 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Markov Decision Processes under Fully Bandit Feedback
Feb 02, 2026A standard assumption in Reinforcement Learning is that the agent observes every visited state-action pair in the associated Markov Decision Process (MDP), along with the per-step rewards. Strong theoretical results are known in this setting, achieving nearly-tight $Θ(\sqrt{T})$-regret bounds. However, such detailed feedback can be unrealistic, and recent research has investigated more restricted settings such as trajectory feedback, where the agent observes all the visited state-action pairs, but only a single \emph{aggregate} reward. In this paper, we consider a far more restrictive ``fully bandit'' feedback model for episodic MDPs, where the agent does not even observe the visited state-action pairs -- it only learns the aggregate reward. We provide the first efficient bandit learning algorithm for episodic MDPs with $\widetilde{O}(\sqrt{T})$ regret. Our regret has an exponential dependence on the horizon length $\H$, which we show is necessary. We also obtain improved nearly-tight regret bounds for ``ordered'' MDPs; these can be used to model classical stochastic optimization problems such as $k$-item prophet inequality and sequential posted pricing. Finally, we evaluate the empirical performance of our algorithm for the setting of $k$-item prophet inequalities; despite the highly restricted feedback, our algorithm's performance is comparable to that of a state-of-art learning algorithm (UCB-VI) with detailed state-action feedback.
Randomized Truthful Auctions with Learning Agents
Nov 14, 2024We study a setting where agents use no-regret learning algorithms to participate in repeated auctions. \citet{kolumbus2022auctions} showed, rather surprisingly, that when bidders participate in second-price auctions using no-regret bidding algorithms, no matter how large the number of interactions $T$ is, the runner-up bidder may not converge to bidding truthfully. Our first result shows that this holds for \emph{general deterministic} truthful auctions. We also show that the ratio of the learning rates of the bidders can \emph{qualitatively} affect the convergence of the bidders. Next, we consider the problem of revenue maximization in this environment. In the setting with fully rational bidders, \citet{myerson1981optimal} showed that revenue can be maximized by using a second-price auction with reserves.We show that, in stark contrast, in our setting with learning bidders, \emph{randomized} auctions can have strictly better revenue guarantees than second-price auctions with reserves, when $T$ is large enough. Finally, we study revenue maximization in the non-asymptotic regime. We define a notion of {\em auctioneer regret} comparing the revenue generated to the revenue of a second price auction with truthful bids. When the auctioneer has to use the same auction throughout the interaction, we show an (almost) tight regret bound of $\smash{\widetilde \Theta(T^{3/4})}.$ If the auctioneer can change auctions during the interaction, but in a way that is oblivious to the bids, we show an (almost) tight bound of $\smash{\widetilde \Theta(\sqrt{T})}.$
Position Coupling: Leveraging Task Structure for Improved Length Generalization of Transformers
May 31, 2024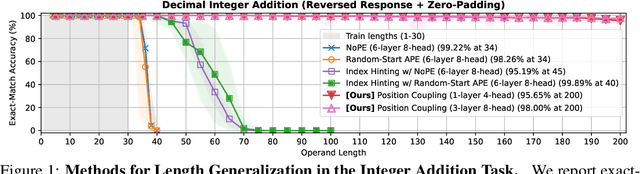

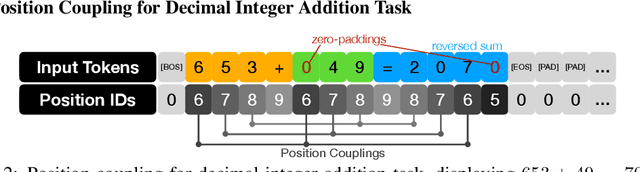
Even for simple arithmetic tasks like integer addition, it is challenging for Transformers to generalize to longer sequences than those encountered during training. To tackle this problem, we propose position coupling, a simple yet effective method that directly embeds the structure of the tasks into the positional encoding of a (decoder-only) Transformer. Taking a departure from the vanilla absolute position mechanism assigning unique position IDs to each of the tokens, we assign the same position IDs to two or more "relevant" tokens; for integer addition tasks, we regard digits of the same significance as in the same position. On the empirical side, we show that with the proposed position coupling, a small (1-layer) Transformer trained on 1 to 30-digit additions can generalize up to 200-digit additions (6.67x of the trained length). On the theoretical side, we prove that a 1-layer Transformer with coupled positions can solve the addition task involving exponentially many digits, whereas any 1-layer Transformer without positional information cannot entirely solve it. We also demonstrate that position coupling can be applied to other algorithmic tasks such as addition with multiple summands, Nx2 multiplication, copy/reverse, and a two-dimensional task.
