 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBefore the Shutter: Aesthetic and Actionable Portrait Photography Planning in 3D Scenes
May 28, 2026Portrait photography is largely decided before the shutter opens: the subject's pose, the camera configuration, and the lighting devices must be coordinated within the surrounding 3D scene. In contrast, most existing computational methods focus on post-production in 2D image space, such as retouching, relighting, or editing images that already exist; pre-capture photographic planning remains largely unexplored. We introduce 3D aesthetic portrait planning, the task of generating human pose, camera, lighting, and exposure plans that produce visually compelling portraits while satisfying geometric and photometric feasibility in a 3D scene. Our approach builds a Photographic Scene Graph that represents scene affordances, subject-scene relations, and portrait-relevant lighting structure. Built on this representation, we perform aesthetic-guided comparative planning over previous attempts and current viewfinder observations. Experiments across diverse indoor and outdoor scenes show that our method produces portraits preferred by human raters and MLLM evaluators over competitive baselines, while maintaining high physical plausibility. Together, our results suggest a path from post-capture correction toward pre-capture computational portrait planning. Project repository: https://github.com/songrise/Before-the-Shutter
On Semiotic-Grounded Interpretive Evaluation of Generative Art
Apr 09, 2026Interpretation is essential to deciphering the language of art: audiences communicate with artists by recovering meaning from visual artifacts. However, current Generative Art (GenArt) evaluators remain fixated on surface-level image quality or literal prompt adherence, failing to assess the deeper symbolic or abstract meaning intended by the creator. We address this gap by formalizing a Peircean computational semiotic theory that models Human-GenArt Interaction (HGI) as cascaded semiosis. This framework reveals that artistic meaning is conveyed through three modes - iconic, symbolic, and indexical - yet existing evaluators operate heavily within the iconic mode, remaining structurally blind to the latter two. To overcome this structural blindness, we propose SemJudge. This evaluator explicitly assesses symbolic and indexical meaning in HGI via a Hierarchical Semiosis Graph (HSG) that reconstructs the meaning-making process from prompt to generated artifact. Extensive quantitative experiments show that SemJudge aligns more closely with human judgments than prior evaluators on an interpretation-intensive fine-art benchmark. User studies further demonstrate that SemJudge produces deeper, more insightful artistic interpretations, thereby paving the way for GenArt to move beyond the generation of "pretty" images toward a medium capable of expressing complex human experience. Project page: https://github.com/songrise/SemJudge.
Multimodal LLMs Can Reason about Aesthetics in Zero-Shot
Jan 15, 2025We present the first study on how Multimodal LLMs' (MLLMs) reasoning ability shall be elicited to evaluate the aesthetics of artworks. To facilitate this investigation, we construct MM-StyleBench, a novel high-quality dataset for benchmarking artistic stylization. We then develop a principled method for human preference modeling and perform a systematic correlation analysis between MLLMs' responses and human preference. Our experiments reveal an inherent hallucination issue of MLLMs in art evaluation, associated with response subjectivity. ArtCoT is proposed, demonstrating that art-specific task decomposition and the use of concrete language boost MLLMs' reasoning ability for aesthetics. Our findings offer valuable insights into MLLMs for art and can benefit a wide range of downstream applications, such as style transfer and artistic image generation. Code available at https://github.com/songrise/MLLM4Art.
