 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTab-PET: Graph-Based Positional Encodings for Tabular Transformers
Nov 17, 2025Supervised learning with tabular data presents unique challenges, including low data sizes, the absence of structural cues, and heterogeneous features spanning both categorical and continuous domains. Unlike vision and language tasks, where models can exploit inductive biases in the data, tabular data lacks inherent positional structure, hindering the effectiveness of self-attention mechanisms. While recent transformer-based models like TabTransformer, SAINT, and FT-Transformer (which we refer to as 3T) have shown promise on tabular data, they typically operate without leveraging structural cues such as positional encodings (PEs), as no prior structural information is usually available. In this work, we find both theoretically and empirically that structural cues, specifically PEs can be a useful tool to improve generalization performance for tabular transformers. We find that PEs impart the ability to reduce the effective rank (a form of intrinsic dimensionality) of the features, effectively simplifying the task by reducing the dimensionality of the problem, yielding improved generalization. To that end, we propose Tab-PET (PEs for Tabular Transformers), a graph-based framework for estimating and inculcating PEs into embeddings. Inspired by approaches that derive PEs from graph topology, we explore two paradigms for graph estimation: association-based and causality-based. We empirically demonstrate that graph-derived PEs significantly improve performance across 50 classification and regression datasets for 3T. Notably, association-based graphs consistently yield more stable and pronounced gains compared to causality-driven ones. Our work highlights an unexpected role of PEs in tabular transformers, revealing how they can be harnessed to improve generalization.
Local Intrinsic Dimensional Entropy
Apr 06, 2023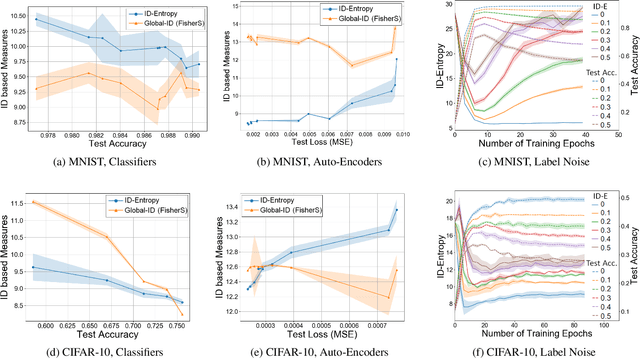
Most entropy measures depend on the spread of the probability distribution over the sample space X, and the maximum entropy achievable scales proportionately with the sample space cardinality |X|. For a finite |X|, this yields robust entropy measures which satisfy many important properties, such as invariance to bijections, while the same is not true for continuous spaces (where |X|=infinity). Furthermore, since R and R^d (d in Z+) have the same cardinality (from Cantor's correspondence argument), cardinality-dependent entropy measures cannot encode the data dimensionality. In this work, we question the role of cardinality and distribution spread in defining entropy measures for continuous spaces, which can undergo multiple rounds of transformations and distortions, e.g., in neural networks. We find that the average value of the local intrinsic dimension of a distribution, denoted as ID-Entropy, can serve as a robust entropy measure for continuous spaces, while capturing the data dimensionality. We find that ID-Entropy satisfies many desirable properties and can be extended to conditional entropy, joint entropy and mutual-information variants. ID-Entropy also yields new information bottleneck principles and also links to causality. In the context of deep learning, for feedforward architectures, we show, theoretically and empirically, that the ID-Entropy of a hidden layer directly controls the generalization gap for both classifiers and auto-encoders, when the target function is Lipschitz continuous. Our work primarily shows that, for continuous spaces, taking a structural rather than a statistical approach yields entropy measures which preserve intrinsic data dimensionality, while being relevant for studying various architectures.
