 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Graph Intelligence: Hypervector Message Passing for Learning Graph-Level Patterns with Tsetlin Machines
Jul 22, 2025We propose a multilayered symbolic framework for general graph classification that leverages sparse binary hypervectors and Tsetlin Machines. Each graph is encoded through structured message passing, where node, edge, and attribute information are bound and bundled into a symbolic hypervector. This process preserves the hierarchical semantics of the graph through layered binding from node attributes to edge relations to structural roles resulting in a compact, discrete representation. We also formulate a local interpretability framework which lends itself to a key advantage of our approach being locally interpretable. We validate our method on TUDataset benchmarks, demonstrating competitive accuracy with strong symbolic transparency compared to neural graph models.
High resolution microprice estimates from limit orderbook data using hyperdimensional vector Tsetlin Machines
Nov 18, 2024We propose an error-correcting model for the microprice, a high-frequency estimator of future prices given higher order information of imbalances in the orderbook. The model takes into account a current microprice estimate given the spread and best bid to ask imbalance, and adjusts the microprice based on recent dynamics of higher price rank imbalances. We introduce a computationally fast estimator using a recently proposed hyperdimensional vector Tsetlin machine framework and demonstrate empirically that this estimator can provide a robust estimate of future prices in the orderbook.
Hyperdimensional Vector Tsetlin Machines with Applications to Sequence Learning and Generation
Aug 29, 2024We construct a two-layered model for learning and generating sequential data that is both computationally fast and competitive with vanilla Tsetlin machines, adding numerous advantages. Through the use of hyperdimensional vector computing (HVC) algebras and Tsetlin machine clause structures, we demonstrate that the combination of both inherits the generality of data encoding and decoding of HVC with the fast interpretable nature of Tsetlin machines to yield a powerful machine learning model. We apply the approach in two areas, namely in forecasting, generating new sequences, and classification. For the latter, we derive results for the entire UCR Time Series Archive and compare with the standard benchmarks to see how well the method competes in time series classification.
Generating Bayesian Network Models from Data Using Tsetlin Machines
May 17, 2023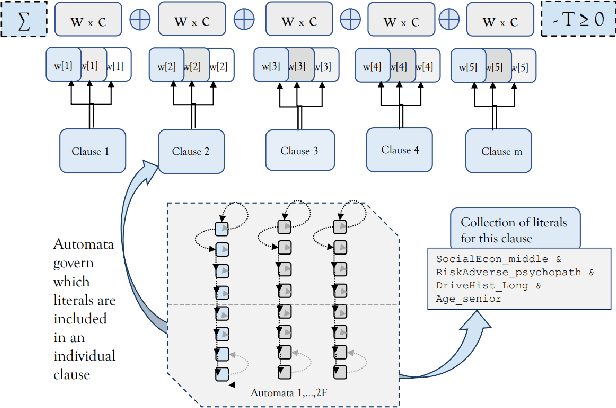
Bayesian networks (BN) are directed acyclic graphical (DAG) models that have been adopted into many fields for their strengths in transparency, interpretability, probabilistic reasoning, and causal modeling. Given a set of data, one hurdle towards using BNs is in building the network graph from the data that properly handles dependencies, whether correlated or causal. In this paper, we propose an initial methodology for discovering network structures using Tsetlin Machines.
Logic-based AI for Interpretable Board Game Winner Prediction with Tsetlin Machine
