 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTab-PET: Graph-Based Positional Encodings for Tabular Transformers
Nov 17, 2025Supervised learning with tabular data presents unique challenges, including low data sizes, the absence of structural cues, and heterogeneous features spanning both categorical and continuous domains. Unlike vision and language tasks, where models can exploit inductive biases in the data, tabular data lacks inherent positional structure, hindering the effectiveness of self-attention mechanisms. While recent transformer-based models like TabTransformer, SAINT, and FT-Transformer (which we refer to as 3T) have shown promise on tabular data, they typically operate without leveraging structural cues such as positional encodings (PEs), as no prior structural information is usually available. In this work, we find both theoretically and empirically that structural cues, specifically PEs can be a useful tool to improve generalization performance for tabular transformers. We find that PEs impart the ability to reduce the effective rank (a form of intrinsic dimensionality) of the features, effectively simplifying the task by reducing the dimensionality of the problem, yielding improved generalization. To that end, we propose Tab-PET (PEs for Tabular Transformers), a graph-based framework for estimating and inculcating PEs into embeddings. Inspired by approaches that derive PEs from graph topology, we explore two paradigms for graph estimation: association-based and causality-based. We empirically demonstrate that graph-derived PEs significantly improve performance across 50 classification and regression datasets for 3T. Notably, association-based graphs consistently yield more stable and pronounced gains compared to causality-driven ones. Our work highlights an unexpected role of PEs in tabular transformers, revealing how they can be harnessed to improve generalization.
Teaching the Teacher: Improving Neural Network Distillability for Symbolic Regression via Jacobian Regularization
Jul 30, 2025

