 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Filtering for Event-Based Action Recognition
Mar 17, 2019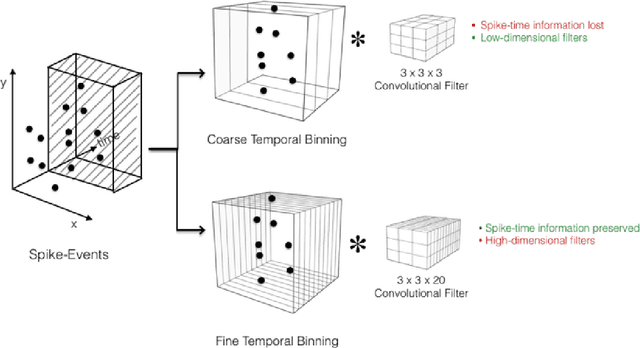
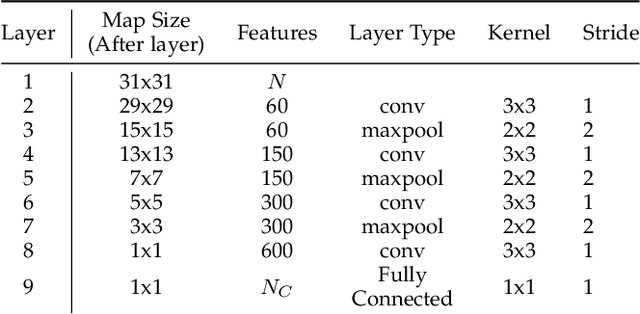
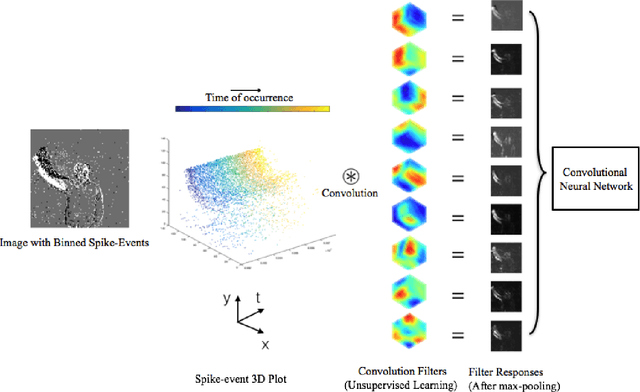
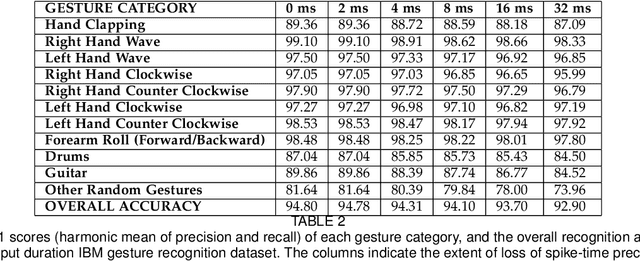
In this paper, we address the challenging problem of action recognition, using event-based cameras. To recognise most gestural actions, often higher temporal precision is required for sampling visual information. Actions are defined by motion, and therefore, when using event-based cameras it is often unnecessary to re-sample the entire scene. Neuromorphic, event-based cameras have presented an alternative to visual information acquisition by asynchronously time-encoding pixel intensity changes, through temporally precise spikes (10 micro-second resolution), making them well equipped for action recognition. However, other challenges exist, which are intrinsic to event-based imagers, such as higher signal-to-noise ratio, and a spatiotemporally sparse information. One option is to convert event-data into frames, but this could result in significant temporal precision loss. In this work we introduce spatiotemporal filtering in the spike-event domain, as an alternative way of channeling spatiotemporal information through to a convolutional neural network. The filters are local spatiotemporal weight matrices, learned from the spike-event data, in an unsupervised manner. We find that appropriate spatiotemporal filtering significantly improves CNN performance beyond state-of-the-art on the event-based DVS Gesture dataset. On our newly recorded action recognition dataset, our method shows significant improvement when compared with other, standard ways of generating the spatiotemporal filters.
