 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing in the Legal Domain
Feb 23, 2023



In this paper, we summarize the current state of the field of NLP & Law with a specific focus on recent technical and substantive developments. To support our analysis, we construct and analyze a nearly complete corpus of more than six hundred NLP & Law related papers published over the past decade. Our analysis highlights several major trends. Namely, we document an increasing number of papers written, tasks undertaken, and languages covered over the course of the past decade. We observe an increase in the sophistication of the methods which researchers deployed in this applied context. Slowly but surely, Legal NLP is beginning to match not only the methodological sophistication of general NLP but also the professional standards of data availability and code reproducibility observed within the broader scientific community. We believe all of these trends bode well for the future of the field, but many questions in both the academic and commercial sphere still remain open.
Law Smells: Defining and Detecting Problematic Patterns in Legal Drafting
Oct 15, 2021Building on the computer science concept of code smells, we initiate the study of law smells, i.e., patterns in legal texts that pose threats to the comprehensibility and maintainability of the law. With five intuitive law smells as running examples - namely, duplicated phrase, long element, large reference tree, ambiguous syntax, and natural language obsession -, we develop a comprehensive law smell taxonomy. This taxonomy classifies law smells by when they can be detected, which aspects of law they relate to, and how they can be discovered. We introduce text-based and graph-based methods to identify instances of law smells, confirming their utility in practice using the United States Code as a test case. Our work demonstrates how ideas from software engineering can be leveraged to assess and improve the quality of legal code, thus drawing attention to an understudied area in the intersection of law and computer science and highlighting the potential of computational legal drafting.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
Oct 13, 2021
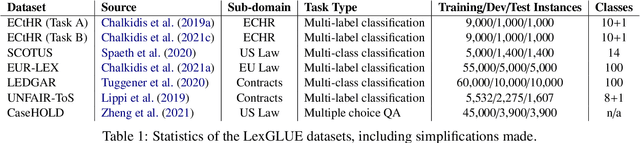

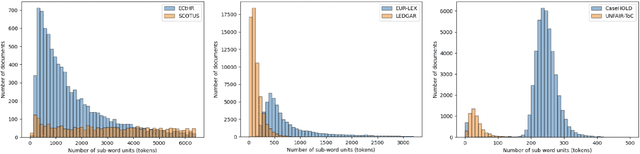
Law, interpretations of law, legal arguments, agreements, etc. are typically expressed in writing, leading to the production of vast corpora of legal text. Their analysis, which is at the center of legal practice, becomes increasingly elaborate as these collections grow in size. Natural language understanding (NLU) technologies can be a valuable tool to support legal practitioners in these endeavors. Their usefulness, however, largely depends on whether current state-of-the-art models can generalize across various tasks in the legal domain. To answer this currently open question, we introduce the Legal General Language Understanding Evaluation (LexGLUE) benchmark, a collection of datasets for evaluating model performance across a diverse set of legal NLU tasks in a standardized way. We also provide an evaluation and analysis of several generic and legal-oriented models demonstrating that the latter consistently offer performance improvements across multiple tasks.