Artist: Aesthetically Controllable Text-Driven Stylization without Training
Jul 22, 2024Diffusion models entangle content and style generation during the denoising process, leading to undesired content modification when directly applied to stylization tasks. Existing methods struggle to effectively control the diffusion model to meet the aesthetic-level requirements for stylization. In this paper, we introduce \textbf{Artist}, a training-free approach that aesthetically controls the content and style generation of a pretrained diffusion model for text-driven stylization. Our key insight is to disentangle the denoising of content and style into separate diffusion processes while sharing information between them. We propose simple yet effective content and style control methods that suppress style-irrelevant content generation, resulting in harmonious stylization results. Extensive experiments demonstrate that our method excels at achieving aesthetic-level stylization requirements, preserving intricate details in the content image and aligning well with the style prompt. Furthermore, we showcase the highly controllability of the stylization strength from various perspectives. Code will be released, project home page: https://DiffusionArtist.github.io
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
Mar 14, 2024Prompt-tuning has demonstrated parameter-efficiency in fusing unimodal foundation models for multimodal tasks. However, its limited adaptivity and expressiveness lead to suboptimal performance when compared with other tuning methods. In this paper, we address this issue by disentangling the vanilla prompts to adaptively capture dataset-level and instance-level features. Building upon this disentanglement, we introduce the mixture of prompt experts (MoPE) technique to enhance expressiveness. MoPE leverages multimodal pairing priors to route the most effective prompt on a per-instance basis. Compared to vanilla prompting, our MoPE-based conditional prompting exhibits greater expressiveness for multimodal fusion, scaling better with the training data and the overall number of trainable parameters. We also study a regularization term for expert routing, leading to emergent expert specialization, where different experts focus on different concepts, enabling interpretable soft prompting. Extensive experiments across three multimodal datasets demonstrate that our method achieves state-of-the-art results, matching or even surpassing the performance of fine-tuning, while requiring only 0.8% of the trainable parameters. Code will be released: https://github.com/songrise/MoPE.
Conditional Prompt Tuning for Multimodal Fusion
Nov 28, 2023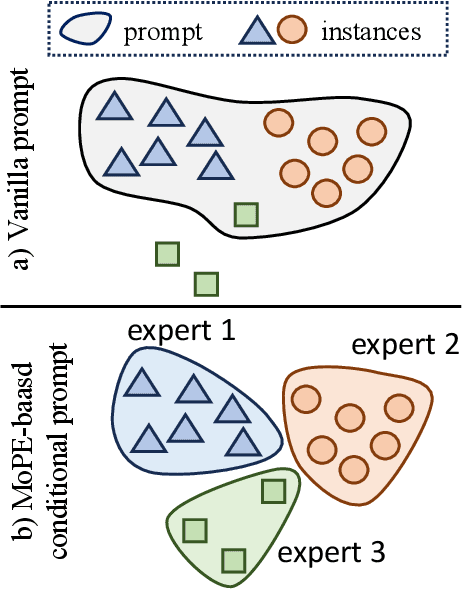
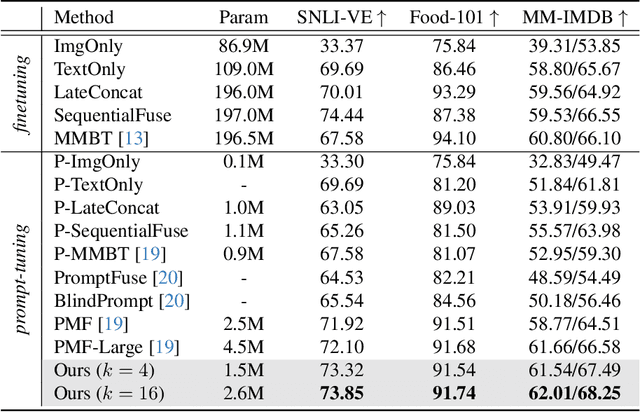
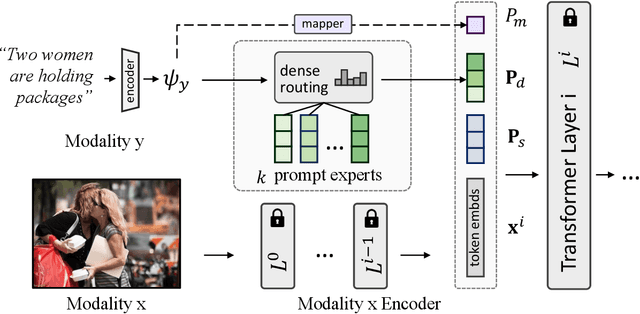
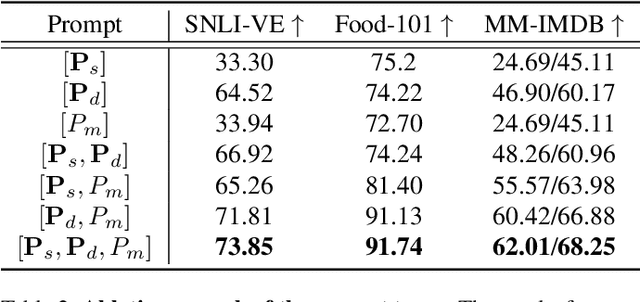
