 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Learning Rate Schedules for Iterative Pruning of Deep Neural Networks
Dec 09, 2022



The importance of learning rate (LR) schedules on network pruning has been observed in a few recent works. As an example, Frankle and Carbin (2019) highlighted that winning tickets (i.e., accuracy preserving subnetworks) can not be found without applying a LR warmup schedule and Renda, Frankle and Carbin (2020) demonstrated that rewinding the LR to its initial state at the end of each pruning cycle improves performance. In this paper, we go one step further by first providing a theoretical justification for the surprising effect of LR schedules. Next, we propose a LR schedule for network pruning called SILO, which stands for S-shaped Improved Learning rate Optimization. The advantages of SILO over existing state-of-the-art (SOTA) LR schedules are two-fold: (i) SILO has a strong theoretical motivation and dynamically adjusts the LR during pruning to improve generalization. Specifically, SILO increases the LR upper bound (max_lr) in an S-shape. This leads to an improvement of 2% - 4% in extensive experiments with various types of networks (e.g., Vision Transformers, ResNet) on popular datasets such as ImageNet, CIFAR-10/100. (ii) In addition to the strong theoretical motivation, SILO is empirically optimal in the sense of matching an Oracle, which exhaustively searches for the optimal value of max_lr via grid search. We find that SILO is able to precisely adjust the value of max_lr to be within the Oracle optimized interval, resulting in performance competitive with the Oracle with significantly lower complexity.
DropNet: Reducing Neural Network Complexity via Iterative Pruning
Jul 14, 2022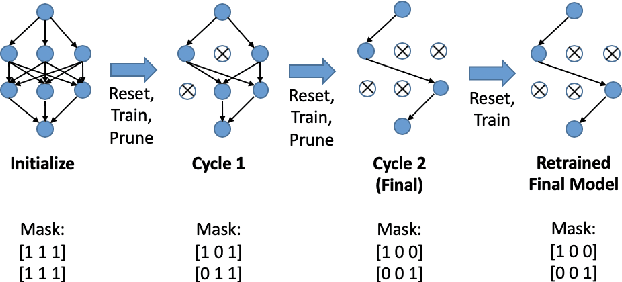

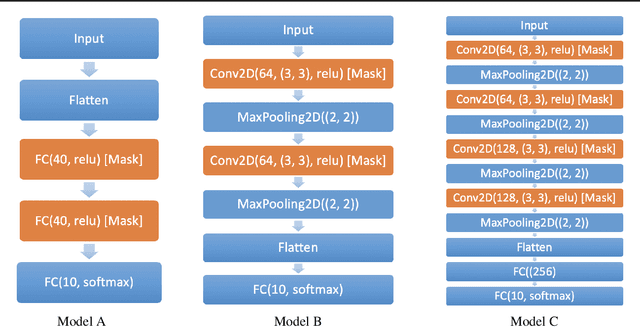
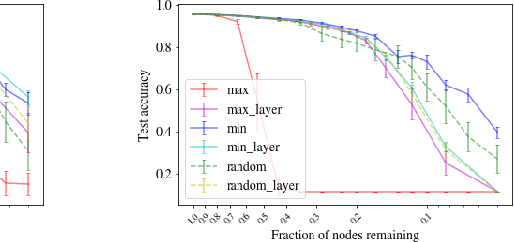
Modern deep neural networks require a significant amount of computing time and power to train and deploy, which limits their usage on edge devices. Inspired by the iterative weight pruning in the Lottery Ticket Hypothesis, we propose DropNet, an iterative pruning method which prunes nodes/filters to reduce network complexity. DropNet iteratively removes nodes/filters with the lowest average post-activation value across all training samples. Empirically, we show that DropNet is robust across diverse scenarios, including MLPs and CNNs using the MNIST, CIFAR-10 and Tiny ImageNet datasets. We show that up to 90% of the nodes/filters can be removed without any significant loss of accuracy. The final pruned network performs well even with reinitialization of the weights and biases. DropNet also has similar accuracy to an oracle which greedily removes nodes/filters one at a time to minimise training loss, highlighting its effectiveness.
* Published at ICML 2020. Code can be found at https://github.com/tanchongmin/DropNet
Brick Tic-Tac-Toe: Exploring the Generalizability of AlphaZero to Novel Test Environments
Jul 14, 2022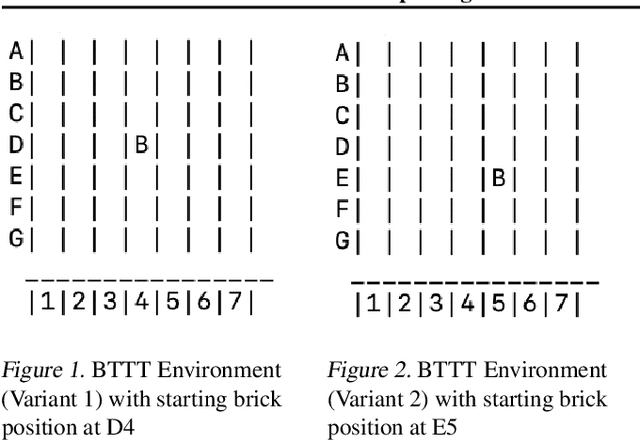

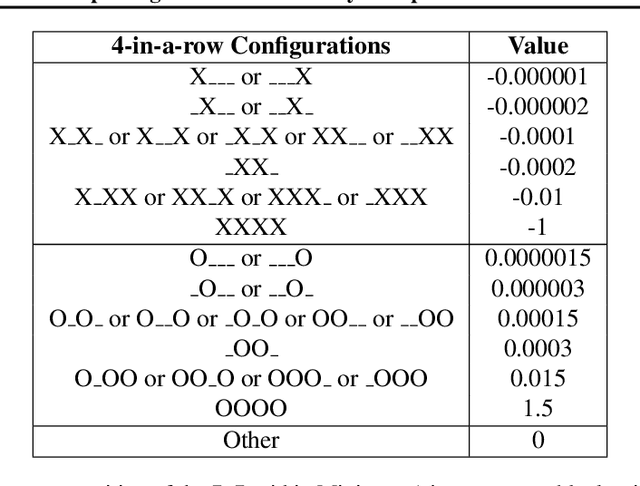

Traditional reinforcement learning (RL) environments typically are the same for both the training and testing phases. Hence, current RL methods are largely not generalizable to a test environment which is conceptually similar but different from what the method has been trained on, which we term the novel test environment. As an effort to push RL research towards algorithms which can generalize to novel test environments, we introduce the Brick Tic-Tac-Toe (BTTT) test bed, where the brick position in the test environment is different from that in the training environment. Using a round-robin tournament on the BTTT environment, we show that traditional RL state-search approaches such as Monte Carlo Tree Search (MCTS) and Minimax are more generalizable to novel test environments than AlphaZero is. This is surprising because AlphaZero has been shown to achieve superhuman performance in environments such as Go, Chess and Shogi, which may lead one to think that it performs well in novel test environments. Our results show that BTTT, though simple, is rich enough to explore the generalizability of AlphaZero. We find that merely increasing MCTS lookahead iterations was insufficient for AlphaZero to generalize to some novel test environments. Rather, increasing the variety of training environments helps to progressively improve generalizability across all possible starting brick configurations.