 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripCraft: A Benchmark for Spatio-Temporally Fine Grained Travel Planning
Feb 27, 2025



Recent advancements in probing Large Language Models (LLMs) have explored their latent potential as personalized travel planning agents, yet existing benchmarks remain limited in real world applicability. Existing datasets, such as TravelPlanner and TravelPlanner+, suffer from semi synthetic data reliance, spatial inconsistencies, and a lack of key travel constraints, making them inadequate for practical itinerary generation. To address these gaps, we introduce TripCraft, a spatiotemporally coherent travel planning dataset that integrates real world constraints, including public transit schedules, event availability, diverse attraction categories, and user personas for enhanced personalization. To evaluate LLM generated plans beyond existing binary validation methods, we propose five continuous evaluation metrics, namely Temporal Meal Score, Temporal Attraction Score, Spatial Score, Ordering Score, and Persona Score which assess itinerary quality across multiple dimensions. Our parameter informed setting significantly enhances meal scheduling, improving the Temporal Meal Score from 61% to 80% in a 7 day scenario. TripCraft establishes a new benchmark for LLM driven personalized travel planning, offering a more realistic, constraint aware framework for itinerary generation. Dataset and Codebase will be made publicly available upon acceptance.
Pruning Literals for Highly Efficient Explainability at Word Level
Nov 07, 2024



Designing an explainable model becomes crucial now for Natural Language Processing(NLP) since most of the state-of-the-art machine learning models provide a limited explanation for the prediction. In the spectrum of an explainable model, Tsetlin Machine(TM) is promising because of its capability of providing word-level explanation using proposition logic. However, concern rises over the elaborated combination of literals (propositional logic) in the clause that makes the model difficult for humans to comprehend, despite having a transparent learning process. In this paper, we design a post-hoc pruning of clauses that eliminate the randomly placed literals in the clause thereby making the model more efficiently interpretable than the vanilla TM. Experiments on the publicly available YELP-HAT Dataset demonstrate that the proposed pruned TM's attention map aligns more with the human attention map than the vanilla TM's attention map. In addition, the pairwise similarity measure also surpasses the attention map-based neural network models. In terms of accuracy, the proposed pruning method does not degrade the accuracy significantly but rather enhances the performance up to 4% to 9% in some test data.
* 8 pages, 3 figures
CrowdCounter: A benchmark type-specific multi-target counterspeech dataset
Oct 02, 2024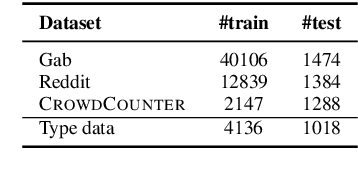


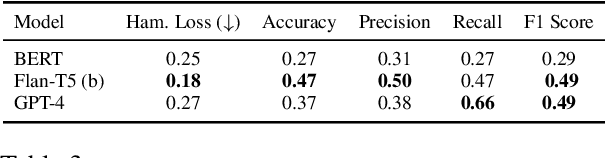
Counterspeech presents a viable alternative to banning or suspending users for hate speech while upholding freedom of expression. However, writing effective counterspeech is challenging for moderators/users. Hence, developing suggestion tools for writing counterspeech is the need of the hour. One critical challenge in developing such a tool is the lack of quality and diversity of the responses in the existing datasets. Hence, we introduce a new dataset - CrowdCounter containing 3,425 hate speech-counterspeech pairs spanning six different counterspeech types (empathy, humor, questioning, warning, shaming, contradiction), which is the first of its kind. The design of our annotation platform itself encourages annotators to write type-specific, non-redundant and high-quality counterspeech. We evaluate two frameworks for generating counterspeech responses - vanilla and type-controlled prompts - across four large language models. In terms of metrics, we evaluate the responses using relevance, diversity and quality. We observe that Flan-T5 is the best model in the vanilla framework across different models. Type-specific prompts enhance the relevance of the responses, although they might reduce the language quality. DialoGPT proves to be the best at following the instructions and generating the type-specific counterspeech accurately.
On Zero-Shot Counterspeech Generation by LLMs
Mar 22, 2024With the emergence of numerous Large Language Models (LLM), the usage of such models in various Natural Language Processing (NLP) applications is increasing extensively. Counterspeech generation is one such key task where efforts are made to develop generative models by fine-tuning LLMs with hatespeech - counterspeech pairs, but none of these attempts explores the intrinsic properties of large language models in zero-shot settings. In this work, we present a comprehensive analysis of the performances of four LLMs namely GPT-2, DialoGPT, ChatGPT and FlanT5 in zero-shot settings for counterspeech generation, which is the first of its kind. For GPT-2 and DialoGPT, we further investigate the deviation in performance with respect to the sizes (small, medium, large) of the models. On the other hand, we propose three different prompting strategies for generating different types of counterspeech and analyse the impact of such strategies on the performance of the models. Our analysis shows that there is an improvement in generation quality for two datasets (17%), however the toxicity increase (25%) with increase in model size. Considering type of model, GPT-2 and FlanT5 models are significantly better in terms of counterspeech quality but also have high toxicity as compared to DialoGPT. ChatGPT are much better at generating counter speech than other models across all metrics. In terms of prompting, we find that our proposed strategies help in improving counter speech generation across all the models.
Natural Language Processing in the Legal Domain
Feb 23, 2023