We show that the representation of one modality can effectively guide the prompting of another modality for parameter-efficient multimodal fusion. Specifically, we first encode one modality and use its representation as a prior to conditionally prompt all frozen layers of the other modality. This is achieved by disentangling the vanilla prompt vectors into three types of specialized prompts that adaptively capture global-level and instance-level features. To better produce the instance-wise prompt, we introduce the mixture of prompt experts (MoPE) to dynamically route each instance to the most suitable prompt experts for encoding. We further study a regularization term to avoid degenerated prompt expert routing. Thanks to our design, our method can effectively transfer the pretrained knowledge in unimodal encoders for downstream multimodal tasks. Compared with vanilla prompting, we show that our MoPE-based conditional prompting is more expressive, thereby scales better with training data and the total number of prompts. We also demonstrate that our prompt tuning is architecture-agnostic, thereby offering high modularity. Extensive experiments over three multimodal datasets demonstrate state-of-the-art results, matching or surpassing the performance achieved through fine-tuning, while only necessitating 0.7% of the trainable parameters. Code will be released: https://github.com/songrise/ConditionalPrompt.
CLIP-Count: Towards Text-Guided Zero-Shot Object Counting
May 12, 2023



Recent advances in visual-language models have shown remarkable zero-shot text-image matching ability that is transferable to down-stream tasks such as object detection and segmentation. However, adapting these models for object counting, which involves estimating the number of objects in an image, remains a formidable challenge. In this study, we conduct the first exploration of transferring visual-language models for class-agnostic object counting. Specifically, we propose CLIP-Count, a novel pipeline that estimates density maps for open-vocabulary objects with text guidance in a zero-shot manner, without requiring any finetuning on specific object classes. To align the text embedding with dense image features, we introduce a patch-text contrastive loss that guides the model to learn informative patch-level image representations for dense prediction. Moreover, we design a hierarchical patch-text interaction module that propagates semantic information across different resolution levels of image features. Benefiting from the full exploitation of the rich image-text alignment knowledge of pretrained visual-language models, our method effectively generates high-quality density maps for objects-of-interest. Extensive experiments on FSC-147, CARPK, and ShanghaiTech crowd counting datasets demonstrate that our proposed method achieves state-of-the-art accuracy and generalizability for zero-shot object counting. Project page at https://github.com/songrise/CLIP-Count
AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