Optimizing Learning Rate Schedules for Iterative Pruning of Deep Neural Networks
Dec 09, 2022



The importance of learning rate (LR) schedules on network pruning has been observed in a few recent works. As an example, Frankle and Carbin (2019) highlighted that winning tickets (i.e., accuracy preserving subnetworks) can not be found without applying a LR warmup schedule and Renda, Frankle and Carbin (2020) demonstrated that rewinding the LR to its initial state at the end of each pruning cycle improves performance. In this paper, we go one step further by first providing a theoretical justification for the surprising effect of LR schedules. Next, we propose a LR schedule for network pruning called SILO, which stands for S-shaped Improved Learning rate Optimization. The advantages of SILO over existing state-of-the-art (SOTA) LR schedules are two-fold: (i) SILO has a strong theoretical motivation and dynamically adjusts the LR during pruning to improve generalization. Specifically, SILO increases the LR upper bound (max_lr) in an S-shape. This leads to an improvement of 2% - 4% in extensive experiments with various types of networks (e.g., Vision Transformers, ResNet) on popular datasets such as ImageNet, CIFAR-10/100. (ii) In addition to the strong theoretical motivation, SILO is empirically optimal in the sense of matching an Oracle, which exhaustively searches for the optimal value of max_lr via grid search. We find that SILO is able to precisely adjust the value of max_lr to be within the Oracle optimized interval, resulting in performance competitive with the Oracle with significantly lower complexity.
AP: Selective Activation for De-sparsifying Pruned Neural Networks
Dec 09, 2022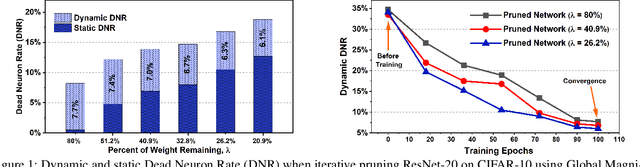

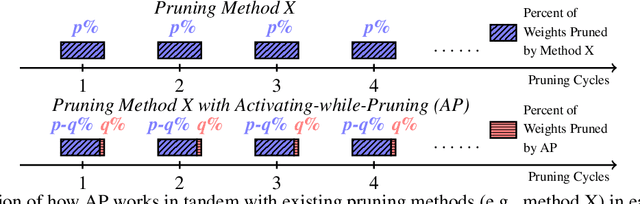

The rectified linear unit (ReLU) is a highly successful activation function in neural networks as it allows networks to easily obtain sparse representations, which reduces overfitting in overparameterized networks. However, in network pruning, we find that the sparsity introduced by ReLU, which we quantify by a term called dynamic dead neuron rate (DNR), is not beneficial for the pruned network. Interestingly, the more the network is pruned, the smaller the dynamic DNR becomes during optimization. This motivates us to propose a method to explicitly reduce the dynamic DNR for the pruned network, i.e., de-sparsify the network. We refer to our method as Activating-while-Pruning (AP). We note that AP does not function as a stand-alone method, as it does not evaluate the importance of weights. Instead, it works in tandem with existing pruning methods and aims to improve their performance by selective activation of nodes to reduce the dynamic DNR. We conduct extensive experiments using popular networks (e.g., ResNet, VGG) via two classical and three state-of-the-art pruning methods. The experimental results on public datasets (e.g., CIFAR-10/100) suggest that AP works well with existing pruning methods and improves the performance by 3% - 4%. For larger scale datasets (e.g., ImageNet) and state-of-the-art networks (e.g., vision transformer), we observe an improvement of 2% - 3% with AP as opposed to without. Lastly, we conduct an ablation study to examine the effectiveness of the components comprising AP.