In this paper, we summarize the current state of the field of NLP & Law with a specific focus on recent technical and substantive developments. To support our analysis, we construct and analyze a nearly complete corpus of more than six hundred NLP & Law related papers published over the past decade. Our analysis highlights several major trends. Namely, we document an increasing number of papers written, tasks undertaken, and languages covered over the course of the past decade. We observe an increase in the sophistication of the methods which researchers deployed in this applied context. Slowly but surely, Legal NLP is beginning to match not only the methodological sophistication of general NLP but also the professional standards of data availability and code reproducibility observed within the broader scientific community. We believe all of these trends bode well for the future of the field, but many questions in both the academic and commercial sphere still remain open.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
Oct 13, 2021
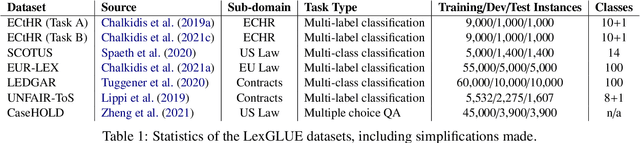

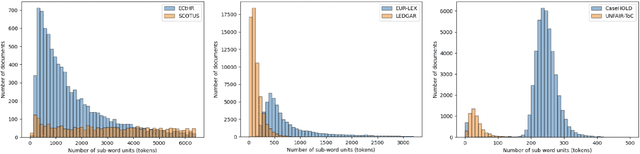
Law, interpretations of law, legal arguments, agreements, etc. are typically expressed in writing, leading to the production of vast corpora of legal text. Their analysis, which is at the center of legal practice, becomes increasingly elaborate as these collections grow in size. Natural language understanding (NLU) technologies can be a valuable tool to support legal practitioners in these endeavors. Their usefulness, however, largely depends on whether current state-of-the-art models can generalize across various tasks in the legal domain. To answer this currently open question, we introduce the Legal General Language Understanding Evaluation (LexGLUE) benchmark, a collection of datasets for evaluating model performance across a diverse set of legal NLU tasks in a standardized way. We also provide an evaluation and analysis of several generic and legal-oriented models demonstrating that the latter consistently offer performance improvements across multiple tasks.
Using Distributional Thesaurus Embedding for Co-hyponymy Detection
Feb 24, 2020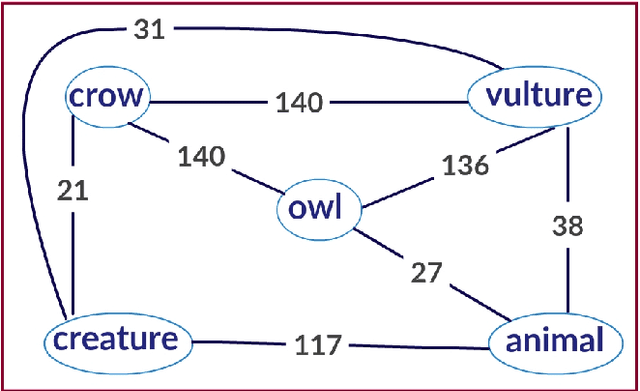

