 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-phase Word Embedding Using Conjunctive Propositional Clauses
Jan 31, 2025



The Tsetlin Machine (TM) architecture has recently demonstrated effectiveness in Machine Learning (ML), particularly within Natural Language Processing (NLP). It has been utilized to construct word embedding using conjunctive propositional clauses, thereby significantly enhancing our understanding and interpretation of machine-derived decisions. The previous approach performed the word embedding over a sequence of input words to consolidate the information into a cohesive and unified representation. However, that approach encounters scalability challenges as the input size increases. In this study, we introduce a novel approach incorporating two-phase training to discover contextual embeddings of input sequences. Specifically, this method encapsulates the knowledge for each input word within the dataset's vocabulary, subsequently constructing embeddings for a sequence of input words utilizing the extracted knowledge. This technique not only facilitates the design of a scalable model but also preserves interpretability. Our experimental findings revealed that the proposed method yields competitive performance compared to the previous approaches, demonstrating promising results in contrast to human-generated benchmarks. Furthermore, we applied the proposed approach to sentiment analysis on the IMDB dataset, where the TM embedding and the TM classifier, along with other interpretable classifiers, offered a transparent end-to-end solution with competitive performance.
Pruning Literals for Highly Efficient Explainability at Word Level
Nov 07, 2024



Designing an explainable model becomes crucial now for Natural Language Processing(NLP) since most of the state-of-the-art machine learning models provide a limited explanation for the prediction. In the spectrum of an explainable model, Tsetlin Machine(TM) is promising because of its capability of providing word-level explanation using proposition logic. However, concern rises over the elaborated combination of literals (propositional logic) in the clause that makes the model difficult for humans to comprehend, despite having a transparent learning process. In this paper, we design a post-hoc pruning of clauses that eliminate the randomly placed literals in the clause thereby making the model more efficiently interpretable than the vanilla TM. Experiments on the publicly available YELP-HAT Dataset demonstrate that the proposed pruned TM's attention map aligns more with the human attention map than the vanilla TM's attention map. In addition, the pairwise similarity measure also surpasses the attention map-based neural network models. In terms of accuracy, the proposed pruning method does not degrade the accuracy significantly but rather enhances the performance up to 4% to 9% in some test data.