Towards Better Long-range Time Series Forecasting using Generative Forecasting
Dec 09, 2022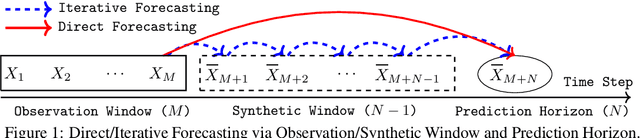
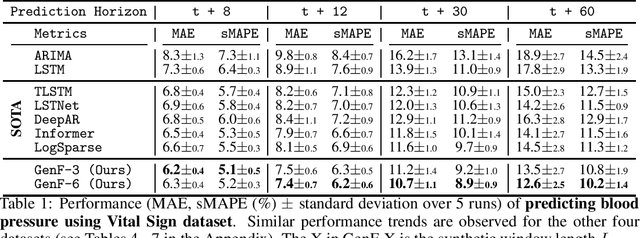
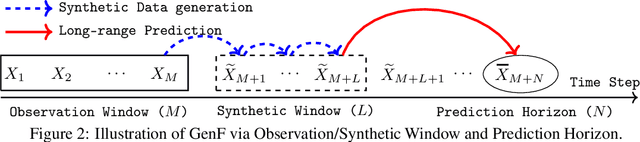

Long-range time series forecasting is usually based on one of two existing forecasting strategies: Direct Forecasting and Iterative Forecasting, where the former provides low bias, high variance forecasts and the latter leads to low variance, high bias forecasts. In this paper, we propose a new forecasting strategy called Generative Forecasting (GenF), which generates synthetic data for the next few time steps and then makes long-range forecasts based on generated and observed data. We theoretically prove that GenF is able to better balance the forecasting variance and bias, leading to a much smaller forecasting error. We implement GenF via three components: (i) a novel conditional Wasserstein Generative Adversarial Network (GAN) based generator for synthetic time series data generation, called CWGAN-TS. (ii) a transformer based predictor, which makes long-range predictions using both generated and observed data. (iii) an information theoretic clustering algorithm to improve the training of both the CWGAN-TS and the transformer based predictor. The experimental results on five public datasets demonstrate that GenF significantly outperforms a diverse range of state-of-the-art benchmarks and classical approaches. Specifically, we find a 5% - 11% improvement in predictive performance (mean absolute error) while having a 15% - 50% reduction in parameters compared to the benchmarks. Lastly, we conduct an ablation study to further explore and demonstrate the effectiveness of the components comprising GenF.
Achieving Low Complexity Neural Decoders via Iterative Pruning
Dec 11, 2021
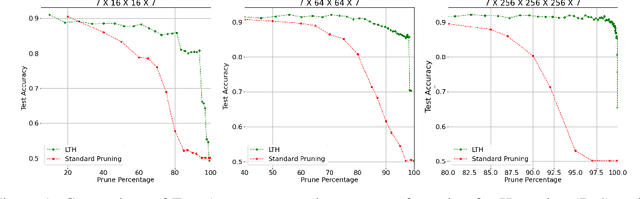
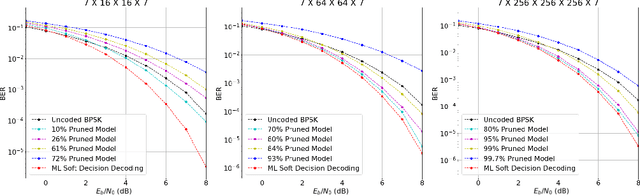
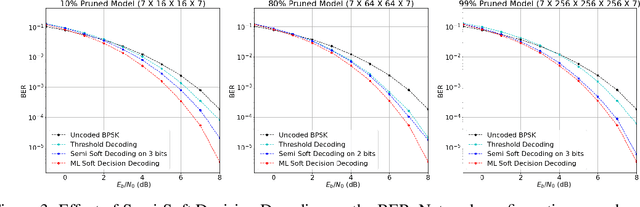
The advancement of deep learning has led to the development of neural decoders for low latency communications. However, neural decoders can be very complex which can lead to increased computation and latency. We consider iterative pruning approaches (such as the lottery ticket hypothesis algorithm) to prune weights in neural decoders. Decoders with fewer number of weights can have lower latency and lower complexity while retaining the accuracy of the original model. This will make neural decoders more suitable for mobile and other edge devices with limited computational power. We also propose semi-soft decision decoding for neural decoders which can be used to improve the bit error rate performance of the pruned network.
