 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Metric to Rule Them All: Toward Principled Evaluations of Graph-Learning Datasets
Feb 04, 2025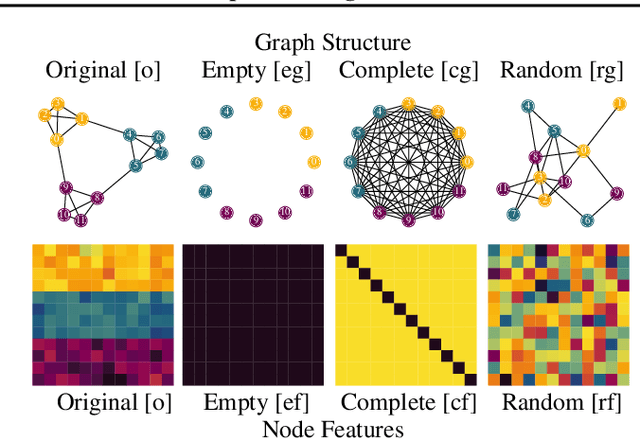
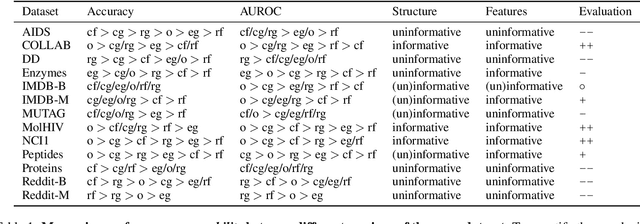
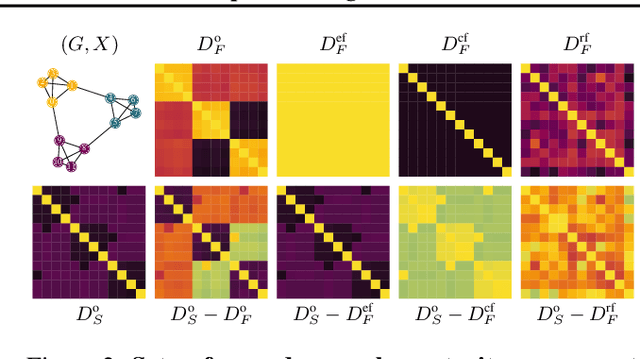
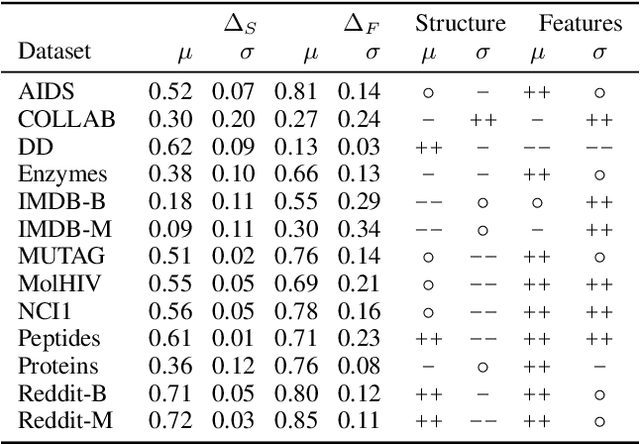
Benchmark datasets have proved pivotal to the success of graph learning, and good benchmark datasets are crucial to guide the development of the field. Recent research has highlighted problems with graph-learning datasets and benchmarking practices -- revealing, for example, that methods which ignore the graph structure can outperform graph-based approaches on popular benchmark datasets. Such findings raise two questions: (1) What makes a good graph-learning dataset, and (2) how can we evaluate dataset quality in graph learning? Our work addresses these questions. As the classic evaluation setup uses datasets to evaluate models, it does not apply to dataset evaluation. Hence, we start from first principles. Observing that graph-learning datasets uniquely combine two modes -- the graph structure and the node features -- , we introduce RINGS, a flexible and extensible mode-perturbation framework to assess the quality of graph-learning datasets based on dataset ablations -- i.e., by quantifying differences between the original dataset and its perturbed representations. Within this framework, we propose two measures -- performance separability and mode complementarity -- as evaluation tools, each assessing, from a distinct angle, the capacity of a graph dataset to benchmark the power and efficacy of graph-learning methods. We demonstrate the utility of our framework for graph-learning dataset evaluation in an extensive set of experiments and derive actionable recommendations for improving the evaluation of graph-learning methods. Our work opens new research directions in data-centric graph learning, and it constitutes a first step toward the systematic evaluation of evaluations.