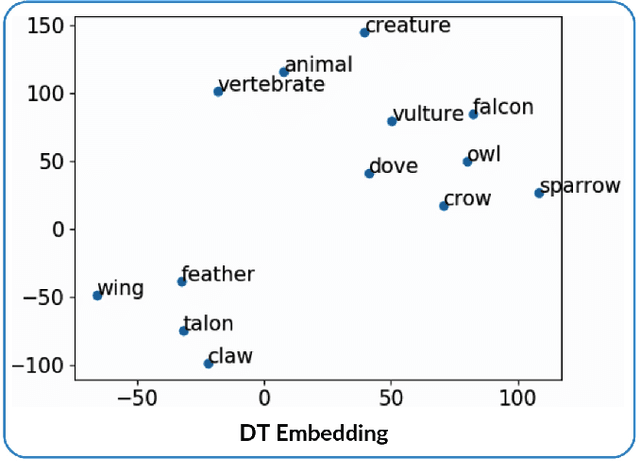
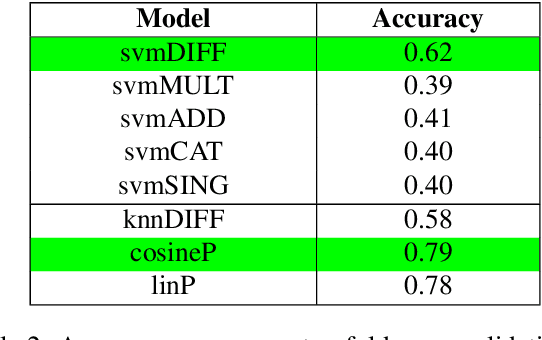
Discriminating lexical relations among distributionally similar words has always been a challenge for natural language processing (NLP) community. In this paper, we investigate whether the network embedding of distributional thesaurus can be effectively utilized to detect co-hyponymy relations. By extensive experiments over three benchmark datasets, we show that the vector representation obtained by applying node2vec on distributional thesaurus outperforms the state-of-the-art models for binary classification of co-hyponymy vs. hypernymy, as well as co-hyponymy vs. meronymy, by huge margins.
Incorporating Domain Knowledge into Medical NLI using Knowledge Graphs
Aug 31, 2019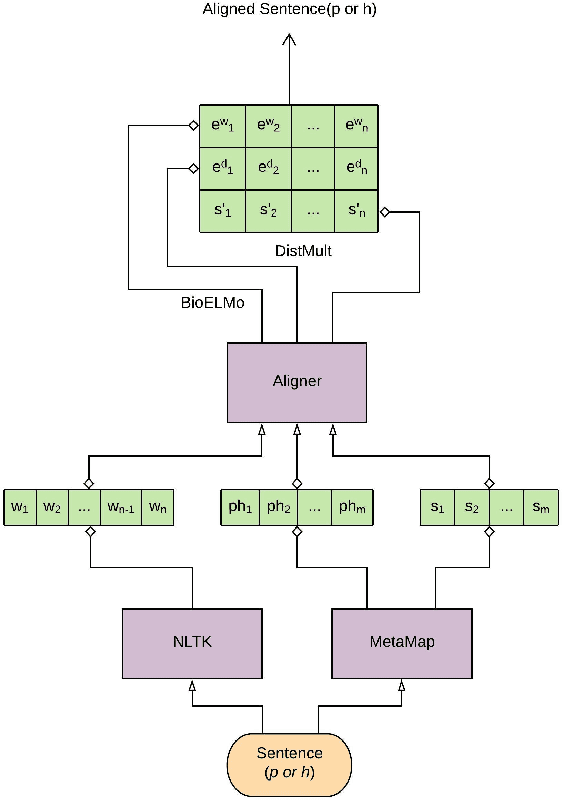
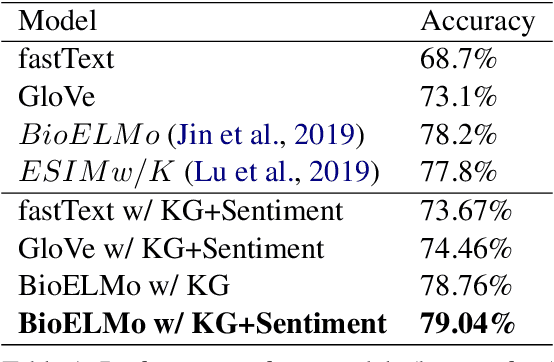
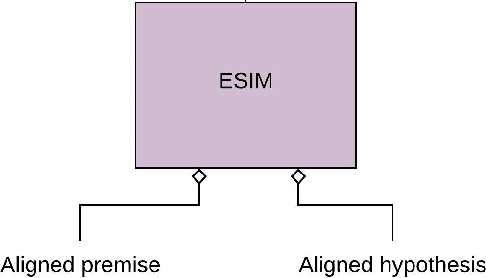
Recently, biomedical version of embeddings obtained from language models such as BioELMo have shown state-of-the-art results for the textual inference task in the medical domain. In this paper, we explore how to incorporate structured domain knowledge, available in the form of a knowledge graph (UMLS), for the Medical NLI task. Specifically, we experiment with fusing embeddings obtained from knowledge graph with the state-of-the-art approaches for NLI task (ESIM model). We also experiment with fusing the domain-specific sentiment information for the task. Experiments conducted on MedNLI dataset clearly show that this strategy improves the baseline BioELMo architecture for the Medical NLI task.
On the Compositionality Prediction of Noun Phrases using Poincaré Embeddings
Jun 07, 2019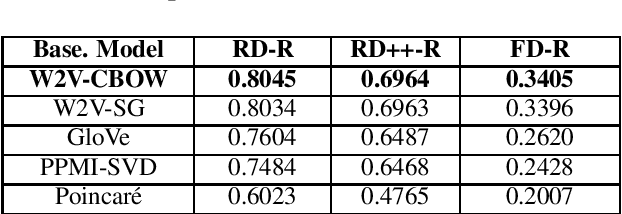
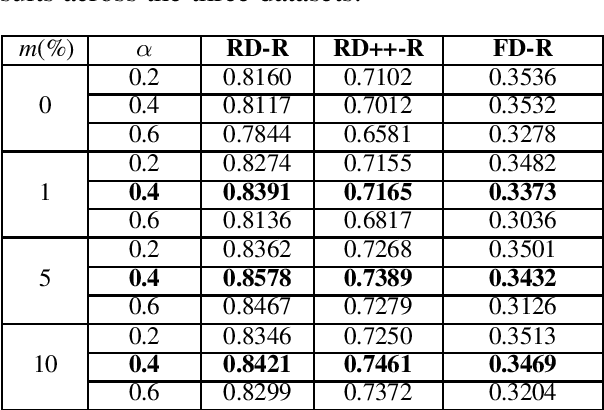
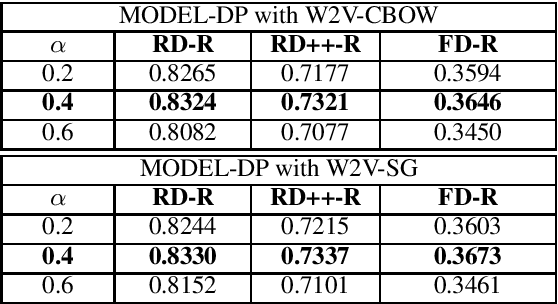
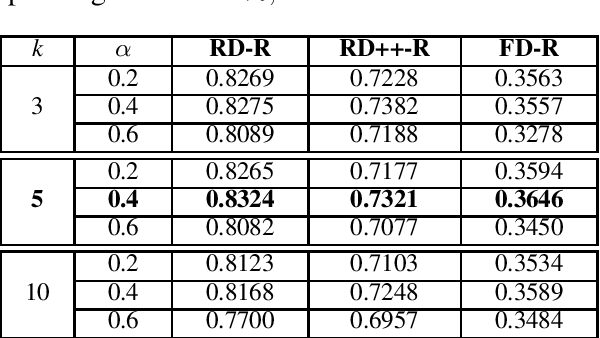
The compositionality degree of multiword expressions indicates to what extent the meaning of a phrase can be derived from the meaning of its constituents and their grammatical relations. Prediction of (non)-compositionality is a task that has been frequently addressed with distributional semantic models. We introduce a novel technique to blend hierarchical information with distributional information for predicting compositionality. In particular, we use hypernymy information of the multiword and its constituents encoded in the form of the recently introduced Poincar\'e embeddings in addition to the distributional information to detect compositionality for noun phrases. Using a weighted average of the distributional similarity and a Poincar\'e similarity function, we obtain consistent and substantial, statistically significant improvement across three gold standard datasets over state-of-the-art models based on distributional information only. Unlike traditional approaches that solely use an unsupervised setting, we have also framed the problem as a supervised task, obtaining comparable improvements. Further, we publicly release our Poincar\'e embeddings, which are trained on the output of handcrafted lexical-syntactic patterns on a large corpus.
Detecting Reliable Novel Word Senses: A Network-Centric Approach
Dec 14, 2018

