 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn All-digital 65-nm Tsetlin Machine Image Classification Accelerator with 8.6 nJ per MNIST Frame at 60.3k Frames per Second
Jan 31, 2025



We present an all-digital programmable machine learning accelerator chip for image classification, underpinning on the Tsetlin machine (TM) principles. The TM is a machine learning algorithm founded on propositional logic, utilizing sub-pattern recognition expressions called clauses. The accelerator implements the coalesced TM version with convolution, and classifies booleanized images of 28$\times$28 pixels with 10 categories. A configuration with 128 clauses is used in a highly parallel architecture. Fast clause evaluation is obtained by keeping all clause weights and Tsetlin automata (TA) action signals in registers. The chip is implemented in a 65 nm low-leakage CMOS technology, and occupies an active area of 2.7mm$^2$. At a clock frequency of 27.8 MHz, the accelerator achieves 60.3k classifications per second, and consumes 8.6 nJ per classification. The latency for classifying a single image is 25.4 $\mu$s which includes system timing overhead. The accelerator achieves 97.42%, 84.54% and 82.55% test accuracies for the datasets MNIST, Fashion-MNIST and Kuzushiji-MNIST, respectively, matching the TM software models.
Contracting Tsetlin Machine with Absorbing Automata
Oct 17, 2023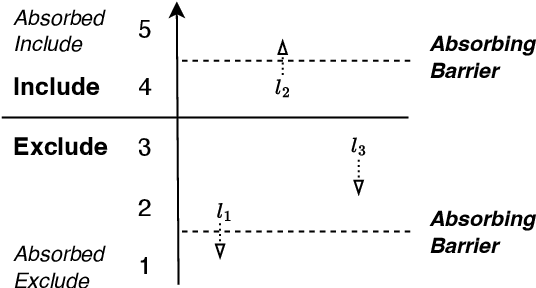
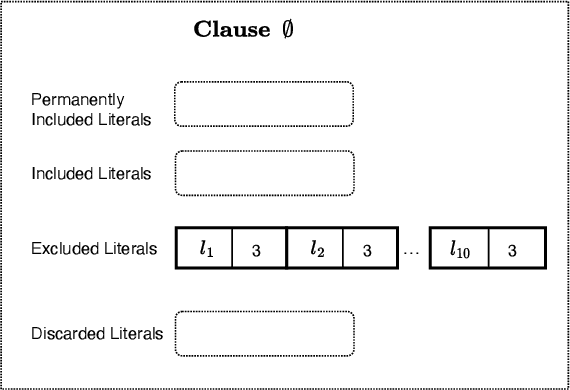
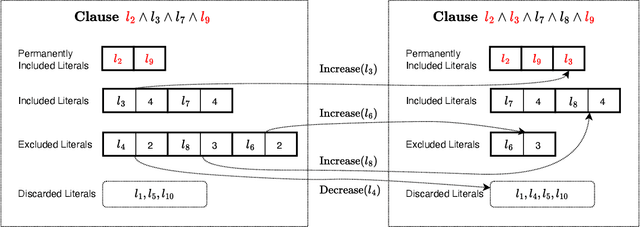
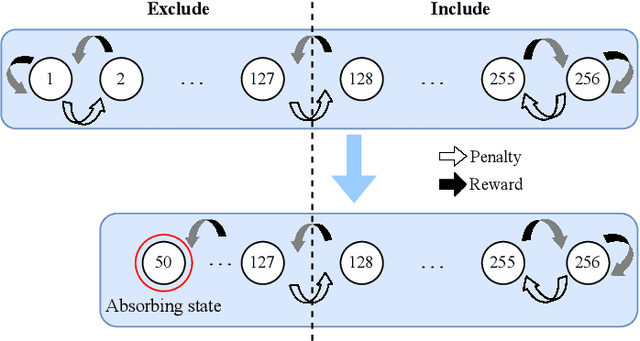
In this paper, we introduce a sparse Tsetlin Machine (TM) with absorbing Tsetlin Automata (TA) states. In brief, the TA of each clause literal has both an absorbing Exclude- and an absorbing Include state, making the learning scheme absorbing instead of ergodic. When a TA reaches an absorbing state, it will never leave that state again. If the absorbing state is an Exclude state, both the automaton and the literal can be removed from further consideration. The literal will as a result never participates in that clause. If the absorbing state is an Include state, on the other hand, the literal is stored as a permanent part of the clause while the TA is discarded. A novel sparse data structure supports these updates by means of three action lists: Absorbed Include, Include, and Exclude. By updating these lists, the TM gets smaller and smaller as the literals and their TA withdraw. In this manner, the computation accelerates during learning, leading to faster learning and less energy consumption.
Building Concise Logical Patterns by Constraining Tsetlin Machine Clause Size
Jan 19, 2023Tsetlin machine (TM) is a logic-based machine learning approach with the crucial advantages of being transparent and hardware-friendly. While TMs match or surpass deep learning accuracy for an increasing number of applications, large clause pools tend to produce clauses with many literals (long clauses). As such, they become less interpretable. Further, longer clauses increase the switching activity of the clause logic in hardware, consuming more power. This paper introduces a novel variant of TM learning - Clause Size Constrained TMs (CSC-TMs) - where one can set a soft constraint on the clause size. As soon as a clause includes more literals than the constraint allows, it starts expelling literals. Accordingly, oversized clauses only appear transiently. To evaluate CSC-TM, we conduct classification, clustering, and regression experiments on tabular data, natural language text, images, and board games. Our results show that CSC-TM maintains accuracy with up to 80 times fewer literals. Indeed, the accuracy increases with shorter clauses for TREC, IMDb, and BBC Sports. After the accuracy peaks, it drops gracefully as the clause size approaches a single literal. We finally analyze CSC-TM power consumption and derive new convergence properties.