Mapping the Multiverse of Latent Representations
Feb 02, 2024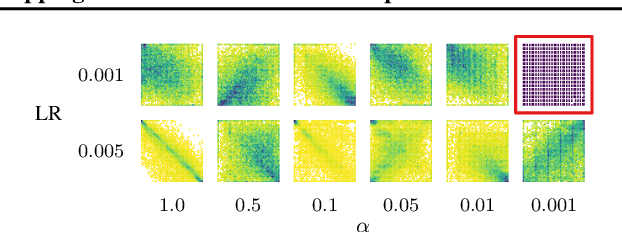

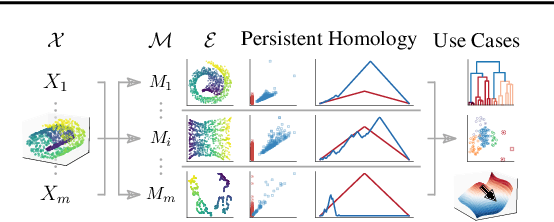

Echoing recent calls to counter reliability and robustness concerns in machine learning via multiverse analysis, we present PRESTO, a principled framework for mapping the multiverse of machine-learning models that rely on latent representations. Although such models enjoy widespread adoption, the variability in their embeddings remains poorly understood, resulting in unnecessary complexity and untrustworthy representations. Our framework uses persistent homology to characterize the latent spaces arising from different combinations of diverse machine-learning methods, (hyper)parameter configurations, and datasets, allowing us to measure their pairwise (dis)similarity and statistically reason about their distributions. As we demonstrate both theoretically and empirically, our pipeline preserves desirable properties of collections of latent representations, and it can be leveraged to perform sensitivity analysis, detect anomalous embeddings, or efficiently and effectively navigate hyperparameter search spaces.
Evaluating the "Learning on Graphs" Conference Experience
Jun 01, 2023With machine learning conferences growing ever larger, and reviewing processes becoming increasingly elaborate, more data-driven insights into their workings are required. In this report, we present the results of a survey accompanying the first "Learning on Graphs" (LoG) Conference. The survey was directed to evaluate the submission and review process from different perspectives, including authors, reviewers, and area chairs alike.
All the World's a Graph: A Data Drama
Jun 17, 2022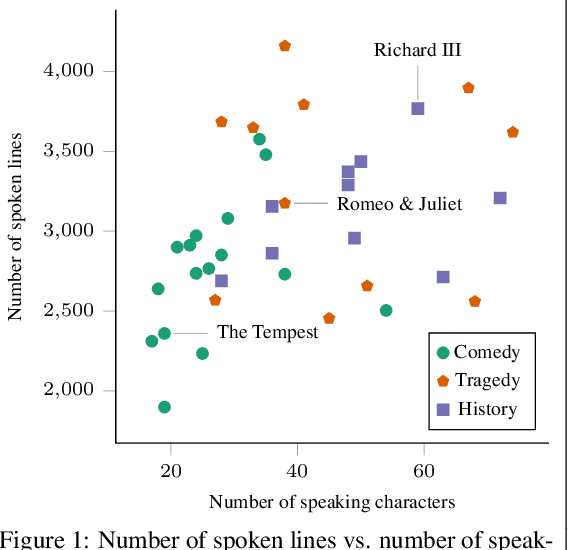
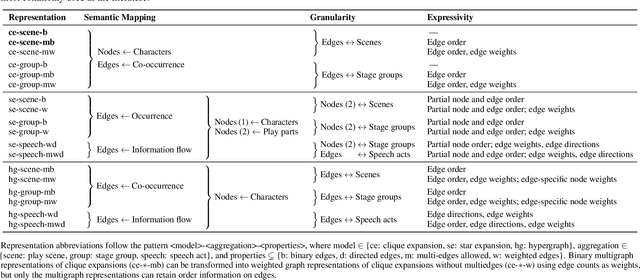


We introduce Hyperbard, a dataset of diverse relational data representations derived from Shakespeare's plays. Our representations range from simple graphs capturing character co-occurrence in single scenes to hypergraphs encoding complex communication settings and character contributions as hyperedges with edge-specific node weights. By making multiple intuitive representations readily available for experimentation, we facilitate rigorous representation robustness checks in graph learning, graph mining, and network analysis, highlighting the advantages and drawbacks of specific representations. Leveraging the data released in Hyperbard, we demonstrate that many solutions to popular graph mining problems are highly dependent on the representation choice, thus calling current graph curation practices into question. As an homage to our data source, and asserting that science can also be art, we present all our points in the form of a play.