MAC Advice for Facility Location Mechanism Design
Mar 18, 2024



Algorithms with predictions have attracted much attention in the last years across various domains, including variants of facility location, as a way to surpass traditional worst-case analyses. We study the $k$-facility location mechanism design problem, where the $n$ agents are strategic and might misreport their location. Unlike previous models, where predictions are for the $k$ optimal facility locations, we receive $n$ predictions for the locations of each of the agents. However, these predictions are only "mostly" and "approximately" correct (or MAC for short) -- i.e., some $\delta$-fraction of the predicted locations are allowed to be arbitrarily incorrect, and the remainder of the predictions are allowed to be correct up to an $\varepsilon$-error. We make no assumption on the independence of the errors. Can such predictions allow us to beat the current best bounds for strategyproof facility location? We show that the $1$-median (geometric median) of a set of points is naturally robust under corruptions, which leads to an algorithm for single-facility location with MAC predictions. We extend the robustness result to a "balanced" variant of the $k$ facilities case. Without balancedness, we show that robustness completely breaks down, even for the setting of $k=2$ facilities on a line. For this "unbalanced" setting, we devise a truthful random mechanism that outperforms the best known result of Lu et al. [2010], which does not use predictions. En route, we introduce the problem of "second" facility location (when the first facility's location is already fixed). Our findings on the robustness of the $1$-median and more generally $k$-medians may be of independent interest, as quantitative versions of classic breakdown-point results in robust statistics.
Early Fusion of Features for Semantic Segmentation
Feb 08, 2024

This paper introduces a novel segmentation framework that integrates a classifier network with a reverse HRNet architecture for efficient image segmentation. Our approach utilizes a ResNet-50 backbone, pretrained in a semi-supervised manner, to generate feature maps at various scales. These maps are then processed by a reverse HRNet, which is adapted to handle varying channel dimensions through 1x1 convolutions, to produce the final segmentation output. We strategically avoid fine-tuning the backbone network to minimize memory consumption during training. Our methodology is rigorously tested across several benchmark datasets including Mapillary Vistas, Cityscapes, CamVid, COCO, and PASCAL-VOC2012, employing metrics such as pixel accuracy and mean Intersection over Union (mIoU) to evaluate segmentation performance. The results demonstrate the effectiveness of our proposed model in achieving high segmentation accuracy, indicating its potential for various applications in image analysis. By leveraging the strengths of both the ResNet-50 and reverse HRNet within a unified framework, we present a robust solution to the challenges of image segmentation.
Improving Length-Generalization in Transformers via Task Hinting
Oct 01, 2023It has been observed in recent years that transformers have problems with length generalization for certain types of reasoning and arithmetic tasks. In particular, the performance of a transformer model trained on tasks (say addition) up to a certain length (e.g., 5 digit numbers) drops sharply when applied to longer instances of the same problem. This work proposes an approach based on task hinting towards addressing length generalization. Our key idea is that while training the model on task-specific data, it is helpful to simultaneously train the model to solve a simpler but related auxiliary task as well. We study the classical sorting problem as a canonical example to evaluate our approach. We design a multitask training framework and show that task hinting significantly improve length generalization. For sorting we show that it is possible to train models on data consisting of sequences having length at most $20$, and improve the test accuracy on sequences of length $100$ from less than 1% (for standard training) to more than 92% (via task hinting). Our study uncovers several interesting aspects of length generalization. We observe that while several auxiliary tasks may seem natural a priori, their effectiveness in improving length generalization differs dramatically. We further use probing and visualization-based techniques to understand the internal mechanisms via which the model performs the task, and propose a theoretical construction consistent with the observed learning behaviors of the model. Based on our construction, we show that introducing a small number of length dependent parameters into the training procedure can further boost the performance on unseen lengths. Finally, we also show the efficacy of our task hinting based approach beyond sorting, giving hope that these techniques will be applicable in broader contexts.
Optimal shepherding and transport of a flock
Nov 09, 2022We investigate how a shepherd should move in order to effectively herd and guide a flock of agents towards a target. Using a detailed agent-based model (ABM) for the members of the flock, we pose and solve an optimization problem for the shepherd that has to simultaneously work to keep the flock cohesive while coercing it towards a prescribed project. We find that three distinct strategies emerge as potential solutions as a function of just two parameters: the ratio of herd size to shepherd repulsion length and the ratio of herd speed to shepherd speed. We term these as: (i) mustering, in which the shepherd circles the herd to ensure compactness, (ii) droving, in which the shepherd chases the herd in a desired direction, and (iii) driving, a hitherto unreported strategy where the flock surrounds a shepherd that drives it from within. A minimal dynamical model for the size, shape and position of the herd captures the effective behavior of the ABM, and further allows us to characterize the different herding strategies in terms of the behavior of the shepherd that librates (mustering), oscillates (droving) or moves steadily (driving). All together, our study yields a simple and intuitive classification of herding strategies that ought to be of general interest in the context of controlling the collective behavior of active matter.