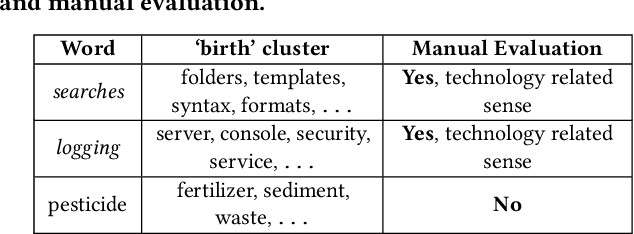

In this era of Big Data, due to expeditious exchange of information on the web, words are being used to denote newer meanings, causing linguistic shift. With the recent availability of large amounts of digitized texts, an automated analysis of the evolution of language has become possible. Our study mainly focuses on improving the detection of new word senses. This paper presents a unique proposal based on network features to improve the precision of new word sense detection. For a candidate word where a new sense (birth) has been detected by comparing the sense clusters induced at two different time points, we further compare the network properties of the subgraphs induced from novel sense cluster across these two time points. Using the mean fractional change in edge density, structural similarity and average path length as features in an SVM classifier, manual evaluation gives precision values of 0.86 and 0.74 for the task of new sense detection, when tested on 2 distinct time-point pairs, in comparison to the precision values in the range of 0.23-0.32, when the proposed scheme is not used. The outlined method can therefore be used as a new post-hoc step to improve the precision of novel word sense detection in a robust and reliable way where the underlying framework uses a graph structure. Another important observation is that even though our proposal is a post-hoc step, it can be used in isolation and that itself results in a very decent performance achieving a precision of 0.54-0.62. Finally, we show that our method is able to detect the well-known historical shifts in 80% cases.