphs from holistic and region-specific narratives. The framework discards traditional language parser, and localize objects before obtaining relationship triplets. To obtain relationship triplets, holistic and dense region-specific narratives are generated from the image. With such textual representation of image data and a task-specific prompt, an LLM, particularly GPT-4, directly synthesizes a scene graph as "pseudo labels". Experimental results showcase GPT4SGG significantly improves the performance of SGG models trained on image-caption data. We believe this pioneering work can motivate further research into mining the visual reasoning capabilities of LLMs.
Conditional Prompt Tuning for Multimodal Fusion
Nov 28, 2023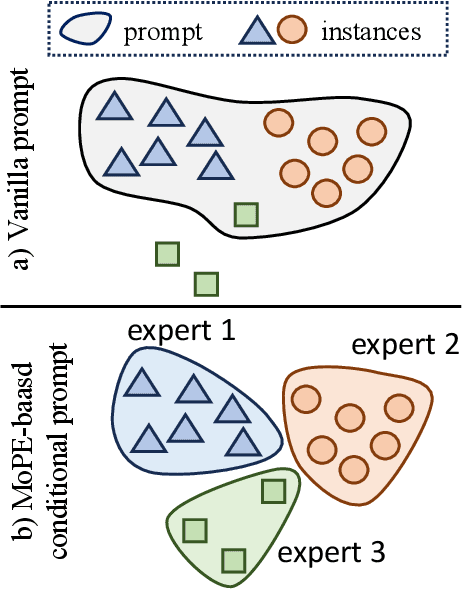
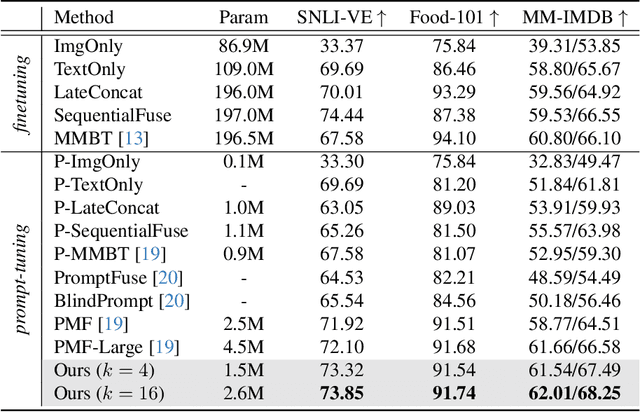
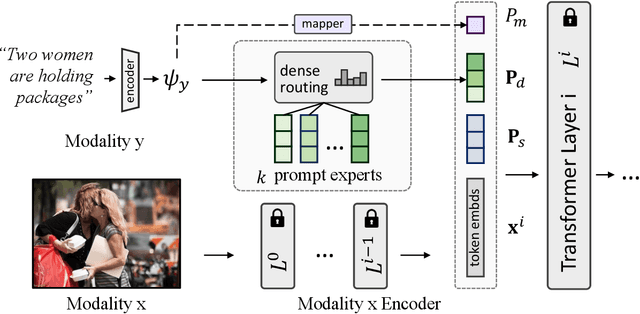
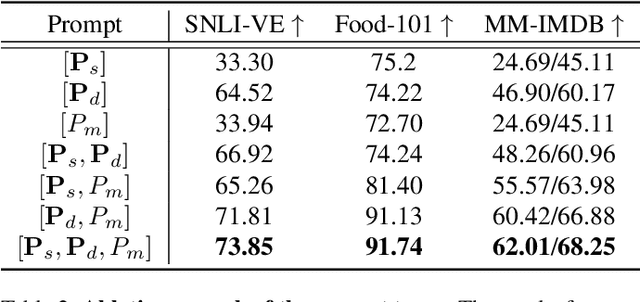
We show that the representation of one modality can effectively guide the prompting of another modality for parameter-efficient multimodal fusion. Specifically, we first encode one modality and use its representation as a prior to conditionally prompt all frozen layers of the other modality. This is achieved by disentangling the vanilla prompt vectors into three types of specialized prompts that adaptively capture global-level and instance-level features. To better produce the instance-wise prompt, we introduce the mixture of prompt experts (MoPE) to dynamically route each instance to the most suitable prompt experts for encoding. We further study a regularization term to avoid degenerated prompt expert routing. Thanks to our design, our method can effectively transfer the pretrained knowledge in unimodal encoders for downstream multimodal tasks. Compared with vanilla prompting, we show that our MoPE-based conditional prompting is more expressive, thereby scales better with training data and the total number of prompts. We also demonstrate that our prompt tuning is architecture-agnostic, thereby offering high modularity. Extensive experiments over three multimodal datasets demonstrate state-of-the-art results, matching or surpassing the performance achieved through fine-tuning, while only necessitating 0.7% of the trainable parameters. Code will be released: https://github.com/songrise/ConditionalPrompt.
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention
Nov 18, 2023Scene Graph Generation (SGG) offers a structured representation critical in many computer vision applications. Traditional SGG approaches, however, are limited by a closed-set assumption, restricting their ability to recognize only predefined object and relation categories. To overcome this, we categorize SGG scenarios into four distinct settings based on the node and edge: Closed-set SGG, Open Vocabulary (object) Detection-based SGG (OvD-SGG), Open Vocabulary Relation-based SGG (OvR-SGG), and Open Vocabulary Detection + Relation-based SGG (OvD+R-SGG). While object-centric open vocabulary SGG has been studied recently, the more challenging problem of relation-involved open-vocabulary SGG remains relatively unexplored. To fill this gap, we propose a unified framework named OvSGTR towards fully open vocabulary SGG from a holistic view. The proposed framework is an end-toend transformer architecture, which learns a visual-concept alignment for both nodes and edges, enabling the model to recognize unseen categories. For the more challenging settings of relation-involved open vocabulary SGG, the proposed approach integrates relation-aware pre-training utilizing image-caption data and retains visual-concept alignment through knowledge distillation. Comprehensive experimental results on the Visual Genome benchmark demonstrate the effectiveness and superiority of the proposed framework.