Better Algorithms for Stochastic Bandits with Adversarial Corruptions
Mar 28, 2019We study the stochastic multi-armed bandits problem in the presence of adversarial corruption. We present a new algorithm for this problem whose regret is nearly optimal, substantially improving upon previous work. Our algorithm is agnostic to the level of adversarial contamination and can tolerate a significant amount of corruption with virtually no degradation in performance.
Spatiotemporal Filtering for Event-Based Action Recognition
Mar 17, 2019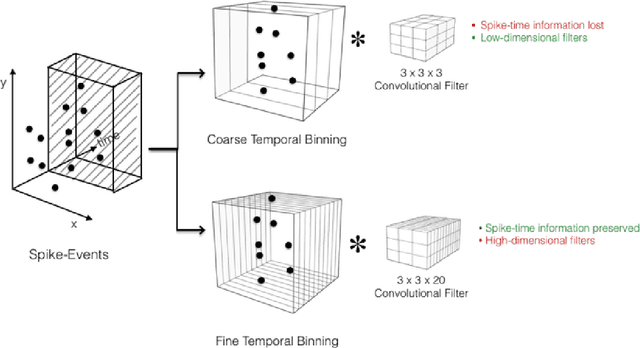
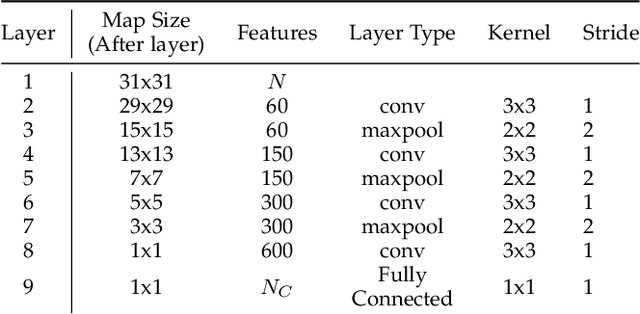
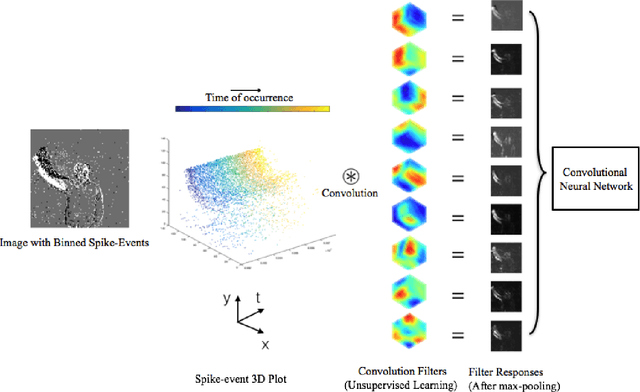
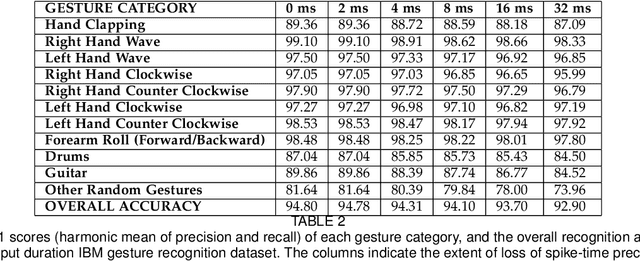
In this paper, we address the challenging problem of action recognition, using event-based cameras. To recognise most gestural actions, often higher temporal precision is required for sampling visual information. Actions are defined by motion, and therefore, when using event-based cameras it is often unnecessary to re-sample the entire scene. Neuromorphic, event-based cameras have presented an alternative to visual information acquisition by asynchronously time-encoding pixel intensity changes, through temporally precise spikes (10 micro-second resolution), making them well equipped for action recognition. However, other challenges exist, which are intrinsic to event-based imagers, such as higher signal-to-noise ratio, and a spatiotemporally sparse information. One option is to convert event-data into frames, but this could result in significant temporal precision loss. In this work we introduce spatiotemporal filtering in the spike-event domain, as an alternative way of channeling spatiotemporal information through to a convolutional neural network. The filters are local spatiotemporal weight matrices, learned from the spike-event data, in an unsupervised manner. We find that appropriate spatiotemporal filtering significantly improves CNN performance beyond state-of-the-art on the event-based DVS Gesture dataset. On our newly recorded action recognition dataset, our method shows significant improvement when compared with other, standard ways of generating the spatiotemporal filters.
