 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Contextual Cues: The Case of Personalization and History for Response Ranking
Paper and Code
Jun 01, 2016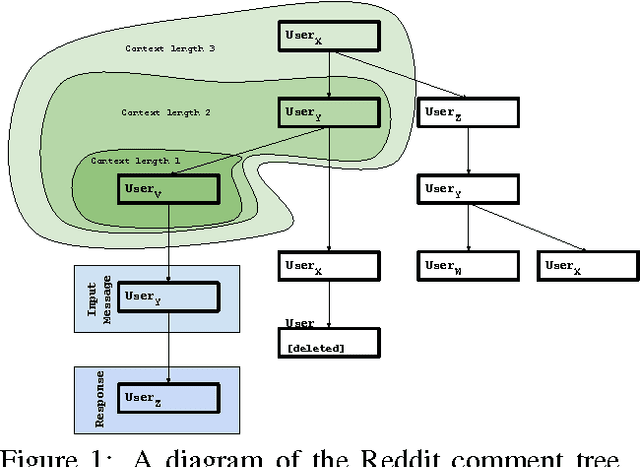
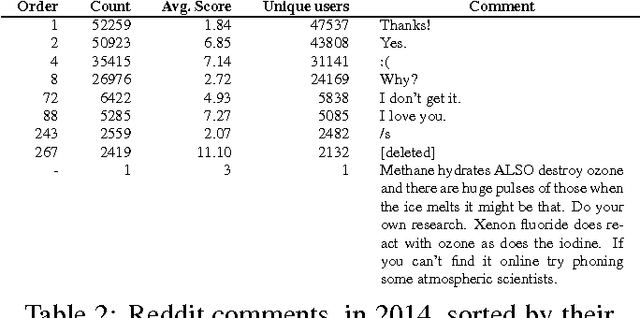
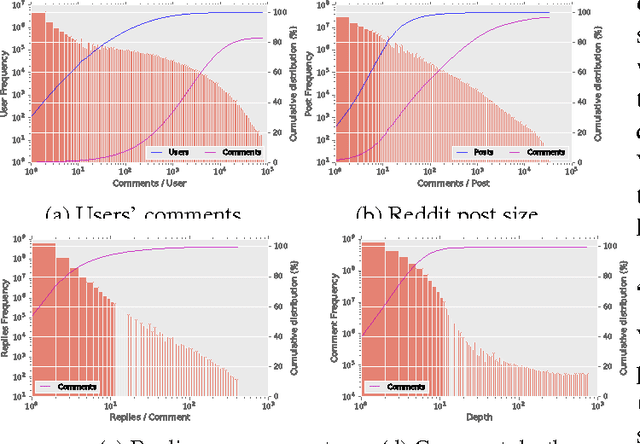
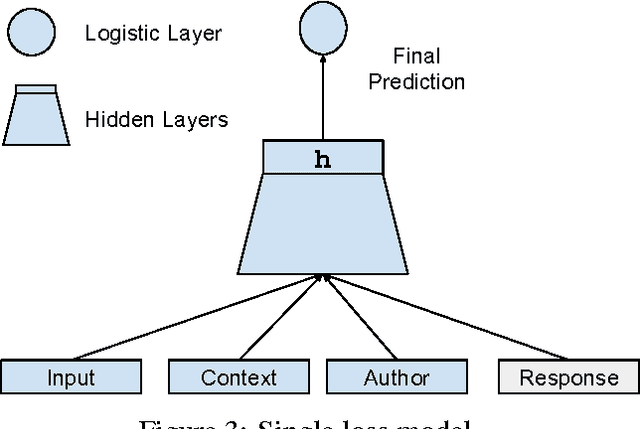
We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.