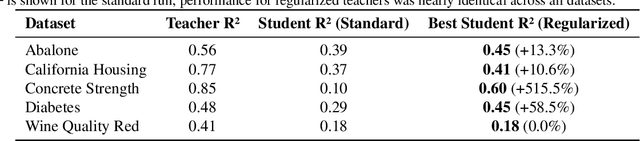

Distilling large neural networks into simple, human-readable symbolic formulas is a promising path toward trustworthy and interpretable AI. However, this process is often brittle, as the complex functions learned by standard networks are poor targets for symbolic discovery, resulting in low-fidelity student models. In this work, we propose a novel training paradigm to address this challenge. Instead of passively distilling a pre-trained network, we introduce a \textbf{Jacobian-based regularizer} that actively encourages the ``teacher'' network to learn functions that are not only accurate but also inherently smoother and more amenable to distillation. We demonstrate through extensive experiments on a suite of real-world regression benchmarks that our method is highly effective. By optimizing the regularization strength for each problem, we improve the $R^2$ score of the final distilled symbolic model by an average of \textbf{120\% (relative)} compared to the standard distillation pipeline, all while maintaining the teacher's predictive accuracy. Our work presents a practical and principled method for significantly improving the fidelity of interpretable models extracted from complex neural networks.
TaskGen: A Task-Based, Memory-Infused Agentic Framework using StrictJSON
Jul 22, 2024TaskGen is an open-sourced agentic framework which uses an Agent to solve an arbitrary task by breaking them down into subtasks. Each subtask is mapped to an Equipped Function or another Agent to execute. In order to reduce verbosity (and hence token usage), TaskGen uses StrictJSON that ensures JSON output from the Large Language Model (LLM), along with additional features such as type checking and iterative error correction. Key to the philosophy of TaskGen is the management of information/memory on a need-to-know basis. We empirically evaluate TaskGen on various environments such as 40x40 dynamic maze navigation with changing obstacle locations (100% solve rate), TextWorld escape room solving with dense rewards and detailed goals (96% solve rate), web browsing (69% of actions successful), solving the MATH dataset (71% solve rate over 100 Level-5 problems), Retrieval Augmented Generation on NaturalQuestions dataset (F1 score of 47.03%)
Large Language Model as a System of Multiple Expert Agents: An Approach to solve the Abstraction and Reasoning Corpus Challenge
Oct 08, 2023We attempt to solve the Abstraction and Reasoning Corpus (ARC) Challenge using Large Language Models (LLMs) as a system of multiple expert agents. Using the flexibility of LLMs to be prompted to do various novel tasks using zero-shot, few-shot, context-grounded prompting, we explore the feasibility of using LLMs to solve the ARC Challenge. We firstly convert the input image into multiple suitable text-based abstraction spaces. We then utilise the associative power of LLMs to derive the input-output relationship and map this to actions in the form of a working program, similar to Voyager / Ghost in the MineCraft. In addition, we use iterative environmental feedback in order to guide LLMs to solve the task. Our proposed approach achieves 50 solves out of 111 training set problems (45%) with just three abstraction spaces - grid, object and pixel - and we believe that with more abstraction spaces and learnable actions, we will be able to solve more.
Local Intrinsic Dimensional Entropy
Apr 06, 2023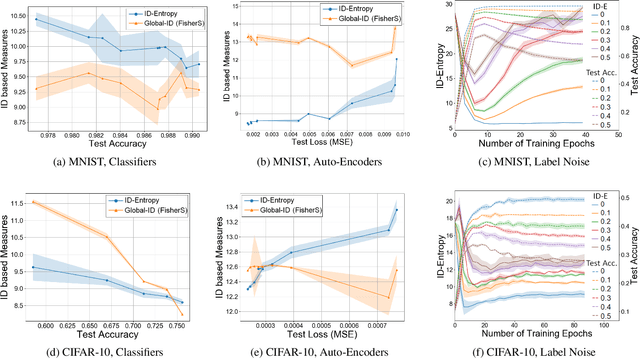
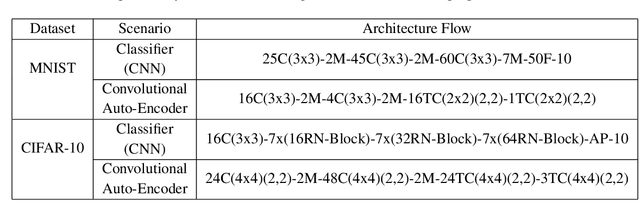
Most entropy measures depend on the spread of the probability distribution over the sample space X, and the maximum entropy achievable scales proportionately with the sample space cardinality |X|. For a finite |X|, this yields robust entropy measures which satisfy many important properties, such as invariance to bijections, while the same is not true for continuous spaces (where |X|=infinity). Furthermore, since R and R^d (d in Z+) have the same cardinality (from Cantor's correspondence argument), cardinality-dependent entropy measures cannot encode the data dimensionality. In this work, we question the role of cardinality and distribution spread in defining entropy measures for continuous spaces, which can undergo multiple rounds of transformations and distortions, e.g., in neural networks. We find that the average value of the local intrinsic dimension of a distribution, denoted as ID-Entropy, can serve as a robust entropy measure for continuous spaces, while capturing the data dimensionality. We find that ID-Entropy satisfies many desirable properties and can be extended to conditional entropy, joint entropy and mutual-information variants. ID-Entropy also yields new information bottleneck principles and also links to causality. In the context of deep learning, for feedforward architectures, we show, theoretically and empirically, that the ID-Entropy of a hidden layer directly controls the generalization gap for both classifiers and auto-encoders, when the target function is Lipschitz continuous. Our work primarily shows that, for continuous spaces, taking a structural rather than a statistical approach yields entropy measures which preserve intrinsic data dimensionality, while being relevant for studying various architectures.
Learning, Fast and Slow: A Goal-Directed Memory-Based Approach for Dynamic Environments
Feb 01, 2023



Model-based next state prediction and state value prediction are slow to converge. To address these challenges, we do the following: i) Instead of a neural network, we do model-based planning using a parallel memory retrieval system (which we term the slow mechanism); ii) Instead of learning state values, we guide the agent's actions using goal-directed exploration, by using a neural network to choose the next action given the current state and the goal state (which we term the fast mechanism). The goal-directed exploration is trained online using hippocampal replay of visited states and future imagined states every single time step, leading to fast and efficient training. Empirical studies show that our proposed method has a 92% solve rate across 100 episodes in a dynamically changing grid world, significantly outperforming state-of-the-art actor critic mechanisms such as PPO (54%), TRPO (50%) and A2C (24%). Ablation studies demonstrate that both mechanisms are crucial. We posit that the future of Reinforcement Learning (RL) will be to model goals and sub-goals for various tasks, and plan it out in a goal-directed memory-based approach.
Improving Mutual Information based Feature Selection by Boosting Unique Relevance
Dec 17, 2022