Spatiotemporal Feature Learning for Event-Based Vision
Mar 16, 2019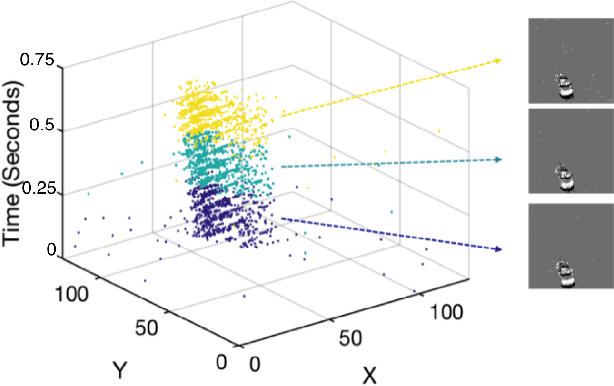
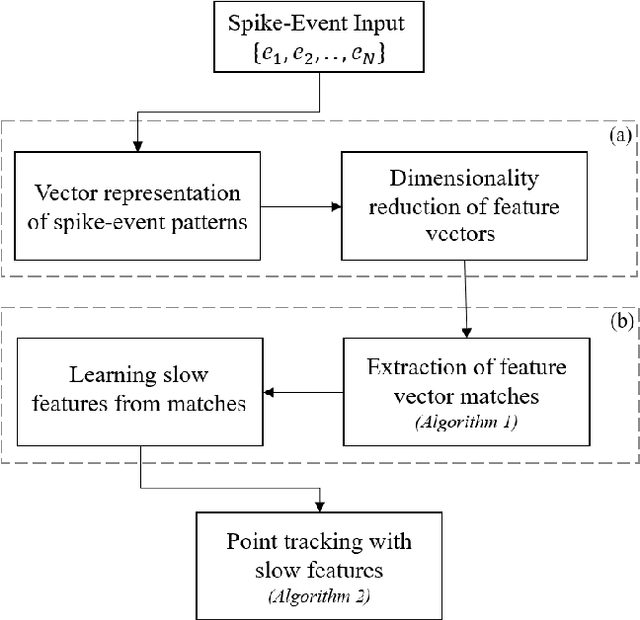
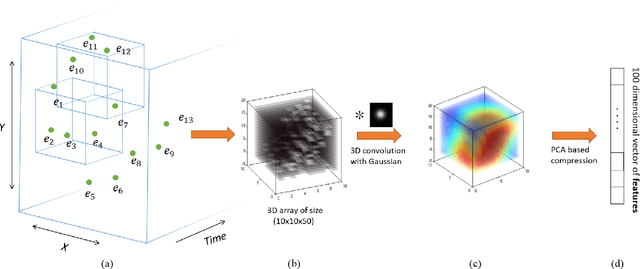
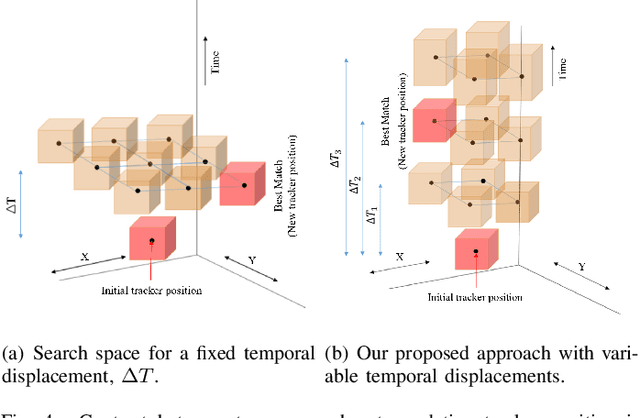
Unlike conventional frame-based sensors, event-based visual sensors output information through spikes at a high temporal resolution. By only encoding changes in pixel intensity, they showcase a low-power consuming, low-latency approach to visual information sensing. To use this information for higher sensory tasks like object recognition and tracking, an essential simplification step is the extraction and learning of features. An ideal feature descriptor must be robust to changes involving (i) local transformations and (ii) re-appearances of a local event pattern. To that end, we propose a novel spatiotemporal feature representation learning algorithm based on slow feature analysis (SFA). Using SFA, smoothly changing linear projections are learnt which are robust to local visual transformations. In order to determine if the features can learn to be invariant to various visual transformations, feature point tracking tasks are used for evaluation. Extensive experiments across two datasets demonstrate the adaptability of the spatiotemporal feature learner to translation, scaling and rotational transformations of the feature points. More importantly, we find that the obtained feature representations are able to exploit the high temporal resolution of such event-based cameras in generating better feature tracks.