Differentially Describing Groups of Graphs
Dec 16, 2021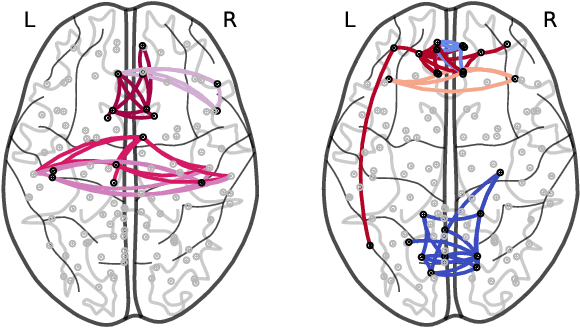
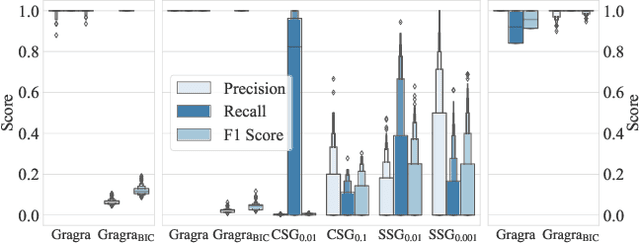
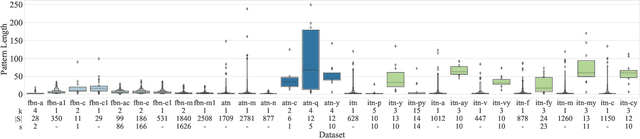
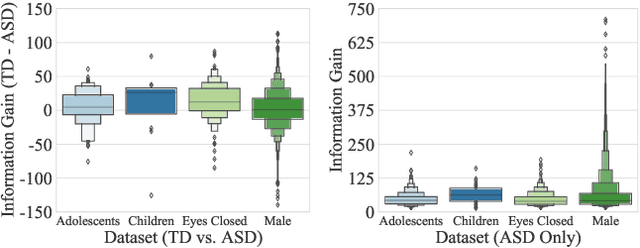
How does neural connectivity in autistic children differ from neural connectivity in healthy children or autistic youths? What patterns in global trade networks are shared across classes of goods, and how do these patterns change over time? Answering questions like these requires us to differentially describe groups of graphs: Given a set of graphs and a partition of these graphs into groups, discover what graphs in one group have in common, how they systematically differ from graphs in other groups, and how multiple groups of graphs are related. We refer to this task as graph group analysis, which seeks to describe similarities and differences between graph groups by means of statistically significant subgraphs. To perform graph group analysis, we introduce Gragra, which uses maximum entropy modeling to identify a non-redundant set of subgraphs with statistically significant associations to one or more graph groups. Through an extensive set of experiments on a wide range of synthetic and real-world graph groups, we confirm that Gragra works well in practice.
Law Smells: Defining and Detecting Problematic Patterns in Legal Drafting
Oct 15, 2021Building on the computer science concept of code smells, we initiate the study of law smells, i.e., patterns in legal texts that pose threats to the comprehensibility and maintainability of the law. With five intuitive law smells as running examples - namely, duplicated phrase, long element, large reference tree, ambiguous syntax, and natural language obsession -, we develop a comprehensive law smell taxonomy. This taxonomy classifies law smells by when they can be detected, which aspects of law they relate to, and how they can be discovered. We introduce text-based and graph-based methods to identify instances of law smells, confirming their utility in practice using the United States Code as a test case. Our work demonstrates how ideas from software engineering can be leveraged to assess and improve the quality of legal code, thus drawing attention to an understudied area in the intersection of law and computer science and highlighting the potential of computational legal drafting.
