 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Software Pipelining and Warp Specialization for Tensor Core GPUs
Dec 19, 2025


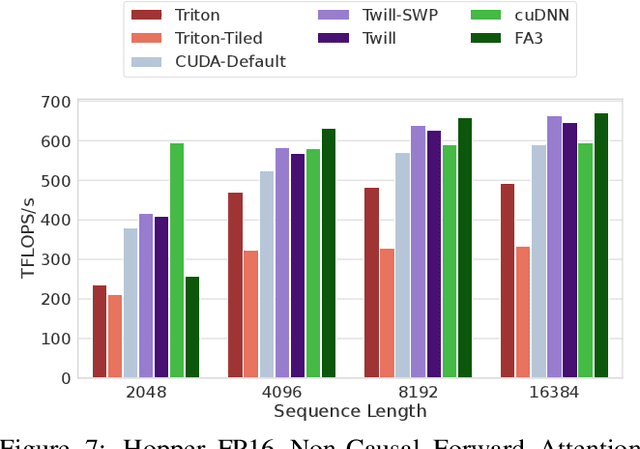
GPU architectures have continued to grow in complexity, with recent incarnations introducing increasingly powerful fixed-function units for matrix multiplication and data movement to accompany highly parallel general-purpose cores. To fully leverage these machines, software must use sophisticated schedules that maximally utilize all hardware resources. Since realizing such schedules is complex, both programmers and compilers routinely employ program transformations, such as software pipelining (SWP) and warp specialization (WS), to do so in practice. However, determining how best to use SWP and WS in combination is a challenging problem that is currently handled through a mix of brittle compilation heuristics and fallible human intuition, with little insight into the space of solutions. To remedy this situation, we introduce a novel formulation of SWP and WS as a joint optimization problem that can be solved holistically by off-the-shelf constraint solvers. We reify our approach in Twill, the first system that automatically derives optimal SWP and WS schedules for a large class of iterative programs. Twill is heuristic-free, easily extensible to new GPU architectures, and guaranteed to produce optimal schedules. We show that Twill can rediscover, and thereby prove optimal, the SWP and WS schedules manually developed by experts for Flash Attention on both the NVIDIA Hopper and Blackwell GPU architectures.
Improving Parallel Program Performance Through DSL-Driven Code Generation with LLM Optimizers
Oct 21, 2024Mapping computations to processors and assigning data to memory are critical for maximizing performance in parallel programming. These mapping decisions are managed through the development of specialized low-level system code, called mappers, crafted by performance engineers. Each mapper is tailored to a specific application and optimized for the underlying machine architecture, a process that requires days of refinement and tuning from an expert. Despite advances in system research, automating mapper generation remains a challenge due to the complexity of making millions of decisions to find the optimal solution and generate the solution as code. We introduce an approach that leverages recent advances in LLM-based optimizers for mapper design. In under ten minutes, our method automatically discovers mappers that surpass human expert designs in scientific applications by up to 1.34X speedup. For parallel matrix multiplication algorithms, our mapper achieves up to 1.31X of the expert-designed solution. To achieve this, we simplify the complexity of low-level code generation by introducing a domain-specific language (DSL) that abstracts the low-level system programming details and defines a structured search space for LLMs to explore. To maximize the application performance, we use an LLM optimizer to improve an agentic system that generates the mapper code. As a result, this approach significantly reduces the workload for performance engineers while achieving substantial performance gains across diverse applications. Finally, our results demonstrate the effectiveness of LLM-based optimization in system design and suggest its potential for addressing other complex system challenges.
Tsetlin Machine Embedding: Representing Words Using Logical Expressions
Jan 02, 2023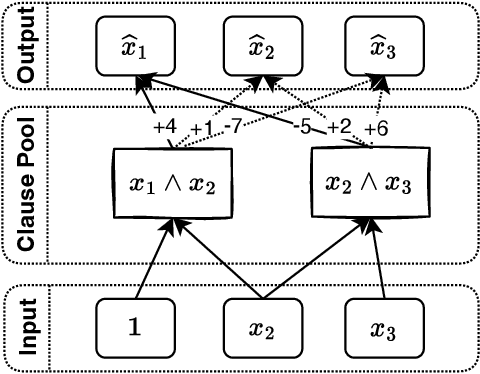

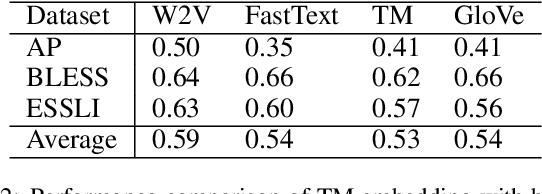
Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.
Human Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause
May 30, 2021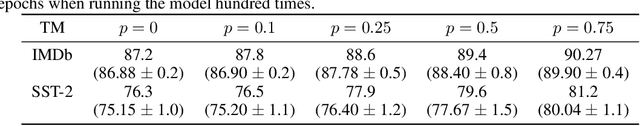


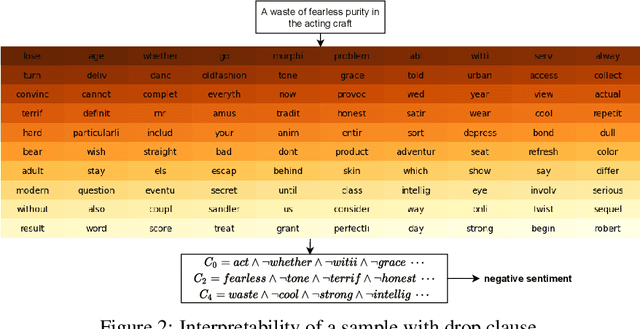
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. Along with producing more distinct and well-structured patterns that improve the performance, we also show that dropping clauses increases learning robustness. To explore the effects clause dropping has on accuracy, training time, and interpretability, we conduct extensive experiments on various benchmark datasets in natural language processing (NLP) (IMDb and SST2) as well as computer vision (MNIST and CIFAR10). In brief, we observe from +2% to +4% increase in accuracy and 2x to 4x faster learning. We further employ the Convolutional TM to document interpretable results on the CIFAR10 dataset. To the best of our knowledge, this is the first time an interpretable machine learning algorithm has been used to produce pixel-level human-interpretable results on CIFAR10. Also, unlike previous interpretable methods that focus on attention visualisation or gradient interpretability, we show that the TM is a more general interpretable method. That is, by producing rule-based propositional logic expressions that are \emph{human}-interpretable, the TM can explain how it classifies a particular instance at the pixel level for computer vision and at the word level for NLP.