 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Classification Utilizing Neuromorphic Proprioceptive Signals in Active Exploration: Validated on a Soft Anthropomorphic Hand
May 23, 2025Proprioception, a key sensory modality in haptic perception, plays a vital role in perceiving the 3D structure of objects by providing feedback on the position and movement of body parts. The restoration of proprioceptive sensation is crucial for enabling in-hand manipulation and natural control in the prosthetic hand. Despite its importance, proprioceptive sensation is relatively unexplored in an artificial system. In this work, we introduce a novel platform that integrates a soft anthropomorphic robot hand (QB SoftHand) with flexible proprioceptive sensors and a classifier that utilizes a hybrid spiking neural network with different types of spiking neurons to interpret neuromorphic proprioceptive signals encoded by a biological muscle spindle model. The encoding scheme and the classifier are implemented and tested on the datasets we collected in the active exploration of ten objects from the YCB benchmark. Our results indicate that the classifier achieves more accurate inferences than existing learning approaches, especially in the early stage of the exploration. This system holds the potential for development in the areas of haptic feedback and neural prosthetics.
Adaptive Subsampling and Learned Model Improve Spatiotemporal Resolution of Tactile Skin
Oct 17, 2024



High-speed tactile arrays are essential for real-time robotic control in unstructured environments, but high pixel counts limit readout rates of most large tactile arrays to below 100Hz. We introduce ACTS - adaptive compressive tactile subsampling - a method that efficiently samples tactile matrices and reconstructs interactions using sparse recovery and a learned tactile dictionary. Tested on a 1024-pixel sensor array (32x32), ACTS increased frame rates by 18X compared to raster scanning, with minimal error. For the first time in large-area tactile skin, we demonstrate rapid object classification within 20ms of contact, high-speed projectile detection, ricochet angle estimation, and deformation tracking through enhanced spatiotemporal resolution. Our method can be implemented in firmware, upgrading existing low-cost, flexible, and robust tactile arrays into high-resolution systems for large-area spatiotemporal touch sensing.
A novel open-source ultrasound dataset with deep learning benchmarks for spinal cord injury localization and anatomical segmentation
Sep 24, 2024



While deep learning has catalyzed breakthroughs across numerous domains, its broader adoption in clinical settings is inhibited by the costly and time-intensive nature of data acquisition and annotation. To further facilitate medical machine learning, we present an ultrasound dataset of 10,223 Brightness-mode (B-mode) images consisting of sagittal slices of porcine spinal cords (N=25) before and after a contusion injury. We additionally benchmark the performance metrics of several state-of-the-art object detection algorithms to localize the site of injury and semantic segmentation models to label the anatomy for comparison and creation of task-specific architectures. Finally, we evaluate the zero-shot generalization capabilities of the segmentation models on human ultrasound spinal cord images to determine whether training on our porcine dataset is sufficient for accurately interpreting human data. Our results show that the YOLOv8 detection model outperforms all evaluated models for injury localization, achieving a mean Average Precision (mAP50-95) score of 0.606. Segmentation metrics indicate that the DeepLabv3 segmentation model achieves the highest accuracy on unseen porcine anatomy, with a Mean Dice score of 0.587, while SAMed achieves the highest Mean Dice score generalizing to human anatomy (0.445). To the best of our knowledge, this is the largest annotated dataset of spinal cord ultrasound images made publicly available to researchers and medical professionals, as well as the first public report of object detection and segmentation architectures to assess anatomical markers in the spinal cord for methodology development and clinical applications.
