 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Mutual Information based Feature Selection by Boosting Unique Relevance
Paper and Code
Dec 17, 2022

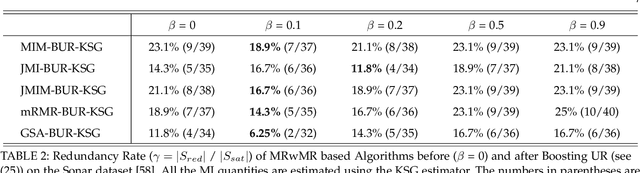

Mutual Information (MI) based feature selection makes use of MI to evaluate each feature and eventually shortlists a relevant feature subset, in order to address issues associated with high-dimensional datasets. Despite the effectiveness of MI in feature selection, we notice that many state-of-the-art algorithms disregard the so-called unique relevance (UR) of features, and arrive at a suboptimal selected feature subset which contains a non-negligible number of redundant features. We point out that the heart of the problem is that all these MIBFS algorithms follow the criterion of Maximize Relevance with Minimum Redundancy (MRwMR), which does not explicitly target UR. This motivates us to augment the existing criterion with the objective of boosting unique relevance (BUR), leading to a new criterion called MRwMR-BUR. Depending on the task being addressed, MRwMR-BUR has two variants, termed MRwMR-BUR-KSG and MRwMR-BUR-CLF, which estimate UR differently. MRwMR-BUR-KSG estimates UR via a nearest-neighbor based approach called the KSG estimator and is designed for three major tasks: (i) Classification Performance. (ii) Feature Interpretability. (iii) Classifier Generalization. MRwMR-BUR-CLF estimates UR via a classifier based approach. It adapts UR to different classifiers, further improving the competitiveness of MRwMR-BUR for classification performance oriented tasks. The performance of both MRwMR-BUR-KSG and MRwMR-BUR-CLF is validated via experiments using six public datasets and three popular classifiers. Specifically, as compared to MRwMR, the proposed MRwMR-BUR-KSG improves the test accuracy by 2% - 3% with 25% - 30% fewer features being selected, without increasing the algorithm complexity. MRwMR-BUR-CLF further improves the classification performance by 3.8%- 5.5% (relative to MRwMR), and it also outperforms three popular classifier dependent feature selection methods.