* 8 pages, 3 figures
Exploring Effects of Hyperdimensional Vectors for Tsetlin Machines
Jun 04, 2024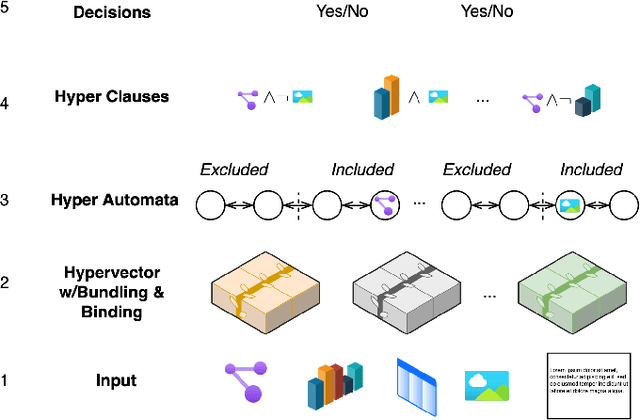
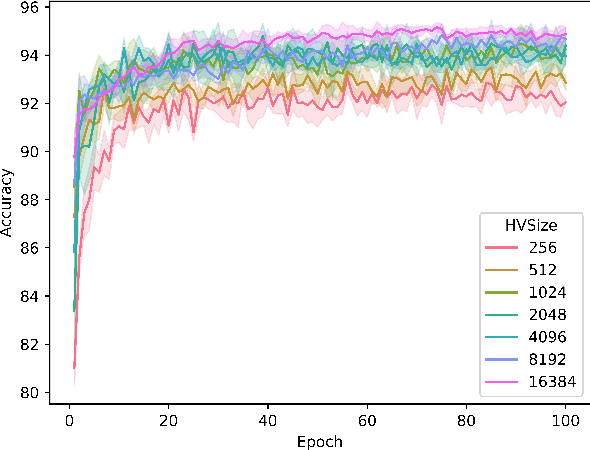
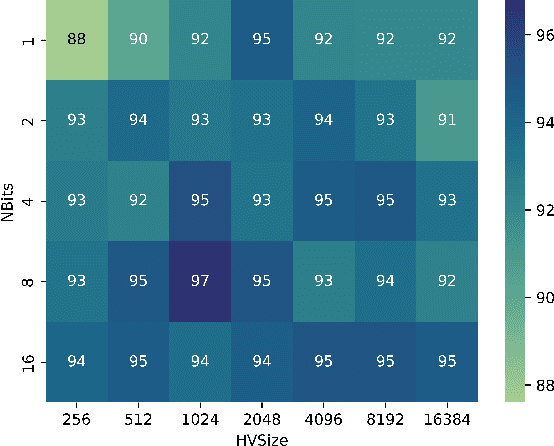
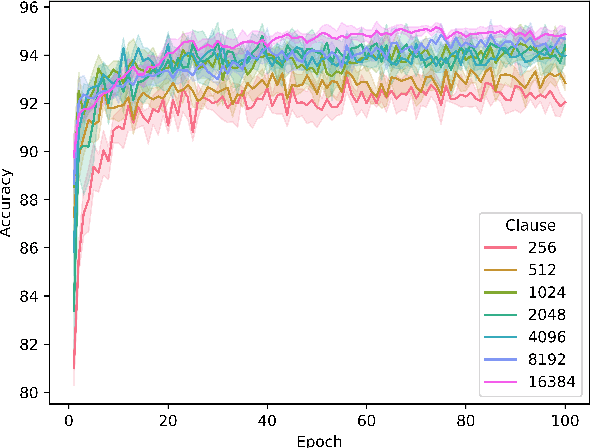
Tsetlin machines (TMs) have been successful in several application domains, operating with high efficiency on Boolean representations of the input data. However, Booleanizing complex data structures such as sequences, graphs, images, signal spectra, chemical compounds, and natural language is not trivial. In this paper, we propose a hypervector (HV) based method for expressing arbitrarily large sets of concepts associated with any input data. Using a hyperdimensional space to build vectors drastically expands the capacity and flexibility of the TM. We demonstrate how images, chemical compounds, and natural language text are encoded according to the proposed method, and how the resulting HV-powered TM can achieve significantly higher accuracy and faster learning on well-known benchmarks. Our results open up a new research direction for TMs, namely how to expand and exploit the benefits of operating in hyperspace, including new booleanization strategies, optimization of TM inference and learning, as well as new TM applications.
Contracting Tsetlin Machine with Absorbing Automata
Oct 17, 2023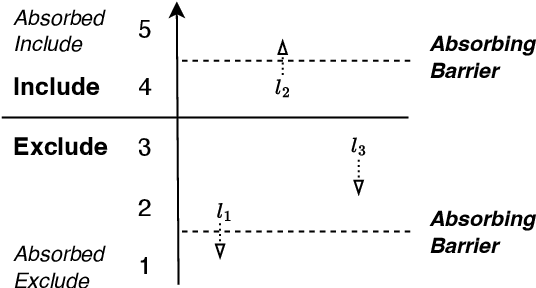
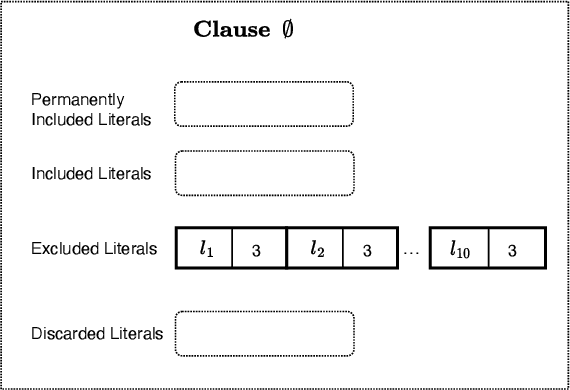
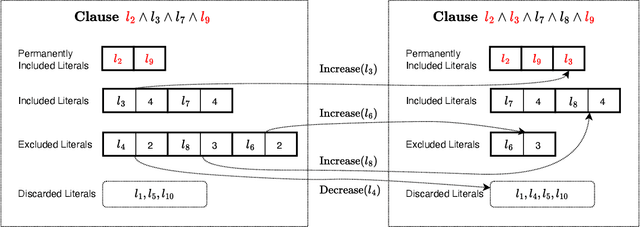
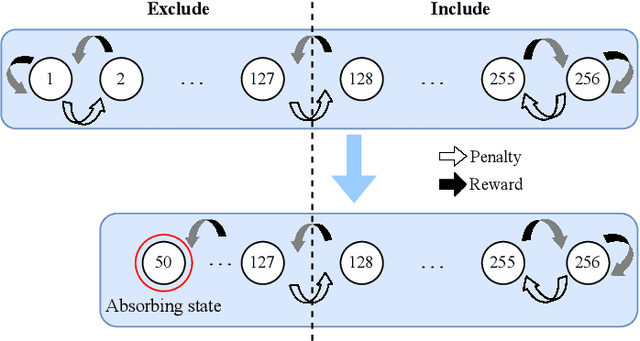
In this paper, we introduce a sparse Tsetlin Machine (TM) with absorbing Tsetlin Automata (TA) states. In brief, the TA of each clause literal has both an absorbing Exclude- and an absorbing Include state, making the learning scheme absorbing instead of ergodic. When a TA reaches an absorbing state, it will never leave that state again. If the absorbing state is an Exclude state, both the automaton and the literal can be removed from further consideration. The literal will as a result never participates in that clause. If the absorbing state is an Include state, on the other hand, the literal is stored as a permanent part of the clause while the TA is discarded. A novel sparse data structure supports these updates by means of three action lists: Absorbed Include, Include, and Exclude. By updating these lists, the TM gets smaller and smaller as the literals and their TA withdraw. In this manner, the computation accelerates during learning, leading to faster learning and less energy consumption.