Mar 08, 2022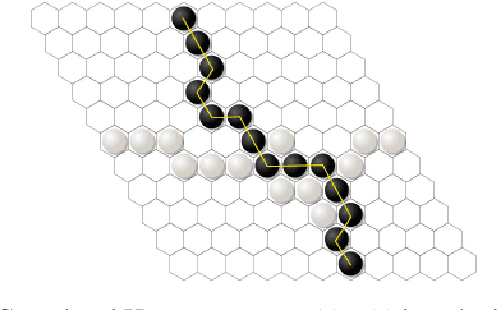
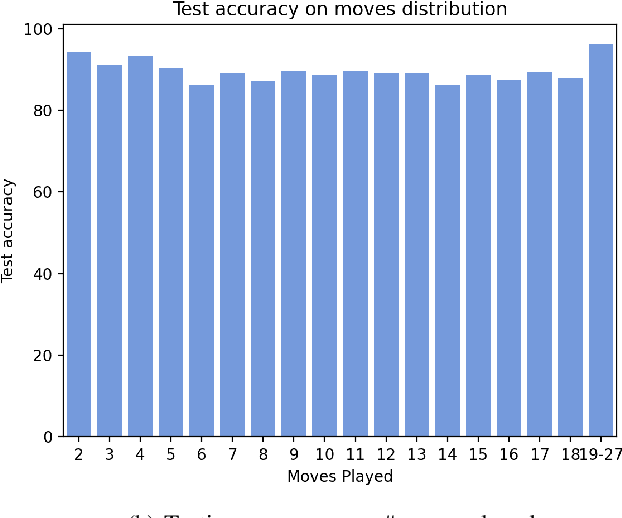
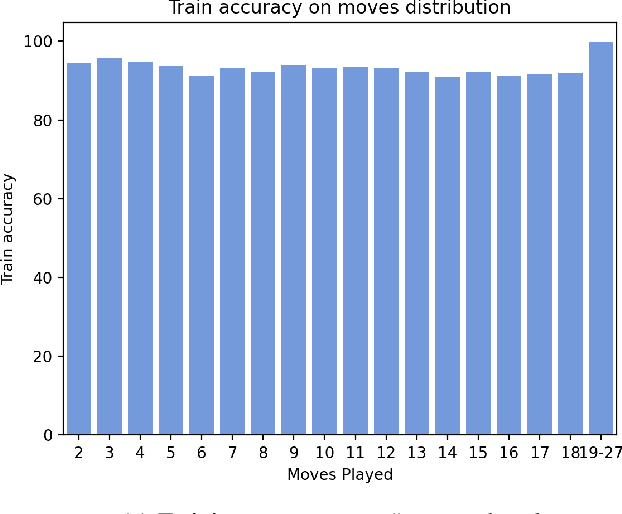
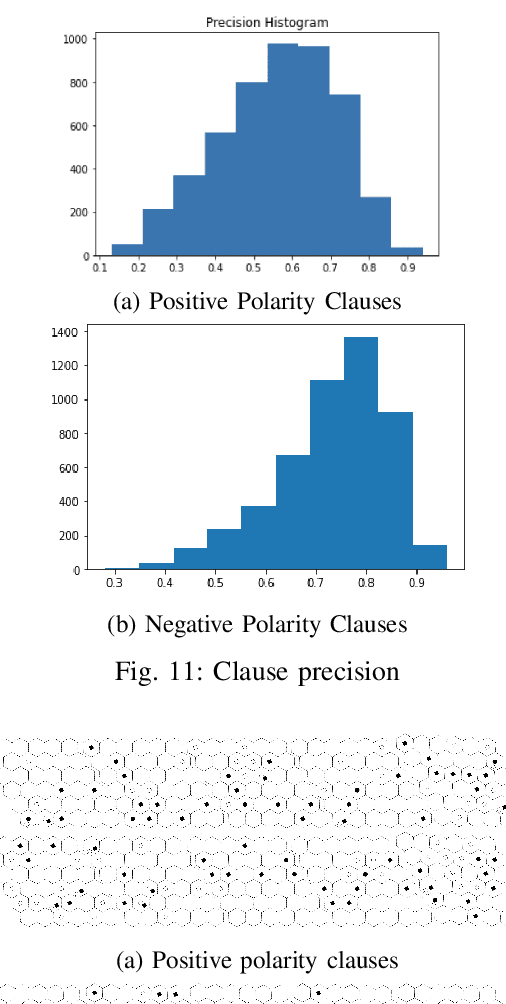
Hex is a turn-based two-player connection game with a high branching factor, making the game arbitrarily complex with increasing board sizes. As such, top-performing algorithms for playing Hex rely on accurate evaluation of board positions using neural networks. However, the limited interpretability of neural networks is problematic when the user wants to understand the reasoning behind the predictions made. In this paper, we propose to use propositional logic expressions to describe winning and losing board game positions, facilitating precise visual interpretation. We employ a Tsetlin Machine (TM) to learn these expressions from previously played games, describing where pieces must be located or not located for a board position to be strong. Extensive experiments on $6\times6$ boards compare our TM-based solution with popular machine learning algorithms like XGBoost, InterpretML, decision trees, and neural networks, considering various board configurations with $2$ to $22$ moves played. On average, the TM testing accuracy is $92.1\%$, outperforming all the other evaluated algorithms. We further demonstrate the global interpretation of the logical expressions and map them down to particular board game configurations to investigate local interpretability. We believe the resulting interpretability establishes building blocks for accurate assistive AI and human-AI collaboration, also for more complex prediction tasks.
Closed-Form Expressions for Global and Local Interpretation of Tsetlin Machines with Applications to Explaining High-Dimensional Data
Jul 27, 2020


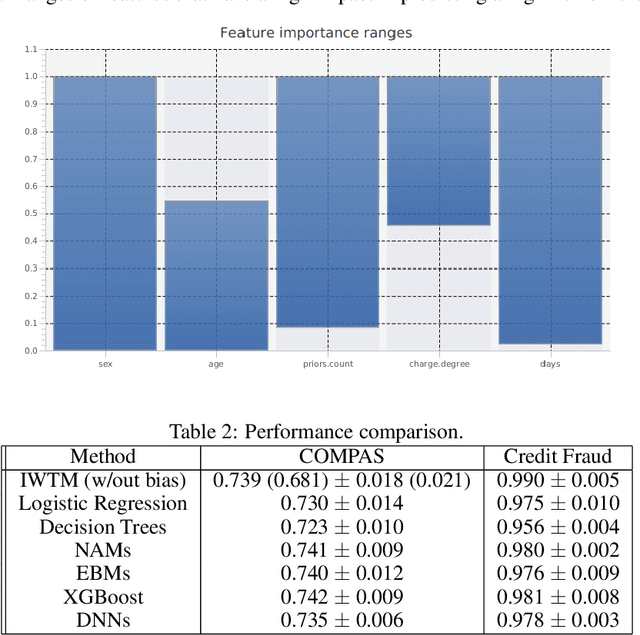
Tsetlin Machines (TMs) capture patterns using conjunctive clauses in propositional logic, thus facilitating interpretation. However, recent TM-based approaches mainly rely on inspecting the full range of clauses individually. Such inspection does not necessarily scale to complex prediction problems that require a large number of clauses. In this paper, we propose closed-form expressions for understanding why a TM model makes a specific prediction (local interpretability). Additionally, the expressions capture the most important features of the model overall (global interpretability). We further introduce expressions for measuring the importance of feature value ranges for continuous features. The expressions are formulated directly from the conjunctive clauses of the TM, making it possible to capture the role of features in real-time, also during the learning process as the model evolves. Additionally, from the closed-form expressions, we derive a novel data clustering algorithm for visualizing high-dimensional data in three dimensions. Finally, we compare our proposed approach against SHAP and state-of-the-art interpretable machine learning techniques. For both classification and regression, our evaluation show correspondence with SHAP as well as competitive prediction accuracy in comparison with XGBoost, Explainable Boosting Machines, and Neural Additive Models.