 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning
Oct 03, 2023
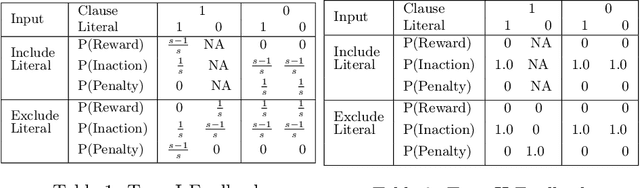
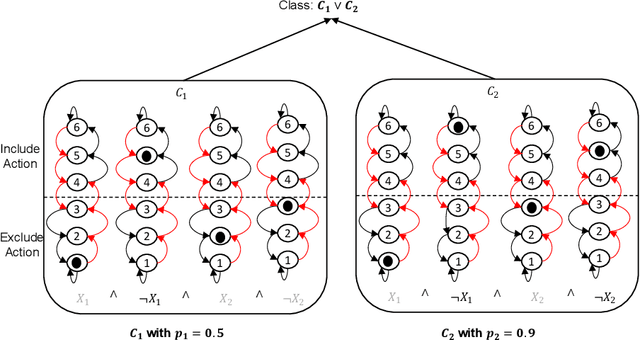
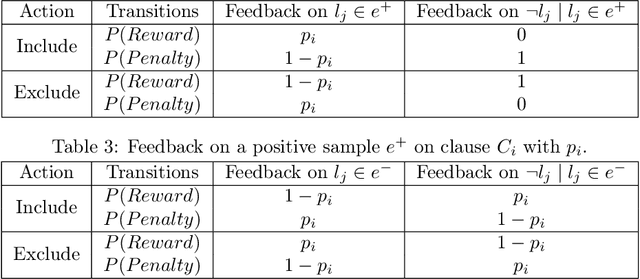
Tsetlin Machines (TMs) have garnered increasing interest for their ability to learn concepts via propositional formulas and their proven efficiency across various application domains. Despite this, the convergence proof for the TMs, particularly for the AND operator (\emph{conjunction} of literals), in the generalized case (inputs greater than two bits) remains an open problem. This paper aims to fill this gap by presenting a comprehensive convergence analysis of Tsetlin automaton-based Machine Learning algorithms. We introduce a novel framework, referred to as Probabilistic Concept Learning (PCL), which simplifies the TM structure while incorporating dedicated feedback mechanisms and dedicated inclusion/exclusion probabilities for literals. Given $n$ features, PCL aims to learn a set of conjunction clauses $C_i$ each associated with a distinct inclusion probability $p_i$. Most importantly, we establish a theoretical proof confirming that, for any clause $C_k$, PCL converges to a conjunction of literals when $0.5<p_k<1$. This result serves as a stepping stone for future research on the convergence properties of Tsetlin automaton-based learning algorithms. Our findings not only contribute to the theoretical understanding of Tsetlin Machines but also have implications for their practical application, potentially leading to more robust and interpretable machine learning models.
CorrEmbed: Evaluating Pre-trained Model Image Similarity Efficacy with a Novel Metric
Aug 30, 2023Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.
Verifying Properties of Tsetlin Machines
Mar 25, 2023



Tsetlin Machines (TsMs) are a promising and interpretable machine learning method which can be applied for various classification tasks. We present an exact encoding of TsMs into propositional logic and formally verify properties of TsMs using a SAT solver. In particular, we introduce in this work a notion of similarity of machine learning models and apply our notion to check for similarity of TsMs. We also consider notions of robustness and equivalence from the literature and adapt them for TsMs. Then, we show the correctness of our encoding and provide results for the properties: adversarial robustness, equivalence, and similarity of TsMs. In our experiments, we employ the MNIST and IMDB datasets for (respectively) image and sentiment classification. We discuss the results for verifying robustness obtained with TsMs with those in the literature obtained with Binarized Neural Networks on MNIST.
