 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsetlin Machine Embedding: Representing Words Using Logical Expressions
Paper and Code
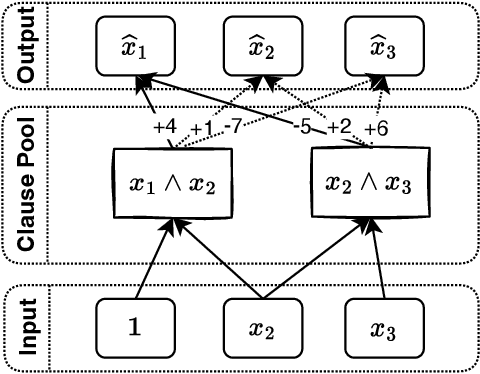

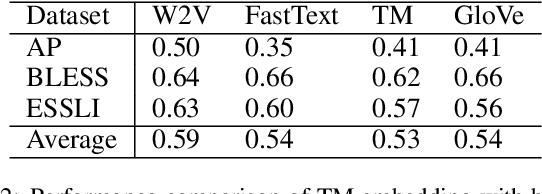
Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.