Simplify Your Law: Using Information Theory to Deduplicate Legal Documents
Oct 02, 2021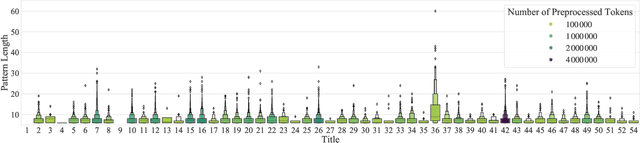
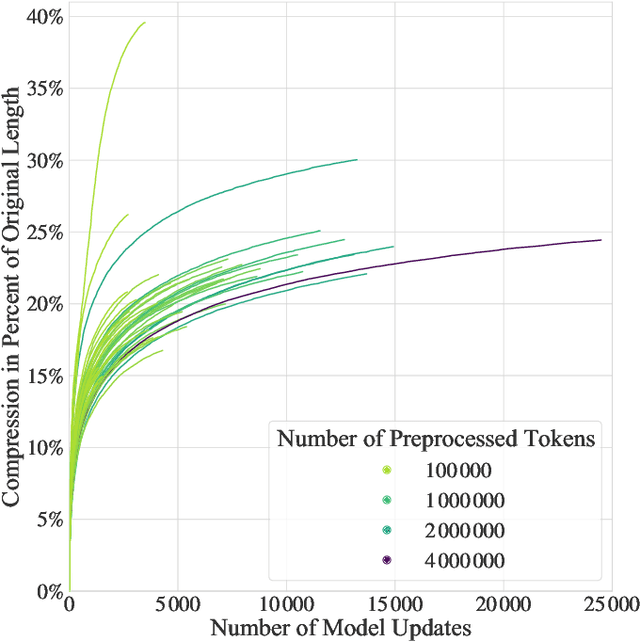
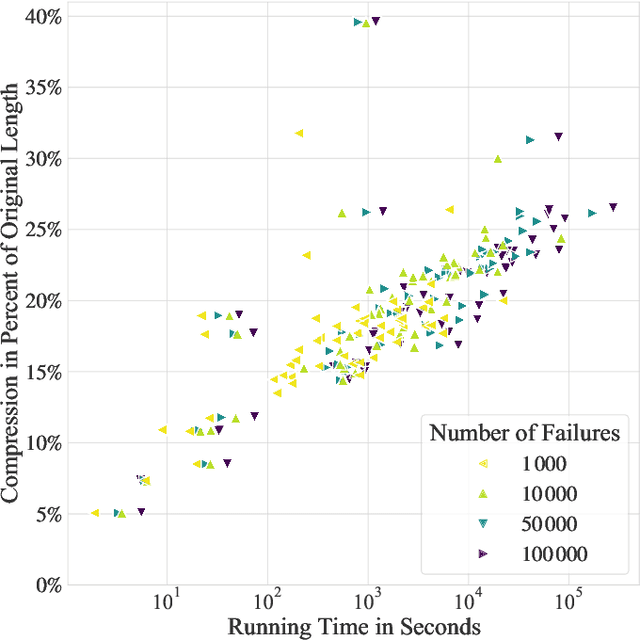
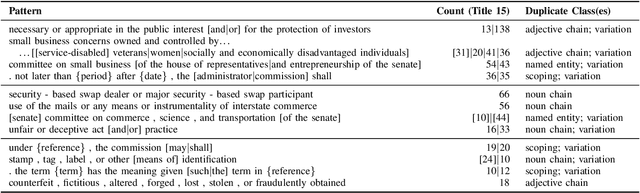
Textual redundancy is one of the main challenges to ensuring that legal texts remain comprehensible and maintainable. Drawing inspiration from the refactoring literature in software engineering, which has developed methods to expose and eliminate duplicated code, we introduce the duplicated phrase detection problem for legal texts and propose the Dupex algorithm to solve it. Leveraging the Minimum Description Length principle from information theory, Dupex identifies a set of duplicated phrases, called patterns, that together best compress a given input text. Through an extensive set of experiments on the Titles of the United States Code, we confirm that our algorithm works well in practice: Dupex will help you simplify your law.
Graph Similarity Description: How Are These Graphs Similar?
May 29, 2021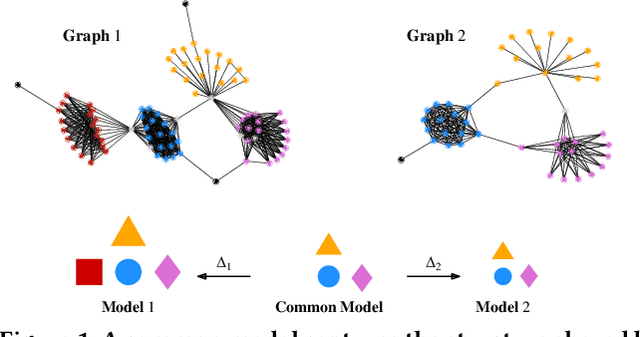
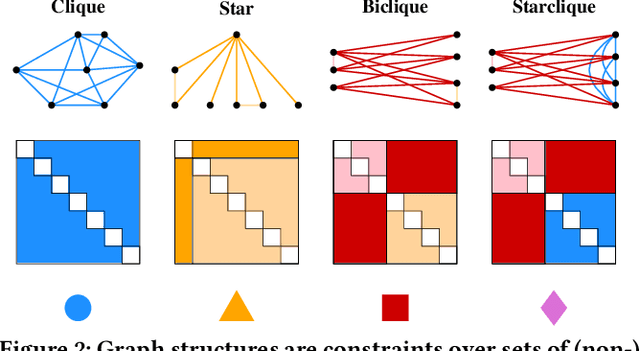

How do social networks differ across platforms? How do information networks change over time? Answering questions like these requires us to compare two or more graphs. This task is commonly treated as a measurement problem, but numerical answers give limited insight. Here, we argue that if the goal is to gain understanding, we should treat graph similarity assessment as a description problem instead. We formalize this problem as a model selection task using the Minimum Description Length principle, capturing the similarity of the input graphs in a common model and the differences between them in transformations to individual models. To discover good models, we propose Momo, which breaks the problem into two parts and introduces efficient algorithms for each. Through an extensive set of experiments on a wide range of synthetic and real-world graphs, we confirm that Momo works well in practice.