Building Concise Logical Patterns by Constraining Tsetlin Machine Clause Size
Jan 19, 2023Tsetlin machine (TM) is a logic-based machine learning approach with the crucial advantages of being transparent and hardware-friendly. While TMs match or surpass deep learning accuracy for an increasing number of applications, large clause pools tend to produce clauses with many literals (long clauses). As such, they become less interpretable. Further, longer clauses increase the switching activity of the clause logic in hardware, consuming more power. This paper introduces a novel variant of TM learning - Clause Size Constrained TMs (CSC-TMs) - where one can set a soft constraint on the clause size. As soon as a clause includes more literals than the constraint allows, it starts expelling literals. Accordingly, oversized clauses only appear transiently. To evaluate CSC-TM, we conduct classification, clustering, and regression experiments on tabular data, natural language text, images, and board games. Our results show that CSC-TM maintains accuracy with up to 80 times fewer literals. Indeed, the accuracy increases with shorter clauses for TREC, IMDb, and BBC Sports. After the accuracy peaks, it drops gracefully as the clause size approaches a single literal. We finally analyze CSC-TM power consumption and derive new convergence properties.
Tsetlin Machine Embedding: Representing Words Using Logical Expressions
Jan 02, 2023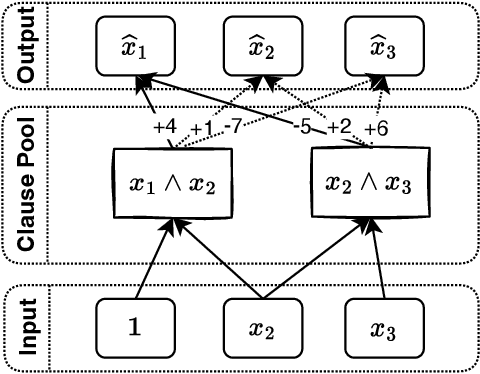

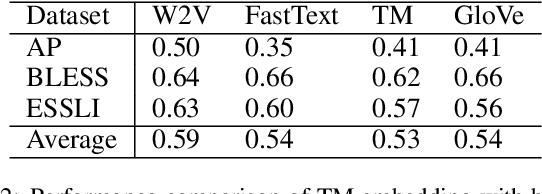
Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.
On the Equivalence of the Weighted Tsetlin Machine and the Perceptron
Dec 27, 2022Tsetlin Machine (TM) has been gaining popularity as an inherently interpretable machine leaning method that is able to achieve promising performance with low computational complexity on a variety of applications. The interpretability and the low computational complexity of the TM are inherited from the Boolean expressions for representing various sub-patterns. Although possessing favorable properties, TM has not been the go-to method for AI applications, mainly due to its conceptual and theoretical differences compared with perceptrons and neural networks, which are more widely known and well understood. In this paper, we provide detailed insights for the operational concept of the TM, and try to bridge the gap in the theoretical understanding between the perceptron and the TM. More specifically, we study the operational concept of the TM following the analytical structure of perceptrons, showing the resemblance between the perceptrons and the TM. Through the analysis, we indicated that the TM's weight update can be considered as a special case of the gradient weight update. We also perform an empirical analysis of TM by showing the flexibility in determining the clause length, visualization of decision boundaries and obtaining interpretable boolean expressions from TM. In addition, we also discuss the advantages of TM in terms of its structure and its ability to solve more complex problems.
A Comparison Between Tsetlin Machines and Deep Neural Networks in the Context of Recommendation Systems
Dec 20, 2022Recommendation Systems (RSs) are ubiquitous in modern society and are one of the largest points of interaction between humans and AI. Modern RSs are often implemented using deep learning models, which are infamously difficult to interpret. This problem is particularly exasperated in the context of recommendation scenarios, as it erodes the user's trust in the RS. In contrast, the newly introduced Tsetlin Machines (TM) possess some valuable properties due to their inherent interpretability. TMs are still fairly young as a technology. As no RS has been developed for TMs before, it has become necessary to perform some preliminary research regarding the practicality of such a system. In this paper, we develop the first RS based on TMs to evaluate its practicality in this application domain. This paper compares the viability of TMs with other machine learning models prevalent in the field of RS. We train and investigate the performance of the TM compared with a vanilla feed-forward deep learning model. These comparisons are based on model performance, interpretability/explainability, and scalability. Further, we provide some benchmark performance comparisons to similar machine learning solutions relevant to RSs.