Prospective Learning: Back to the Future
Jan 19, 2022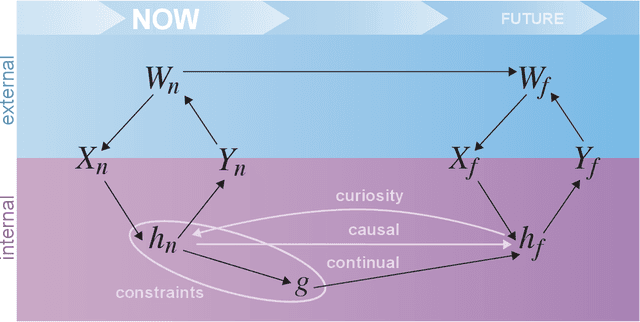

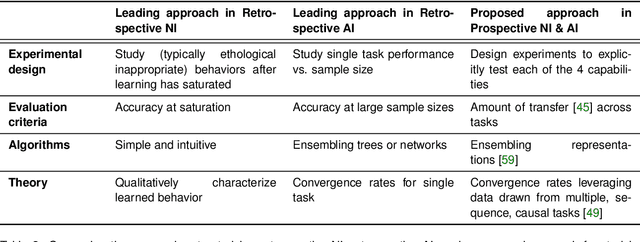
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Improving Intention Detection in Single-Trial Classification through Fusion of EEG and Eye-tracker Data
Dec 05, 2021


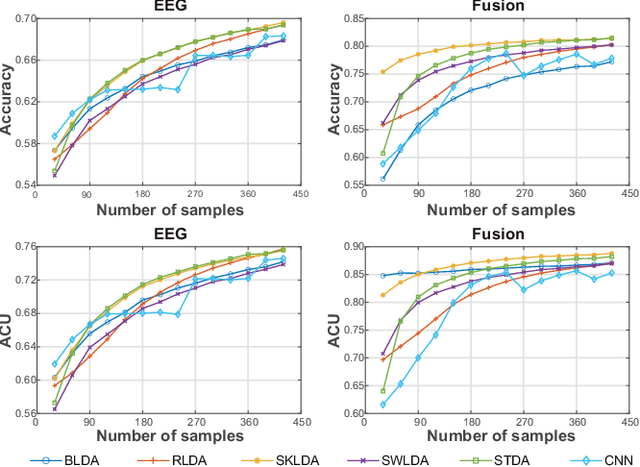
Intention decoding is an indispensable procedure in hands-free human-computer interaction (HCI). Conventional eye-tracking system using single-model fixation duration possibly issues commands ignoring users' real expectation. In the current study, an eye-brain hybrid brain-computer interface (BCI) interaction system was introduced for intention detection through fusion of multi-modal eye-track and ERP (a measurement derived from EEG) features. Eye-track and EEG data were recorded from 64 healthy participants as they performed a 40-min customized free search task of a fixed target icon among 25 icons. The corresponding fixation duration of eye-tracking and ERP were extracted. Five previously-validated LDA-based classifiers (including RLDA, SWLDA, BLDA, SKLDA, and STDA) and the widely-used CNN method were adopted to verify the efficacy of feature fusion from both offline and pseudo-online analysis, and optimal approach was evaluated through modulating the training set and system response duration. Our study demonstrated that the input of multi-modal eye-track and ERP features achieved superior performance of intention detection in the single trial classification of active search task. And compared with single-model ERP feature, this new strategy also induced congruent accuracy across different classifiers. Moreover, in comparison with other classification methods, we found that the SKLDA exhibited the superior performance when fusing feature in offline test (ACC=0.8783, AUC=0.9004) and online simulation with different sample amount and duration length. In sum, the current study revealed a novel and effective approach for intention classification using eye-brain hybrid BCI, and further supported the real-life application of hands-free HCI in a more precise and stable manner.