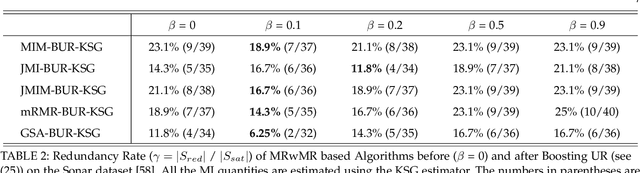

Mutual Information (MI) based feature selection makes use of MI to evaluate each feature and eventually shortlists a relevant feature subset, in order to address issues associated with high-dimensional datasets. Despite the effectiveness of MI in feature selection, we notice that many state-of-the-art algorithms disregard the so-called unique relevance (UR) of features, and arrive at a suboptimal selected feature subset which contains a non-negligible number of redundant features. We point out that the heart of the problem is that all these MIBFS algorithms follow the criterion of Maximize Relevance with Minimum Redundancy (MRwMR), which does not explicitly target UR. This motivates us to augment the existing criterion with the objective of boosting unique relevance (BUR), leading to a new criterion called MRwMR-BUR. Depending on the task being addressed, MRwMR-BUR has two variants, termed MRwMR-BUR-KSG and MRwMR-BUR-CLF, which estimate UR differently. MRwMR-BUR-KSG estimates UR via a nearest-neighbor based approach called the KSG estimator and is designed for three major tasks: (i) Classification Performance. (ii) Feature Interpretability. (iii) Classifier Generalization. MRwMR-BUR-CLF estimates UR via a classifier based approach. It adapts UR to different classifiers, further improving the competitiveness of MRwMR-BUR for classification performance oriented tasks. The performance of both MRwMR-BUR-KSG and MRwMR-BUR-CLF is validated via experiments using six public datasets and three popular classifiers. Specifically, as compared to MRwMR, the proposed MRwMR-BUR-KSG improves the test accuracy by 2% - 3% with 25% - 30% fewer features being selected, without increasing the algorithm complexity. MRwMR-BUR-CLF further improves the classification performance by 3.8%- 5.5% (relative to MRwMR), and it also outperforms three popular classifier dependent feature selection methods.
AP: Selective Activation for De-sparsifying Pruned Neural Networks
Dec 09, 2022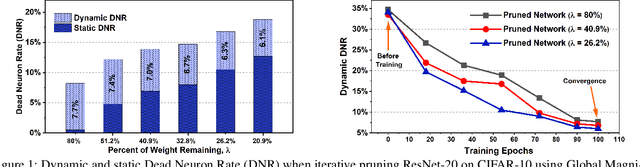

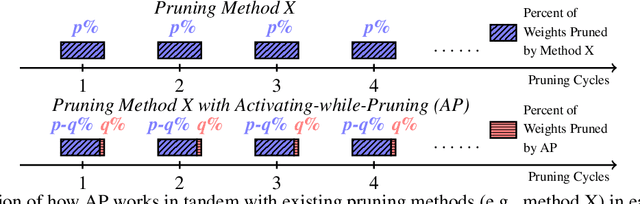

The rectified linear unit (ReLU) is a highly successful activation function in neural networks as it allows networks to easily obtain sparse representations, which reduces overfitting in overparameterized networks. However, in network pruning, we find that the sparsity introduced by ReLU, which we quantify by a term called dynamic dead neuron rate (DNR), is not beneficial for the pruned network. Interestingly, the more the network is pruned, the smaller the dynamic DNR becomes during optimization. This motivates us to propose a method to explicitly reduce the dynamic DNR for the pruned network, i.e., de-sparsify the network. We refer to our method as Activating-while-Pruning (AP). We note that AP does not function as a stand-alone method, as it does not evaluate the importance of weights. Instead, it works in tandem with existing pruning methods and aims to improve their performance by selective activation of nodes to reduce the dynamic DNR. We conduct extensive experiments using popular networks (e.g., ResNet, VGG) via two classical and three state-of-the-art pruning methods. The experimental results on public datasets (e.g., CIFAR-10/100) suggest that AP works well with existing pruning methods and improves the performance by 3% - 4%. For larger scale datasets (e.g., ImageNet) and state-of-the-art networks (e.g., vision transformer), we observe an improvement of 2% - 3% with AP as opposed to without. Lastly, we conduct an ablation study to examine the effectiveness of the components comprising AP.
Optimizing Learning Rate Schedules for Iterative Pruning of Deep Neural Networks
Dec 09, 2022