Verifying Properties of Tsetlin Machines
Mar 25, 2023



Tsetlin Machines (TsMs) are a promising and interpretable machine learning method which can be applied for various classification tasks. We present an exact encoding of TsMs into propositional logic and formally verify properties of TsMs using a SAT solver. In particular, we introduce in this work a notion of similarity of machine learning models and apply our notion to check for similarity of TsMs. We also consider notions of robustness and equivalence from the literature and adapt them for TsMs. Then, we show the correctness of our encoding and provide results for the properties: adversarial robustness, equivalence, and similarity of TsMs. In our experiments, we employ the MNIST and IMDB datasets for (respectively) image and sentiment classification. We discuss the results for verifying robustness obtained with TsMs with those in the literature obtained with Binarized Neural Networks on MNIST.
Building Concise Logical Patterns by Constraining Tsetlin Machine Clause Size
Jan 19, 2023Tsetlin machine (TM) is a logic-based machine learning approach with the crucial advantages of being transparent and hardware-friendly. While TMs match or surpass deep learning accuracy for an increasing number of applications, large clause pools tend to produce clauses with many literals (long clauses). As such, they become less interpretable. Further, longer clauses increase the switching activity of the clause logic in hardware, consuming more power. This paper introduces a novel variant of TM learning - Clause Size Constrained TMs (CSC-TMs) - where one can set a soft constraint on the clause size. As soon as a clause includes more literals than the constraint allows, it starts expelling literals. Accordingly, oversized clauses only appear transiently. To evaluate CSC-TM, we conduct classification, clustering, and regression experiments on tabular data, natural language text, images, and board games. Our results show that CSC-TM maintains accuracy with up to 80 times fewer literals. Indeed, the accuracy increases with shorter clauses for TREC, IMDb, and BBC Sports. After the accuracy peaks, it drops gracefully as the clause size approaches a single literal. We finally analyze CSC-TM power consumption and derive new convergence properties.