Pose-Invariant Object Recognition for Event-Based Vision with Slow-ELM
Mar 19, 2019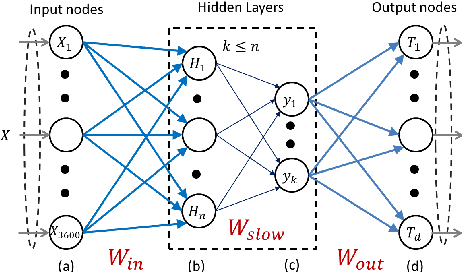
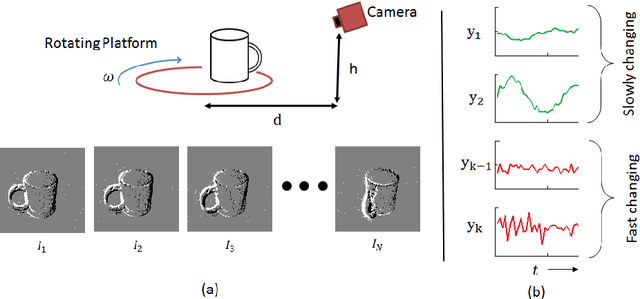
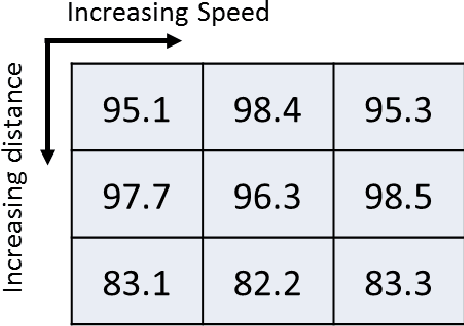
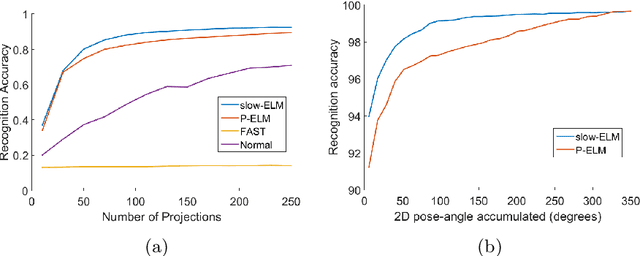
Neuromorphic image sensors produce activity-driven spiking output at every pixel. These low-power consuming imagers which encode visual change information in the form of spikes help reduce computational overhead and realize complex real-time systems; object recognition and pose-estimation to name a few. However, there exists a lack of algorithms in event-based vision aimed towards capturing invariance to transformations. In this work, we propose a methodology for recognizing objects invariant to their pose with the Dynamic Vision Sensor (DVS). A novel slow-ELM architecture is proposed which combines the effectiveness of Extreme Learning Machines and Slow Feature Analysis. The system, tested on an Intel Core i5-4590 CPU, can perform 10,000 classifications per second and achieves 1% classification error for 8 objects with views accumulated over 90 degrees of 2D pose.
Spatiotemporal Filtering for Event-Based Action Recognition
Mar 17, 2019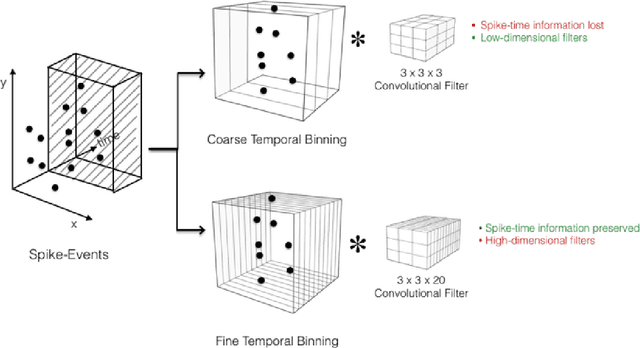
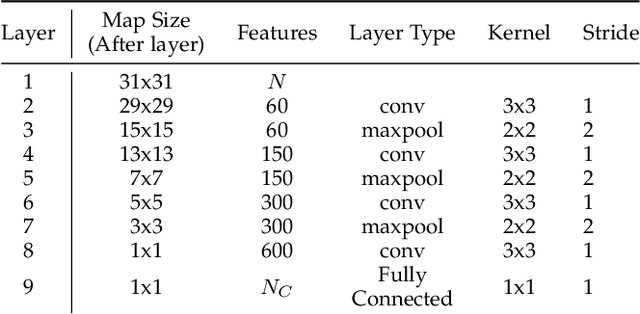
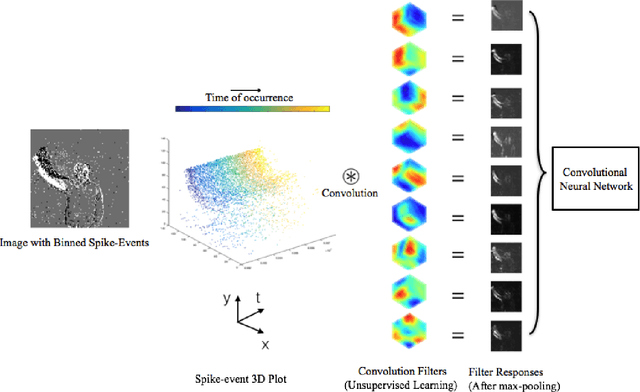
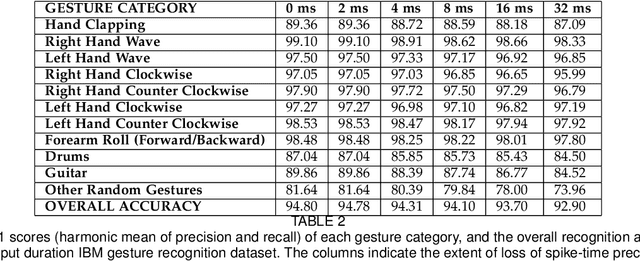