Tsetlin Machine for Solving Contextual Bandit Problems
Feb 04, 2022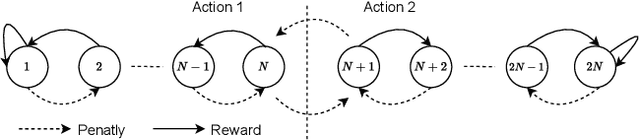
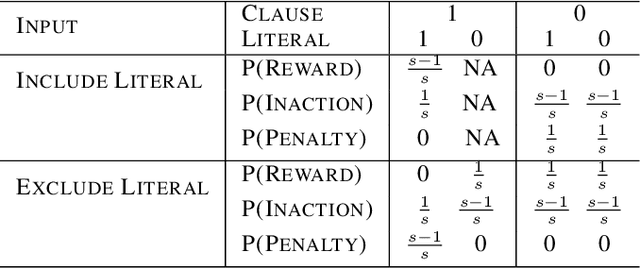
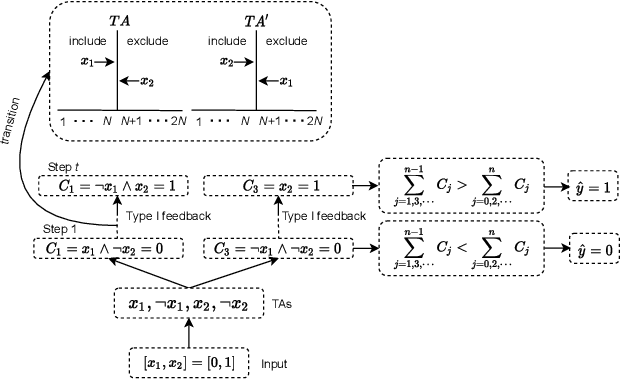
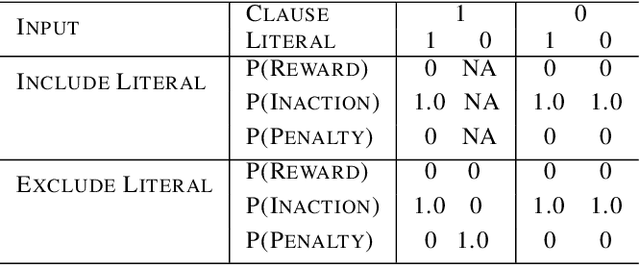
This paper introduces an interpretable contextual bandit algorithm using Tsetlin Machines, which solves complex pattern recognition tasks using propositional logic. The proposed bandit learning algorithm relies on straightforward bit manipulation, thus simplifying computation and interpretation. We then present a mechanism for performing Thompson sampling with Tsetlin Machine, given its non-parametric nature. Our empirical analysis shows that Tsetlin Machine as a base contextual bandit learner outperforms other popular base learners on eight out of nine datasets. We further analyze the interpretability of our learner, investigating how arms are selected based on propositional expressions that model the context.
Human Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause
May 30, 2021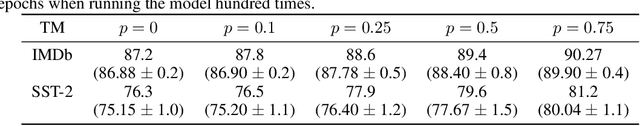


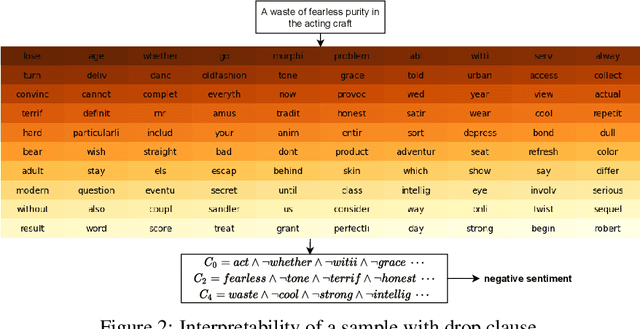
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. Along with producing more distinct and well-structured patterns that improve the performance, we also show that dropping clauses increases learning robustness. To explore the effects clause dropping has on accuracy, training time, and interpretability, we conduct extensive experiments on various benchmark datasets in natural language processing (NLP) (IMDb and SST2) as well as computer vision (MNIST and CIFAR10). In brief, we observe from +2% to +4% increase in accuracy and 2x to 4x faster learning. We further employ the Convolutional TM to document interpretable results on the CIFAR10 dataset. To the best of our knowledge, this is the first time an interpretable machine learning algorithm has been used to produce pixel-level human-interpretable results on CIFAR10. Also, unlike previous interpretable methods that focus on attention visualisation or gradient interpretability, we show that the TM is a more general interpretable method. That is, by producing rule-based propositional logic expressions that are \emph{human}-interpretable, the TM can explain how it classifies a particular instance at the pixel level for computer vision and at the word level for NLP.
