 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Driven Digital-Time-Domain Inference Architectures for Tsetlin Machines
Nov 12, 2025Machine learning fits model parameters to approximate input-output mappings, predicting unknown samples. However, these models often require extensive arithmetic computations during inference, increasing latency and power consumption. This paper proposes a digital-time-domain computing approach for Tsetlin machine (TM) inference process to address these challenges. This approach leverages a delay accumulation mechanism to mitigate the costly arithmetic sums of classes and employs a Winner-Takes-All scheme to replace conventional magnitude comparators. Specifically, a Hamming distance-driven time-domain scheme is implemented for multi-class TMs. Furthermore, differential delay paths, combined with a leading-ones-detector logarithmic delay compression digital-time-domain scheme, are utilised for the coalesced TMs, accommodating both binary-signed and exponential-scale delay accumulation issues. Compared to the functionally equivalent, post-implementation digital TM architecture baseline, the proposed architecture demonstrates orders-of-magnitude improvements in energy efficiency and throughput.
Efficient FPGA Implementation of Time-Domain Popcount for Low-Complexity Machine Learning
May 04, 2025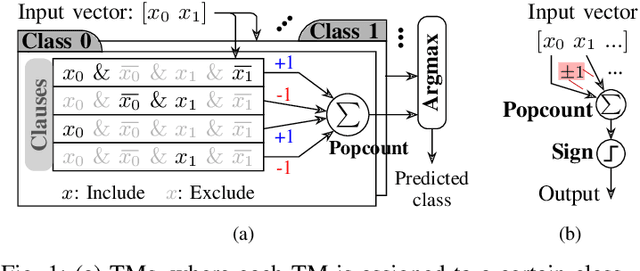
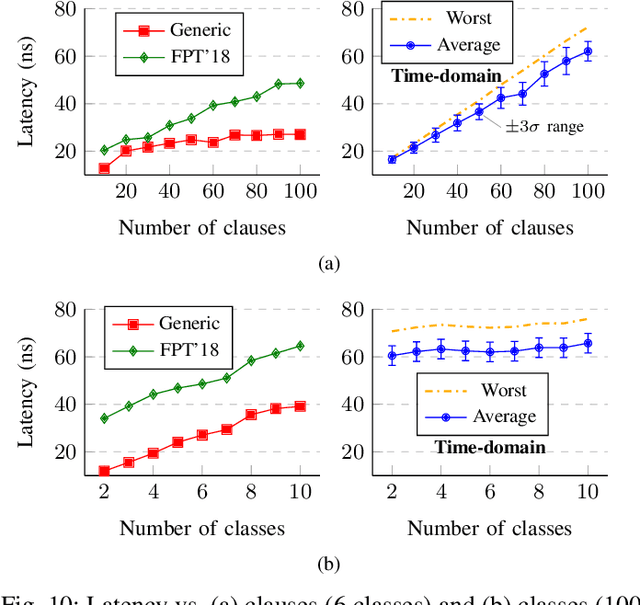
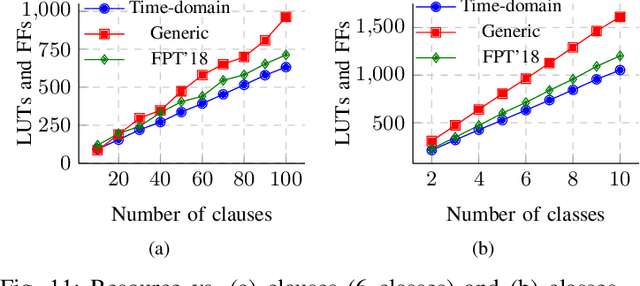
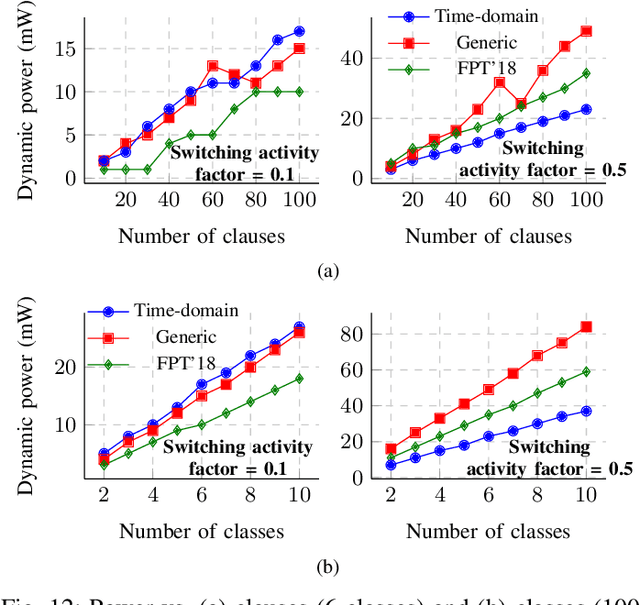
Population count (popcount) is a crucial operation for many low-complexity machine learning (ML) algorithms, including Tsetlin Machine (TM)-a promising new ML method, particularly well-suited for solving classification tasks. The inference mechanism in TM consists of propositional logic-based structures within each class, followed by a majority voting scheme, which makes the classification decision. In TM, the voters are the outputs of Boolean clauses. The voting mechanism comprises two operations: popcount for each class and determining the class with the maximum vote by means of an argmax operation. While TMs offer a lightweight ML alternative, their performance is often limited by the high computational cost of popcount and comparison required to produce the argmax result. In this paper, we propose an innovative approach to accelerate and optimize these operations by performing them in the time domain. Our time-domain implementation uses programmable delay lines (PDLs) and arbiters to efficiently manage these tasks through delay-based mechanisms. We also present an FPGA design flow for practical implementation of the time-domain popcount, addressing delay skew and ensuring that the behavior matches that of the model's intended functionality. By leveraging the natural compatibility of the proposed popcount with asynchronous architectures, we demonstrate significant improvements in an asynchronous TM, including up to 38% reduction in latency, 43.1% reduction in dynamic power, and 15% savings in resource utilization, compared to synchronous TMs using adder-based popcount.