In this paper, we address the challenging problem of action recognition, using event-based cameras. To recognise most gestural actions, often higher temporal precision is required for sampling visual information. Actions are defined by motion, and therefore, when using event-based cameras it is often unnecessary to re-sample the entire scene. Neuromorphic, event-based cameras have presented an alternative to visual information acquisition by asynchronously time-encoding pixel intensity changes, through temporally precise spikes (10 micro-second resolution), making them well equipped for action recognition. However, other challenges exist, which are intrinsic to event-based imagers, such as higher signal-to-noise ratio, and a spatiotemporally sparse information. One option is to convert event-data into frames, but this could result in significant temporal precision loss. In this work we introduce spatiotemporal filtering in the spike-event domain, as an alternative way of channeling spatiotemporal information through to a convolutional neural network. The filters are local spatiotemporal weight matrices, learned from the spike-event data, in an unsupervised manner. We find that appropriate spatiotemporal filtering significantly improves CNN performance beyond state-of-the-art on the event-based DVS Gesture dataset. On our newly recorded action recognition dataset, our method shows significant improvement when compared with other, standard ways of generating the spatiotemporal filters.
Spatiotemporal Feature Learning for Event-Based Vision
Mar 16, 2019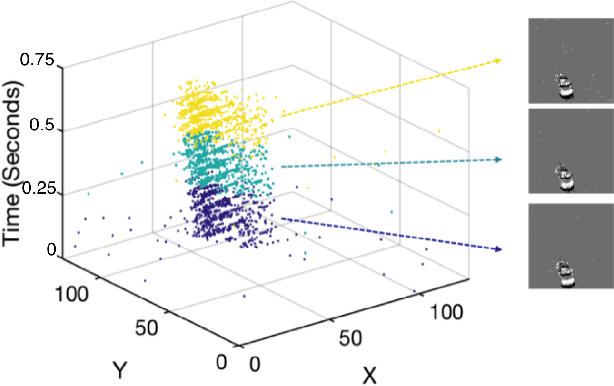