Tsetlin Machine Embedding: Representing Words Using Logical Expressions
Jan 02, 2023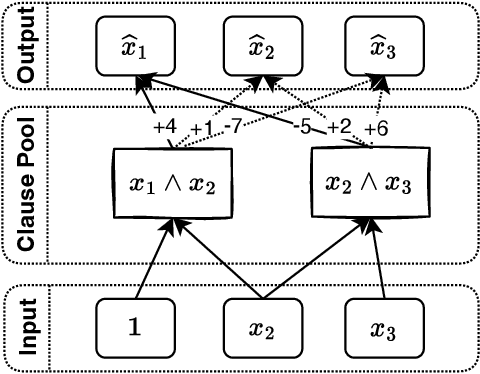

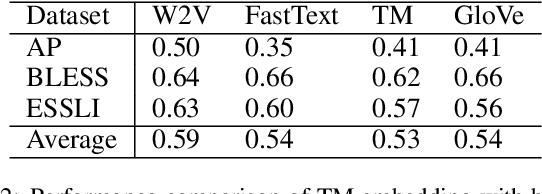
Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.
Explainable Tsetlin Machine framework for fake news detection with credibility score assessment
May 19, 2021The proliferation of fake news, i.e., news intentionally spread for misinformation, poses a threat to individuals and society. Despite various fact-checking websites such as PolitiFact, robust detection techniques are required to deal with the increase in fake news. Several deep learning models show promising results for fake news classification, however, their black-box nature makes it difficult to explain their classification decisions and quality-assure the models. We here address this problem by proposing a novel interpretable fake news detection framework based on the recently introduced Tsetlin Machine (TM). In brief, we utilize the conjunctive clauses of the TM to capture lexical and semantic properties of both true and fake news text. Further, we use the clause ensembles to calculate the credibility of fake news. For evaluation, we conduct experiments on two publicly available datasets, PolitiFact and GossipCop, and demonstrate that the TM framework significantly outperforms previously published baselines by at least $5\%$ in terms of accuracy, with the added benefit of an interpretable logic-based representation. Further, our approach provides higher F1-score than BERT and XLNet, however, we obtain slightly lower accuracy. We finally present a case study on our model's explainability, demonstrating how it decomposes into meaningful words and their negations.
Word-level Human Interpretable Scoring Mechanism for Novel Text Detection Using Tsetlin Machines
May 10, 2021Recent research in novelty detection focuses mainly on document-level classification, employing deep neural networks (DNN). However, the black-box nature of DNNs makes it difficult to extract an exact explanation of why a document is considered novel. In addition, dealing with novelty at the word-level is crucial to provide a more fine-grained analysis than what is available at the document level. In this work, we propose a Tsetlin machine (TM)-based architecture for scoring individual words according to their contribution to novelty. Our approach encodes a description of the novel documents using the linguistic patterns captured by TM clauses. We then adopt this description to measure how much a word contributes to making documents novel. Our experimental results demonstrate how our approach breaks down novelty into interpretable phrases, successfully measuring novelty.
Measuring the Novelty of Natural Language Text Using the Conjunctive Clauses of a Tsetlin Machine Text Classifier
Nov 17, 2020Most supervised text classification approaches assume a closed world, counting on all classes being present in the data at training time. This assumption can lead to unpredictable behaviour during operation, whenever novel, previously unseen, classes appear. Although deep learning-based methods have recently been used for novelty detection, they are challenging to interpret due to their black-box nature. This paper addresses \emph{interpretable} open-world text classification, where the trained classifier must deal with novel classes during operation. To this end, we extend the recently introduced Tsetlin machine (TM) with a novelty scoring mechanism. The mechanism uses the conjunctive clauses of the TM to measure to what degree a text matches the classes covered by the training data. We demonstrate that the clauses provide a succinct interpretable description of known topics, and that our scoring mechanism makes it possible to discern novel topics from the known ones. Empirically, our TM-based approach outperforms seven other novelty detection schemes on three out of five datasets, and performs second and third best on the remaining, with the added benefit of an interpretable propositional logic-based representation.