Environment Sound Classification using Multiple Feature Channels and Deep Convolutional Neural Networks
Sep 25, 2019
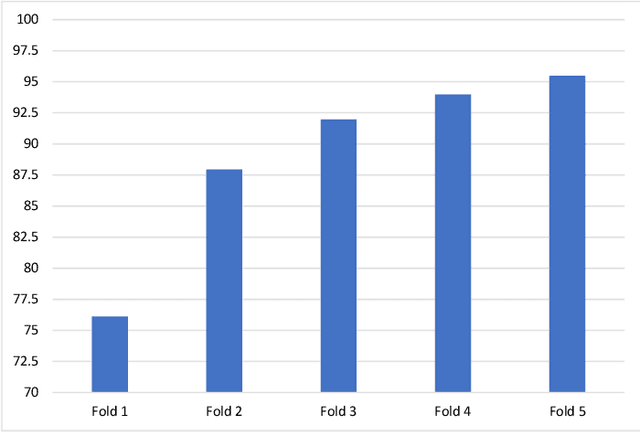
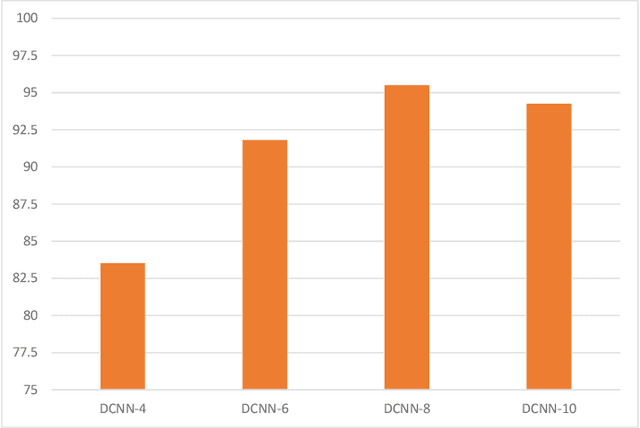
In this paper, we propose a model for the Environment Sound Classification Task (ESC) that consists of multiple feature channels given as input to a Deep Convolutional Neural Network (CNN). The novelty of the paper lies in using multiple feature channels consisting of Mel-Frequency Cepstral Coefficients (MFCC), Gammatone Frequency Cepstral Coefficients (GFCC), the Constant Q-transform (CQT) and Chromagram. Such multiple features have never been used before for signal or audio processing. Also, we employ a deeper CNN (DCNN) compared to previous models, consisting of 2D separable convolutions working on time and feature domain separately. The model also consists of max pooling layers that downsample time and feature domain separately. We use some data augmentation techniques to further boost performance. Our model is able to achieve state-of-the-art performance on all three benchmark environment sound classification datasets, i.e. the UrbanSound8K (97.35%), ESC-10 (95.75%) and ESC-50 (90.48%). To the best of our knowledge, this is the first time that a single environment sound classification model is able to achieve state-of-the-art results on all three datasets. For ESC-10 and ESC-50 datasets, the accuracy achieved by the proposed model is beyond human accuracy of 95.7% and 81.3% respectively.