 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Mixtera: A Data Plane for Foundation Model Training
Feb 27, 2025State-of-the-art large language and vision models are trained over trillions of tokens that are aggregated from a large variety of sources. As training data collections grow, manually managing the samples becomes time-consuming, tedious, and prone to errors. Yet recent research shows that the data mixture and the order in which samples are visited during training can significantly influence model accuracy. We build and present Mixtera, a data plane for foundation model training that enables users to declaratively express which data samples should be used in which proportion and in which order during training. Mixtera is a centralized, read-only layer that is deployed on top of existing training data collections and can be declaratively queried. It operates independently of the filesystem structure and supports mixtures across arbitrary properties (e.g., language, source dataset) as well as dynamic adjustment of the mixture based on model feedback. We experimentally evaluate Mixtera and show that our implementation does not bottleneck training and scales to 256 GH200 superchips. We demonstrate how Mixtera supports recent advancements in mixing strategies by implementing the proposed Adaptive Data Optimization (ADO) algorithm in the system and evaluating its performance impact. We also explore the role of mixtures for vision-language models.
On Distributed Larger-Than-Memory Subset Selection With Pairwise Submodular Functions
Feb 26, 2024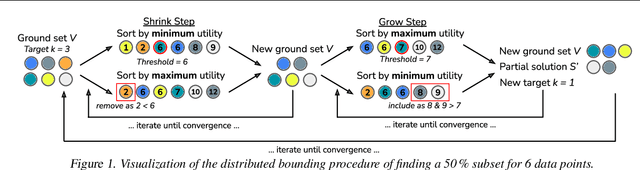
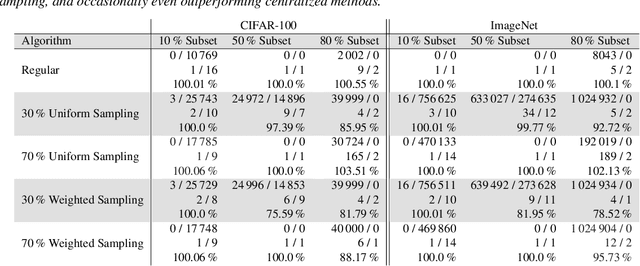

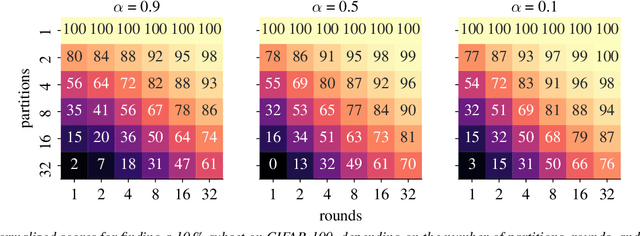
Many learning problems hinge on the fundamental problem of subset selection, i.e., identifying a subset of important and representative points. For example, selecting the most significant samples in ML training cannot only reduce training costs but also enhance model quality. Submodularity, a discrete analogue of convexity, is commonly used for solving subset selection problems. However, existing algorithms for optimizing submodular functions are sequential, and the prior distributed methods require at least one central machine to fit the target subset. In this paper, we relax the requirement of having a central machine for the target subset by proposing a novel distributed bounding algorithm with provable approximation guarantees. The algorithm iteratively bounds the minimum and maximum utility values to select high quality points and discard the unimportant ones. When bounding does not find the complete subset, we use a multi-round, partition-based distributed greedy algorithm to identify the remaining subset. We show that these algorithms find high quality subsets on CIFAR-100 and ImageNet with marginal or no loss in quality compared to centralized methods, and scale to a dataset with 13 billion points.
Modyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Dec 11, 2023


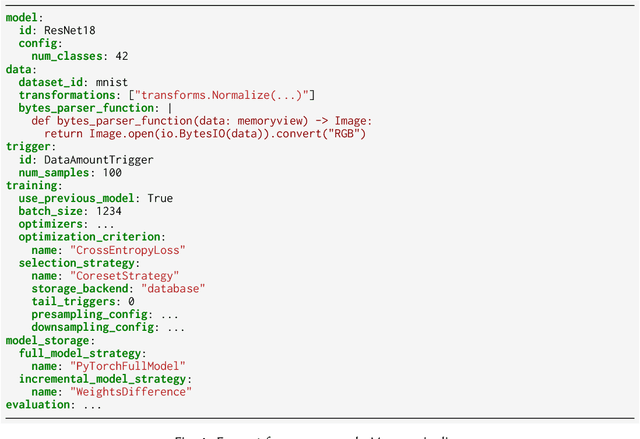
Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.
What's Wrong with Deep Learning in Tree Search for Combinatorial Optimization
Jan 25, 2022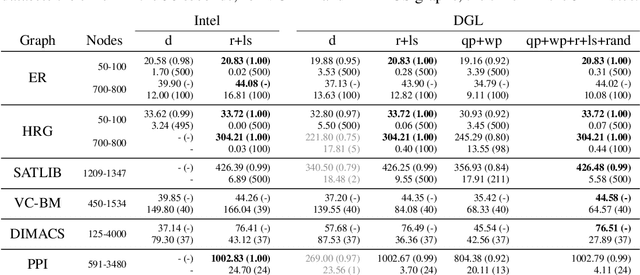
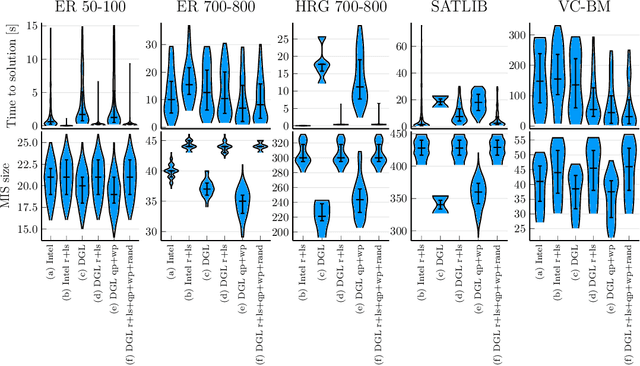
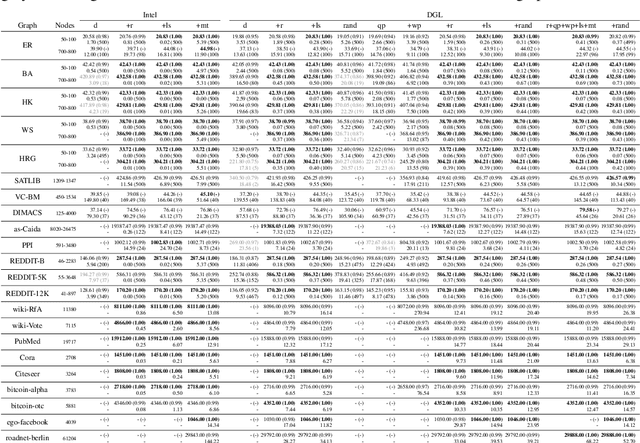
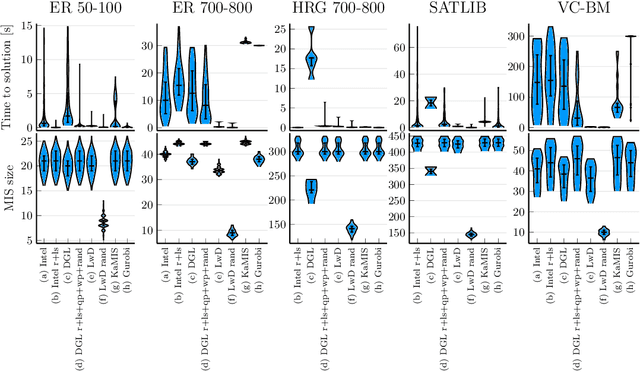
Combinatorial optimization lies at the core of many real-world problems. Especially since the rise of graph neural networks (GNNs), the deep learning community has been developing solvers that derive solutions to NP-hard problems by learning the problem-specific solution structure. However, reproducing the results of these publications proves to be difficult. We make three contributions. First, we present an open-source benchmark suite for the NP-hard Maximum Independent Set problem, in both its weighted and unweighted variants. The suite offers a unified interface to various state-of-the-art traditional and machine learning-based solvers. Second, using our benchmark suite, we conduct an in-depth analysis of the popular guided tree search algorithm by Li et al. [NeurIPS 2018], testing various configurations on small and large synthetic and real-world graphs. By re-implementing their algorithm with a focus on code quality and extensibility, we show that the graph convolution network used in the tree search does not learn a meaningful representation of the solution structure, and can in fact be replaced by random values. Instead, the tree search relies on algorithmic techniques like graph kernelization to find good solutions. Thus, the results from the original publication are not reproducible. Third, we extend the analysis to compare the tree search implementations to other solvers, showing that the classical algorithmic solvers often are faster, while providing solutions of similar quality. Additionally, we analyze a recent solver based on reinforcement learning and observe that for this solver, the GNN is responsible for the competitive solution quality.