Spatiotemporal Feature Learning for Event-Based Vision
Mar 16, 2019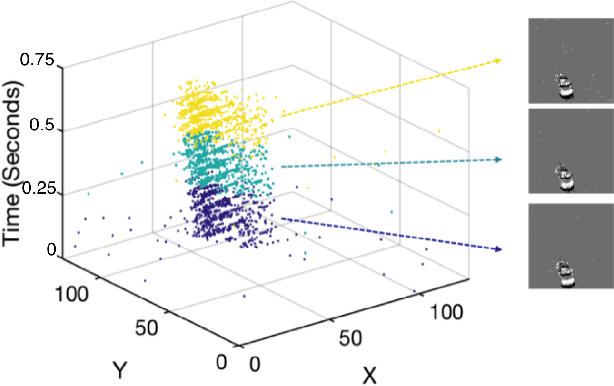
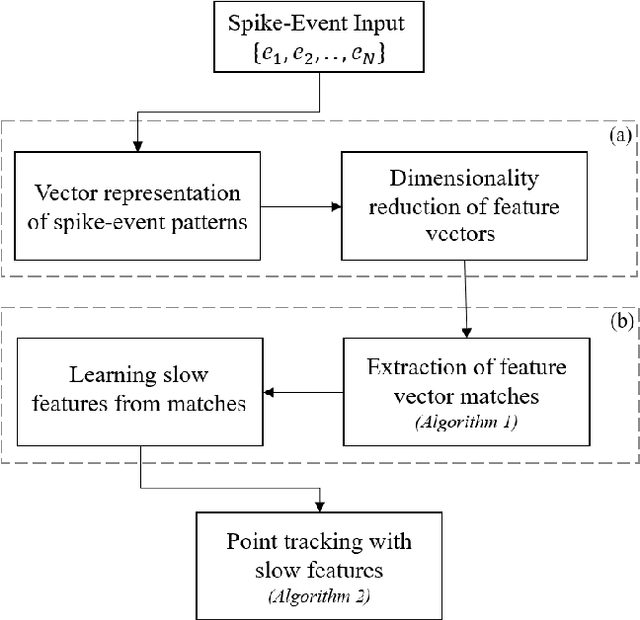
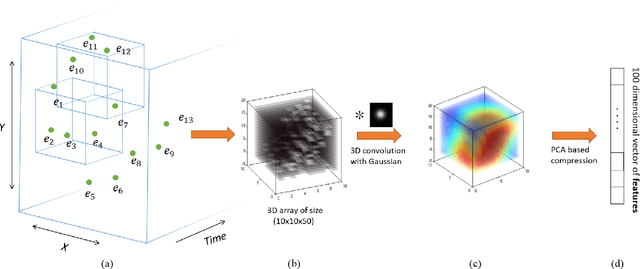
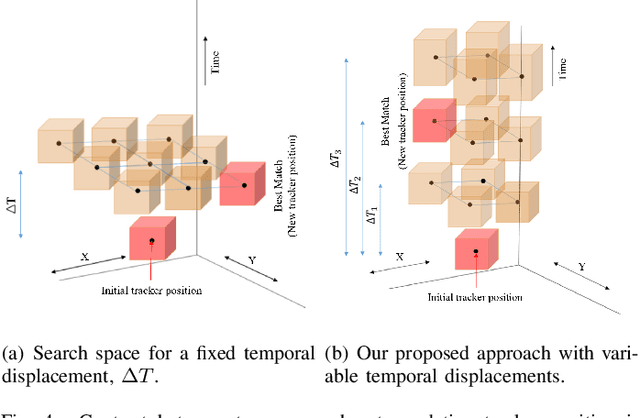
Unlike conventional frame-based sensors, event-based visual sensors output information through spikes at a high temporal resolution. By only encoding changes in pixel intensity, they showcase a low-power consuming, low-latency approach to visual information sensing. To use this information for higher sensory tasks like object recognition and tracking, an essential simplification step is the extraction and learning of features. An ideal feature descriptor must be robust to changes involving (i) local transformations and (ii) re-appearances of a local event pattern. To that end, we propose a novel spatiotemporal feature representation learning algorithm based on slow feature analysis (SFA). Using SFA, smoothly changing linear projections are learnt which are robust to local visual transformations. In order to determine if the features can learn to be invariant to various visual transformations, feature point tracking tasks are used for evaluation. Extensive experiments across two datasets demonstrate the adaptability of the spatiotemporal feature learner to translation, scaling and rotational transformations of the feature points. More importantly, we find that the obtained feature representations are able to exploit the high temporal resolution of such event-based cameras in generating better feature tracks.