The importance of learning rate (LR) schedules on network pruning has been observed in a few recent works. As an example, Frankle and Carbin (2019) highlighted that winning tickets (i.e., accuracy preserving subnetworks) can not be found without applying a LR warmup schedule and Renda, Frankle and Carbin (2020) demonstrated that rewinding the LR to its initial state at the end of each pruning cycle improves performance. In this paper, we go one step further by first providing a theoretical justification for the surprising effect of LR schedules. Next, we propose a LR schedule for network pruning called SILO, which stands for S-shaped Improved Learning rate Optimization. The advantages of SILO over existing state-of-the-art (SOTA) LR schedules are two-fold: (i) SILO has a strong theoretical motivation and dynamically adjusts the LR during pruning to improve generalization. Specifically, SILO increases the LR upper bound (max_lr) in an S-shape. This leads to an improvement of 2% - 4% in extensive experiments with various types of networks (e.g., Vision Transformers, ResNet) on popular datasets such as ImageNet, CIFAR-10/100. (ii) In addition to the strong theoretical motivation, SILO is empirically optimal in the sense of matching an Oracle, which exhaustively searches for the optimal value of max_lr via grid search. We find that SILO is able to precisely adjust the value of max_lr to be within the Oracle optimized interval, resulting in performance competitive with the Oracle with significantly lower complexity.
Towards Better Long-range Time Series Forecasting using Generative Forecasting
Dec 09, 2022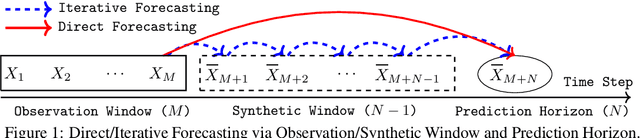
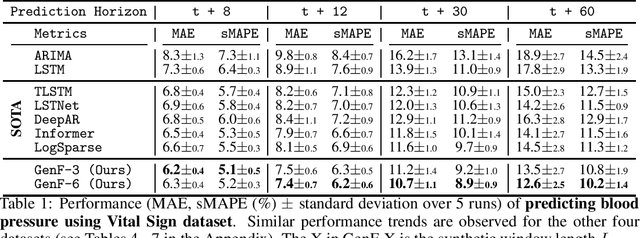
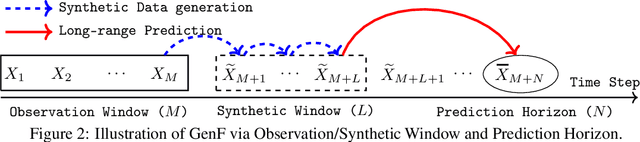

Long-range time series forecasting is usually based on one of two existing forecasting strategies: Direct Forecasting and Iterative Forecasting, where the former provides low bias, high variance forecasts and the latter leads to low variance, high bias forecasts. In this paper, we propose a new forecasting strategy called Generative Forecasting (GenF), which generates synthetic data for the next few time steps and then makes long-range forecasts based on generated and observed data. We theoretically prove that GenF is able to better balance the forecasting variance and bias, leading to a much smaller forecasting error. We implement GenF via three components: (i) a novel conditional Wasserstein Generative Adversarial Network (GAN) based generator for synthetic time series data generation, called CWGAN-TS. (ii) a transformer based predictor, which makes long-range predictions using both generated and observed data. (iii) an information theoretic clustering algorithm to improve the training of both the CWGAN-TS and the transformer based predictor. The experimental results on five public datasets demonstrate that GenF significantly outperforms a diverse range of state-of-the-art benchmarks and classical approaches. Specifically, we find a 5% - 11% improvement in predictive performance (mean absolute error) while having a 15% - 50% reduction in parameters compared to the benchmarks. Lastly, we conduct an ablation study to further explore and demonstrate the effectiveness of the components comprising GenF.