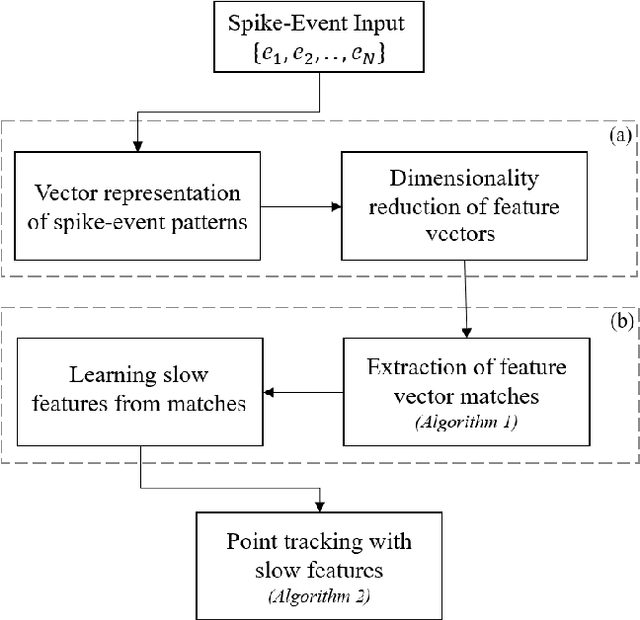
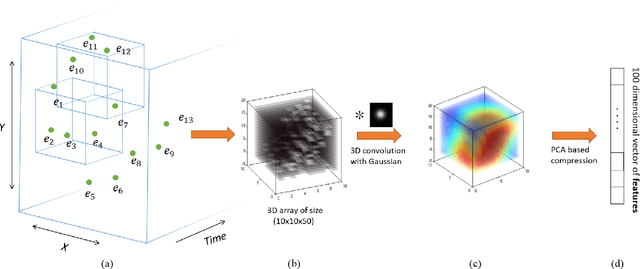
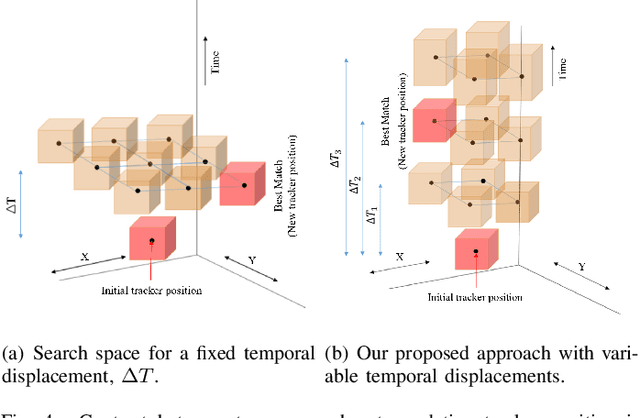
Unlike conventional frame-based sensors, event-based visual sensors output information through spikes at a high temporal resolution. By only encoding changes in pixel intensity, they showcase a low-power consuming, low-latency approach to visual information sensing. To use this information for higher sensory tasks like object recognition and tracking, an essential simplification step is the extraction and learning of features. An ideal feature descriptor must be robust to changes involving (i) local transformations and (ii) re-appearances of a local event pattern. To that end, we propose a novel spatiotemporal feature representation learning algorithm based on slow feature analysis (SFA). Using SFA, smoothly changing linear projections are learnt which are robust to local visual transformations. In order to determine if the features can learn to be invariant to various visual transformations, feature point tracking tasks are used for evaluation. Extensive experiments across two datasets demonstrate the adaptability of the spatiotemporal feature learner to translation, scaling and rotational transformations of the feature points. More importantly, we find that the obtained feature representations are able to exploit the high temporal resolution of such event-based cameras in generating better feature tracks.
