 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Gradient Descent with Small Epoch Counts is Surprisingly Slow on Ill-Conditioned Problems
Jun 04, 2025Recent theoretical results demonstrate that the convergence rates of permutation-based SGD (e.g., random reshuffling SGD) are faster than uniform-sampling SGD; however, these studies focus mainly on the large epoch regime, where the number of epochs $K$ exceeds the condition number $\kappa$. In contrast, little is known when $K$ is smaller than $\kappa$, and it is still a challenging open question whether permutation-based SGD can converge faster in this small epoch regime (Safran and Shamir, 2021). As a step toward understanding this gap, we study the naive deterministic variant, Incremental Gradient Descent (IGD), on smooth and strongly convex functions. Our lower bounds reveal that for the small epoch regime, IGD can exhibit surprisingly slow convergence even when all component functions are strongly convex. Furthermore, when some component functions are allowed to be nonconvex, we prove that the optimality gap of IGD can be significantly worse throughout the small epoch regime. Our analyses reveal that the convergence properties of permutation-based SGD in the small epoch regime may vary drastically depending on the assumptions on component functions. Lastly, we supplement the paper with tight upper and lower bounds for IGD in the large epoch regime.
Arithmetic Transformers Can Length-Generalize in Both Operand Length and Count
Oct 21, 2024Transformers often struggle with length generalization, meaning they fail to generalize to sequences longer than those encountered during training. While arithmetic tasks are commonly used to study length generalization, certain tasks are considered notoriously difficult, e.g., multi-operand addition (requiring generalization over both the number of operands and their lengths) and multiplication (requiring generalization over both operand lengths). In this work, we achieve approximately 2-3x length generalization on both tasks, which is the first such achievement in arithmetic Transformers. We design task-specific scratchpads enabling the model to focus on a fixed number of tokens per each next-token prediction step, and apply multi-level versions of Position Coupling (Cho et al., 2024; McLeish et al., 2024) to let Transformers know the right position to attend to. On the theory side, we prove that a 1-layer Transformer using our method can solve multi-operand addition, up to operand length and operand count that are exponential in embedding dimension.
Position Coupling: Leveraging Task Structure for Improved Length Generalization of Transformers
May 31, 2024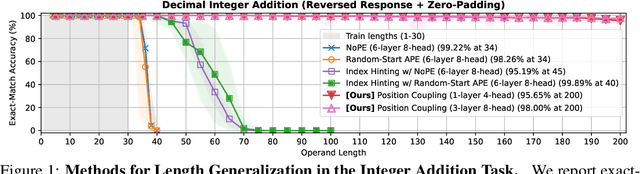

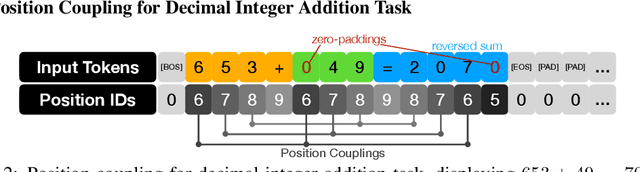
Even for simple arithmetic tasks like integer addition, it is challenging for Transformers to generalize to longer sequences than those encountered during training. To tackle this problem, we propose position coupling, a simple yet effective method that directly embeds the structure of the tasks into the positional encoding of a (decoder-only) Transformer. Taking a departure from the vanilla absolute position mechanism assigning unique position IDs to each of the tokens, we assign the same position IDs to two or more "relevant" tokens; for integer addition tasks, we regard digits of the same significance as in the same position. On the empirical side, we show that with the proposed position coupling, a small (1-layer) Transformer trained on 1 to 30-digit additions can generalize up to 200-digit additions (6.67x of the trained length). On the theoretical side, we prove that a 1-layer Transformer with coupled positions can solve the addition task involving exponentially many digits, whereas any 1-layer Transformer without positional information cannot entirely solve it. We also demonstrate that position coupling can be applied to other algorithmic tasks such as addition with multiple summands, Nx2 multiplication, copy/reverse, and a two-dimensional task.
Tighter Lower Bounds for Shuffling SGD: Random Permutations and Beyond
Mar 13, 2023We study convergence lower bounds of without-replacement stochastic gradient descent (SGD) for solving smooth (strongly-)convex finite-sum minimization problems. Unlike most existing results focusing on final iterate lower bounds in terms of the number of components $n$ and the number of epochs $K$, we seek bounds for arbitrary weighted average iterates that are tight in all factors including the condition number $\kappa$. For SGD with Random Reshuffling, we present lower bounds that have tighter $\kappa$ dependencies than existing bounds. Our results are the first to perfectly close the gap between lower and upper bounds for weighted average iterates in both strongly-convex and convex cases. We also prove weighted average iterate lower bounds for arbitrary permutation-based SGD, which apply to all variants that carefully choose the best permutation. Our bounds improve the existing bounds in factors of $n$ and $\kappa$ and thereby match the upper bounds shown for a recently proposed algorithm called GraB.