Investigating Convolutional Neural Networks using Spatial Orderness
Aug 18, 2019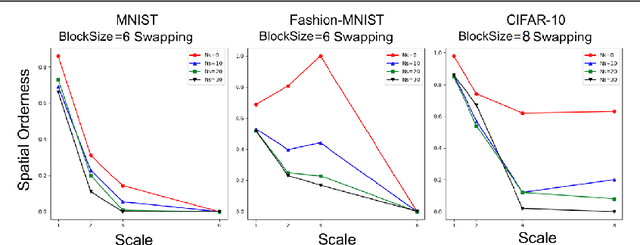
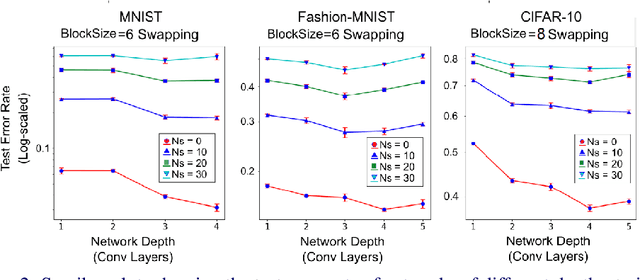
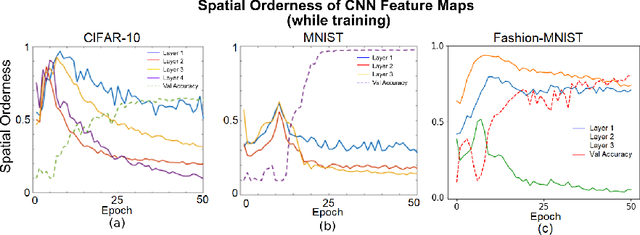
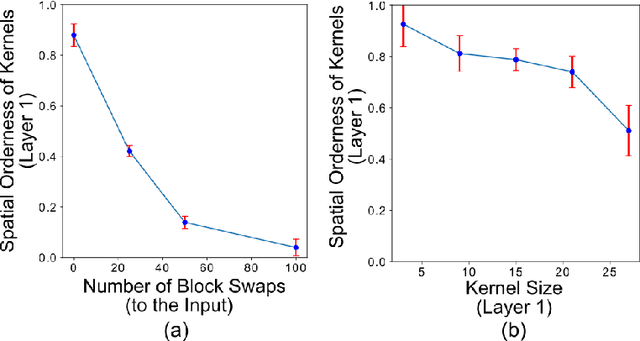
Convolutional Neural Networks (CNN) have been pivotal to the success of many state-of-the-art classification problems, in a wide variety of domains (for e.g. vision, speech, graphs and medical imaging). A commonality within those domains is the presence of hierarchical, spatially agglomerative local-to-global interactions within the data. For two-dimensional images, such interactions may induce an a priori relationship between the pixel data and the underlying spatial ordering of the pixels. For instance in natural images, neighboring pixels are more likely contain similar values than non-neighboring pixels which are further apart. To that end, we propose a statistical metric called spatial orderness, which quantifies the extent to which the input data (2D) obeys the underlying spatial ordering at various scales. In our experiments, we mainly find that adding convolutional layers to a CNN could be counterproductive for data bereft of spatial order at higher scales. We also observe, quite counter-intuitively, that the spatial orderness of CNN feature maps show a synchronized increase during the intial stages of training, and validation performance only improves after spatial orderness of feature maps start decreasing. Lastly, we present a theoretical analysis (and empirical validation) of the spatial orderness of network weights, where we find that using smaller kernel sizes leads to kernels of greater spatial orderness and vice-versa.
Scale Steerable Filters for Locally Scale-Invariant Convolutional Neural Networks
Jun 10, 2019
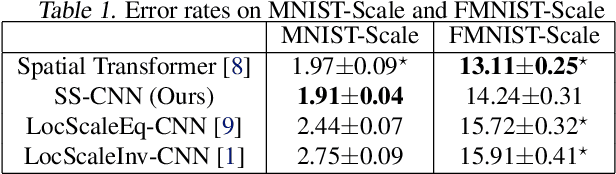
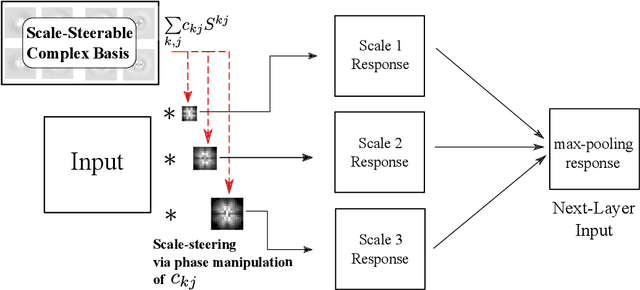
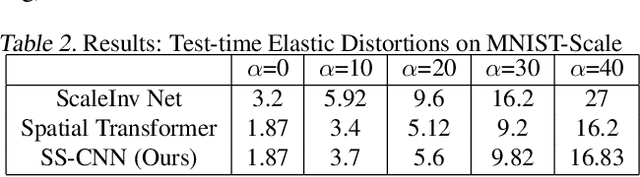
Augmenting transformation knowledge onto a convolutional neural network's weights has often yielded significant improvements in performance. For rotational transformation augmentation, an important element to recent approaches has been the use of a steerable basis i.e. the circular harmonics. Here, we propose a scale-steerable filter basis for the locally scale-invariant CNN, denoted as log-radial harmonics. By replacing the kernels in the locally scale-invariant CNN \cite{lsi_cnn} with scale-steered kernels, significant improvements in performance can be observed on the MNIST-Scale and FMNIST-Scale datasets. Training with a scale-steerable basis results in filters which show meaningful structure, and feature maps demonstrate which demonstrate visibly higher spatial-structure preservation of input. Furthermore, the proposed scale-steerable CNN shows on-par generalization to global affine transformation estimation methods such as Spatial Transformers, in response to test-time data distortions.