Law Smells: Defining and Detecting Problematic Patterns in Legal Drafting
Oct 15, 2021Building on the computer science concept of code smells, we initiate the study of law smells, i.e., patterns in legal texts that pose threats to the comprehensibility and maintainability of the law. With five intuitive law smells as running examples - namely, duplicated phrase, long element, large reference tree, ambiguous syntax, and natural language obsession -, we develop a comprehensive law smell taxonomy. This taxonomy classifies law smells by when they can be detected, which aspects of law they relate to, and how they can be discovered. We introduce text-based and graph-based methods to identify instances of law smells, confirming their utility in practice using the United States Code as a test case. Our work demonstrates how ideas from software engineering can be leveraged to assess and improve the quality of legal code, thus drawing attention to an understudied area in the intersection of law and computer science and highlighting the potential of computational legal drafting.
Maps for Learning Indexable Classes
Oct 15, 2020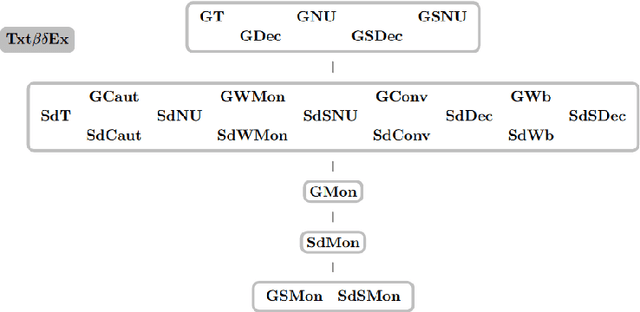
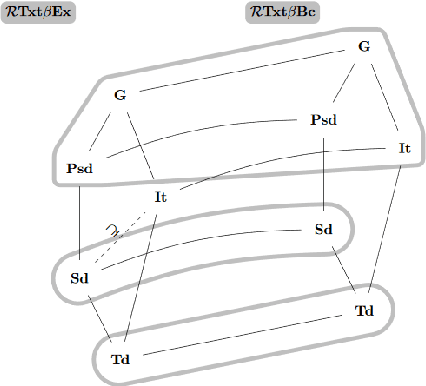
We study learning of indexed families from positive data where a learner can freely choose a hypothesis space (with uniformly decidable membership) comprising at least the languages to be learned. This abstracts a very universal learning task which can be found in many areas, for example learning of (subsets of) regular languages or learning of natural languages. We are interested in various restrictions on learning, such as consistency, conservativeness or set-drivenness, exemplifying various natural learning restrictions. Building on previous results from the literature, we provide several maps (depictions of all pairwise relations) of various groups of learning criteria, including a map for monotonicity restrictions and similar criteria and a map for restrictions on data presentation. Furthermore, we consider, for various learning criteria, whether learners can be assumed consistent.