Mar 30, 2023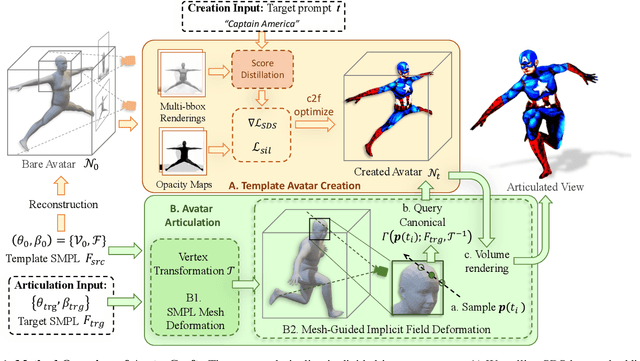
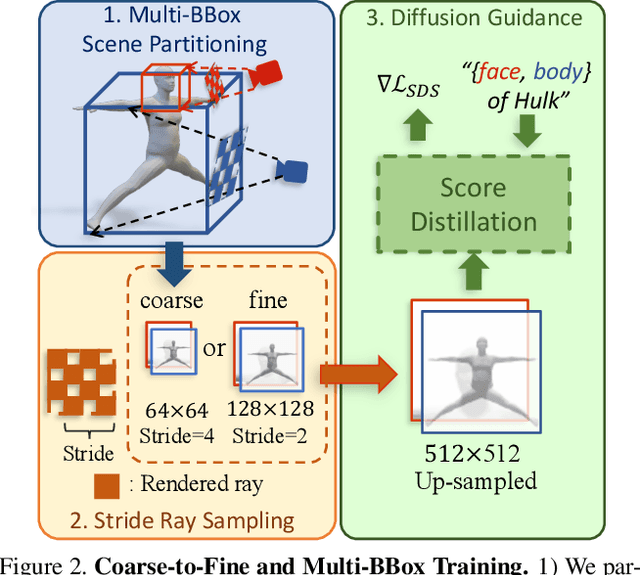
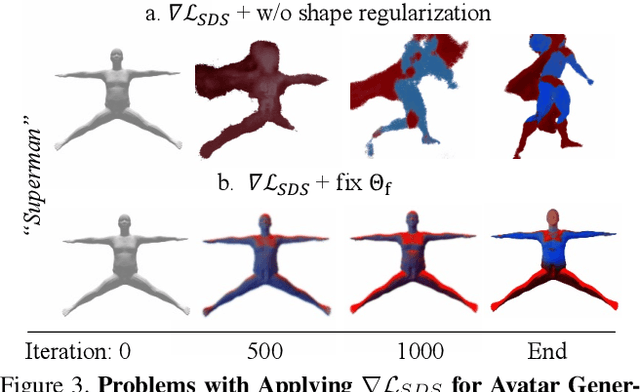
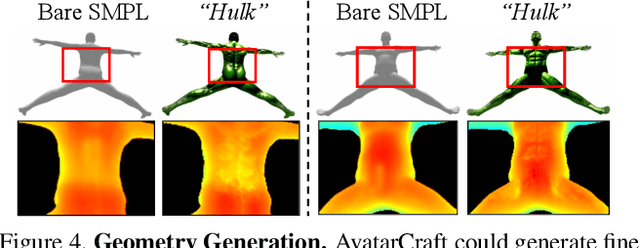
Neural implicit fields are powerful for representing 3D scenes and generating high-quality novel views, but it remains challenging to use such implicit representations for creating a 3D human avatar with a specific identity and artistic style that can be easily animated. Our proposed method, AvatarCraft, addresses this challenge by using diffusion models to guide the learning of geometry and texture for a neural avatar based on a single text prompt. We carefully design the optimization framework of neural implicit fields, including a coarse-to-fine multi-bounding box training strategy, shape regularization, and diffusion-based constraints, to produce high-quality geometry and texture. Additionally, we make the human avatar animatable by deforming the neural implicit field with an explicit warping field that maps the target human mesh to a template human mesh, both represented using parametric human models. This simplifies animation and reshaping of the generated avatar by controlling pose and shape parameters. Extensive experiments on various text descriptions show that AvatarCraft is effective and robust in creating human avatars and rendering novel views, poses, and shapes. Our project page is: \url{https://avatar-craft.github.io/}.
NeRF-Art: Text-Driven Neural Radiance Fields Stylization
Dec 15, 2022



As a powerful representation of 3D scenes, the neural radiance field (NeRF) enables high-quality novel view synthesis from multi-view images. Stylizing NeRF, however, remains challenging, especially on simulating a text-guided style with both the appearance and the geometry altered simultaneously. In this paper, we present NeRF-Art, a text-guided NeRF stylization approach that manipulates the style of a pre-trained NeRF model with a simple text prompt. Unlike previous approaches that either lack sufficient geometry deformations and texture details or require meshes to guide the stylization, our method can shift a 3D scene to the target style characterized by desired geometry and appearance variations without any mesh guidance. This is achieved by introducing a novel global-local contrastive learning strategy, combined with the directional constraint to simultaneously control both the trajectory and the strength of the target style. Moreover, we adopt a weight regularization method to effectively suppress cloudy artifacts and geometry noises which arise easily when the density field is transformed during geometry stylization. Through extensive experiments on various styles, we demonstrate that our method is effective and robust regarding both single-view stylization quality and cross-view consistency. The code and more results can be found in our project page: https://cassiepython.github.io/nerfart/.