Pose-Invariant Object Recognition for Event-Based Vision with Slow-ELM
Mar 19, 2019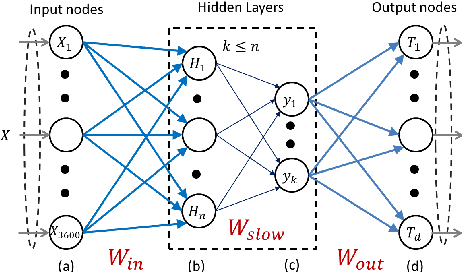
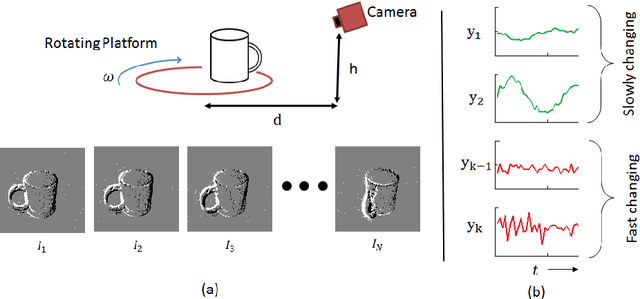
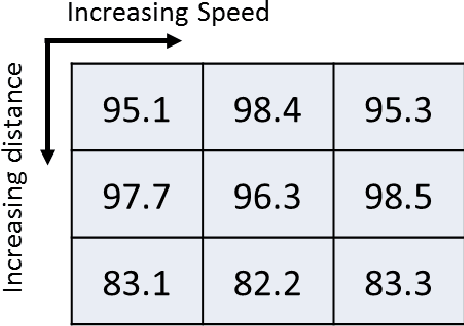
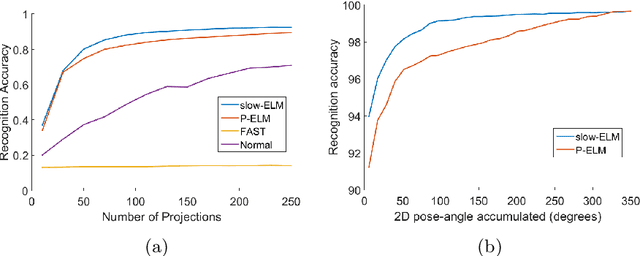
Neuromorphic image sensors produce activity-driven spiking output at every pixel. These low-power consuming imagers which encode visual change information in the form of spikes help reduce computational overhead and realize complex real-time systems; object recognition and pose-estimation to name a few. However, there exists a lack of algorithms in event-based vision aimed towards capturing invariance to transformations. In this work, we propose a methodology for recognizing objects invariant to their pose with the Dynamic Vision Sensor (DVS). A novel slow-ELM architecture is proposed which combines the effectiveness of Extreme Learning Machines and Slow Feature Analysis. The system, tested on an Intel Core i5-4590 CPU, can perform 10,000 classifications per second and achieves 1% classification error for 8 objects with views accumulated over 90 degrees of 2D pose.
