 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Concise Logical Patterns by Constraining Tsetlin Machine Clause Size
Jan 19, 2023Tsetlin machine (TM) is a logic-based machine learning approach with the crucial advantages of being transparent and hardware-friendly. While TMs match or surpass deep learning accuracy for an increasing number of applications, large clause pools tend to produce clauses with many literals (long clauses). As such, they become less interpretable. Further, longer clauses increase the switching activity of the clause logic in hardware, consuming more power. This paper introduces a novel variant of TM learning - Clause Size Constrained TMs (CSC-TMs) - where one can set a soft constraint on the clause size. As soon as a clause includes more literals than the constraint allows, it starts expelling literals. Accordingly, oversized clauses only appear transiently. To evaluate CSC-TM, we conduct classification, clustering, and regression experiments on tabular data, natural language text, images, and board games. Our results show that CSC-TM maintains accuracy with up to 80 times fewer literals. Indeed, the accuracy increases with shorter clauses for TREC, IMDb, and BBC Sports. After the accuracy peaks, it drops gracefully as the clause size approaches a single literal. We finally analyze CSC-TM power consumption and derive new convergence properties.
Logic-based AI for Interpretable Board Game Winner Prediction with Tsetlin Machine
Mar 08, 2022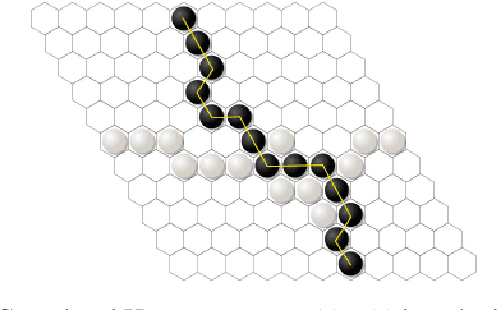
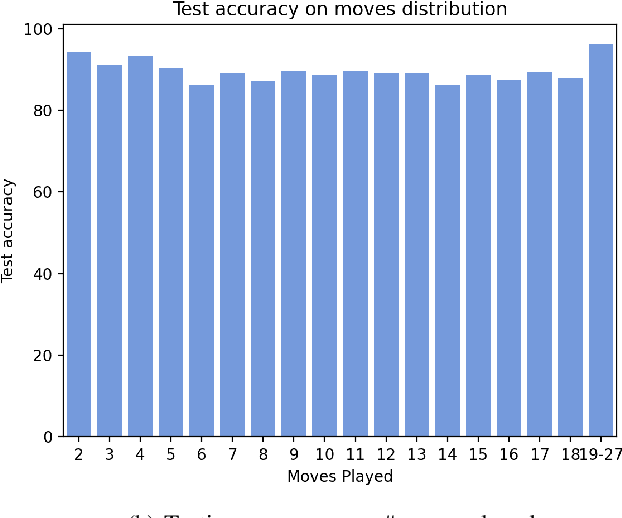
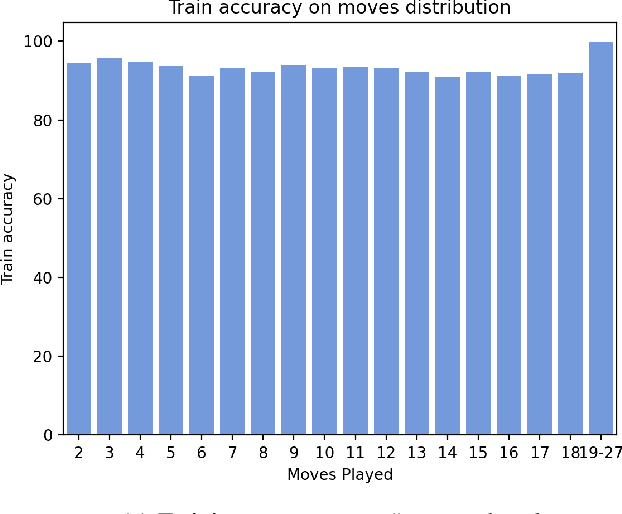
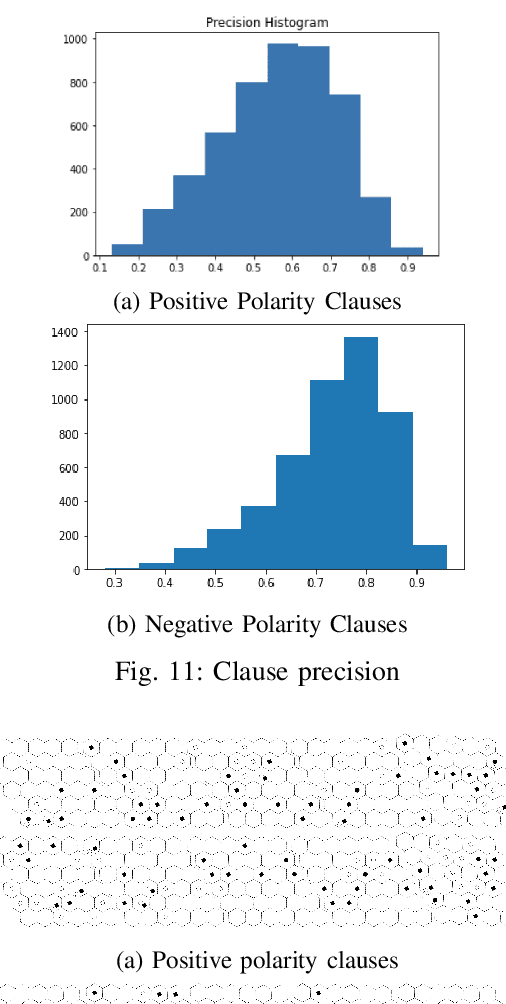
Hex is a turn-based two-player connection game with a high branching factor, making the game arbitrarily complex with increasing board sizes. As such, top-performing algorithms for playing Hex rely on accurate evaluation of board positions using neural networks. However, the limited interpretability of neural networks is problematic when the user wants to understand the reasoning behind the predictions made. In this paper, we propose to use propositional logic expressions to describe winning and losing board game positions, facilitating precise visual interpretation. We employ a Tsetlin Machine (TM) to learn these expressions from previously played games, describing where pieces must be located or not located for a board position to be strong. Extensive experiments on $6\times6$ boards compare our TM-based solution with popular machine learning algorithms like XGBoost, InterpretML, decision trees, and neural networks, considering various board configurations with $2$ to $22$ moves played. On average, the TM testing accuracy is $92.1\%$, outperforming all the other evaluated algorithms. We further demonstrate the global interpretation of the logical expressions and map them down to particular board game configurations to investigate local interpretability. We believe the resulting interpretability establishes building blocks for accurate assistive AI and human-AI collaboration, also for more complex prediction tasks.