HFirst: A Temporal Approach to Object Recognition
Aug 05, 2015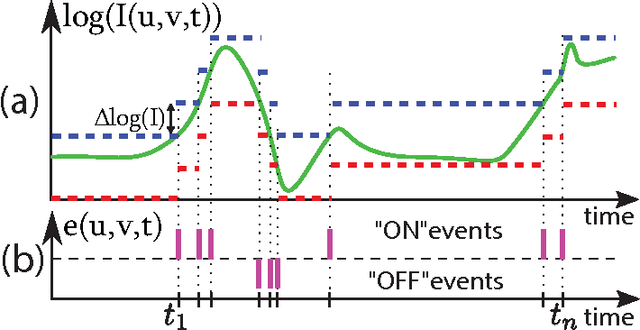
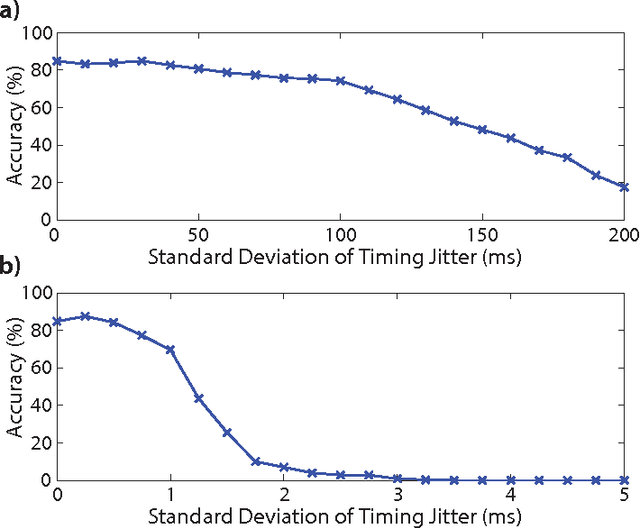
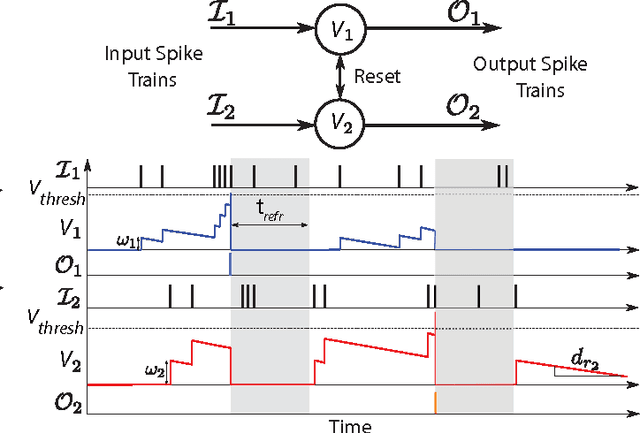
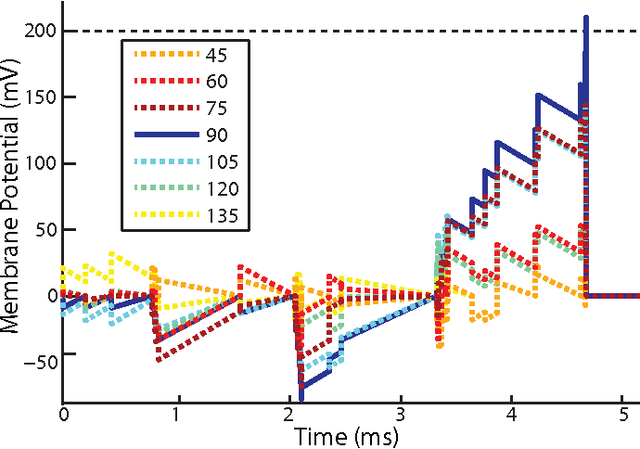
This paper introduces a spiking hierarchical model for object recognition which utilizes the precise timing information inherently present in the output of biologically inspired asynchronous Address Event Representation (AER) vision sensors. The asynchronous nature of these systems frees computation and communication from the rigid predetermined timing enforced by system clocks in conventional systems. Freedom from rigid timing constraints opens the possibility of using true timing to our advantage in computation. We show not only how timing can be used in object recognition, but also how it can in fact simplify computation. Specifically, we rely on a simple temporal-winner-take-all rather than more computationally intensive synchronous operations typically used in biologically inspired neural networks for object recognition. This approach to visual computation represents a major paradigm shift from conventional clocked systems and can find application in other sensory modalities and computational tasks. We showcase effectiveness of the approach by achieving the highest reported accuracy to date (97.5\%$\pm$3.5\%) for a previously published four class card pip recognition task and an accuracy of 84.9\%$\pm$1.9\% for a new more difficult 36 class character recognition task.
* 13 pages, 10 figures