Spatiotemporal Filtering for Event-Based Action Recognition
Mar 17, 2019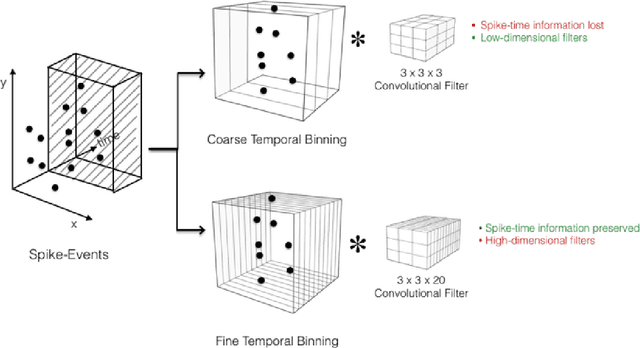
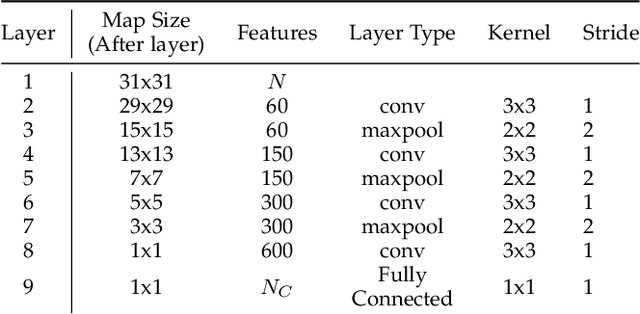
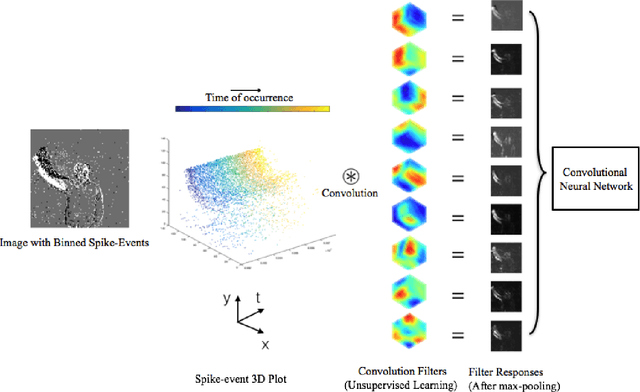
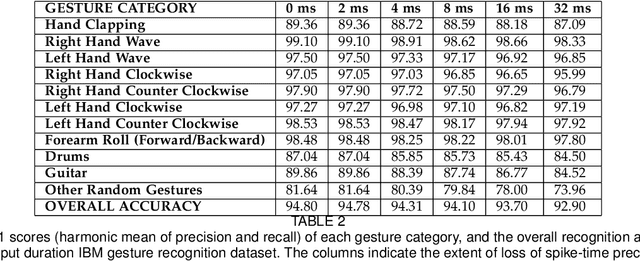
In this paper, we address the challenging problem of action recognition, using event-based cameras. To recognise most gestural actions, often higher temporal precision is required for sampling visual information. Actions are defined by motion, and therefore, when using event-based cameras it is often unnecessary to re-sample the entire scene. Neuromorphic, event-based cameras have presented an alternative to visual information acquisition by asynchronously time-encoding pixel intensity changes, through temporally precise spikes (10 micro-second resolution), making them well equipped for action recognition. However, other challenges exist, which are intrinsic to event-based imagers, such as higher signal-to-noise ratio, and a spatiotemporally sparse information. One option is to convert event-data into frames, but this could result in significant temporal precision loss. In this work we introduce spatiotemporal filtering in the spike-event domain, as an alternative way of channeling spatiotemporal information through to a convolutional neural network. The filters are local spatiotemporal weight matrices, learned from the spike-event data, in an unsupervised manner. We find that appropriate spatiotemporal filtering significantly improves CNN performance beyond state-of-the-art on the event-based DVS Gesture dataset. On our newly recorded action recognition dataset, our method shows significant improvement when compared with other, standard ways of generating the spatiotemporal filters.