Dynamic Tsetlin Machine Accelerators for On-Chip Training at the Edge using FPGAs
Apr 28, 2025The increased demand for data privacy and security in machine learning (ML) applications has put impetus on effective edge training on Internet-of-Things (IoT) nodes. Edge training aims to leverage speed, energy efficiency and adaptability within the resource constraints of the nodes. Deploying and training Deep Neural Networks (DNNs)-based models at the edge, although accurate, posit significant challenges from the back-propagation algorithm's complexity, bit precision trade-offs, and heterogeneity of DNN layers. This paper presents a Dynamic Tsetlin Machine (DTM) training accelerator as an alternative to DNN implementations. DTM utilizes logic-based on-chip inference with finite-state automata-driven learning within the same Field Programmable Gate Array (FPGA) package. Underpinned on the Vanilla and Coalesced Tsetlin Machine algorithms, the dynamic aspect of the accelerator design allows for a run-time reconfiguration targeting different datasets, model architectures, and model sizes without resynthesis. This makes the DTM suitable for targeting multivariate sensor-based edge tasks. Compared to DNNs, DTM trains with fewer multiply-accumulates, devoid of derivative computation. It is a data-centric ML algorithm that learns by aligning Tsetlin automata with input data to form logical propositions enabling efficient Look-up-Table (LUT) mapping and frugal Block RAM usage in FPGA training implementations. The proposed accelerator offers 2.54x more Giga operations per second per Watt (GOP/s per W) and uses 6x less power than the next-best comparable design.
Runtime Tunable Tsetlin Machines for Edge Inference on eFPGAs
Feb 10, 2025Embedded Field-Programmable Gate Arrays (eFPGAs) allow for the design of hardware accelerators of edge Machine Learning (ML) applications at a lower power budget compared with traditional FPGA platforms. However, the limited eFPGA logic and memory significantly constrain compute capabilities and model size. As such, ML application deployment on eFPGAs is in direct contrast with the most recent FPGA approaches developing architecture-specific implementations and maximizing throughput over resource frugality. This paper focuses on the opposite side of this trade-off: the proposed eFPGA accelerator focuses on minimizing resource usage and allowing flexibility for on-field recalibration over throughput. This allows for runtime changes in model size, architecture, and input data dimensionality without offline resynthesis. This is made possible through the use of a bitwise compressed inference architecture of the Tsetlin Machine (TM) algorithm. TM compute does not require any multiplication operations, being limited to only bitwise AND, OR, NOT, summations and additions. Additionally, TM model compression allows the entire model to fit within the on-chip block RAM of the eFPGA. The paper uses this accelerator to propose a strategy for runtime model tuning in the field. The proposed approach uses 2.5x fewer Look-up-Tables (LUTs) and 3.38x fewer registers than the current most resource-fugal design and achieves up to 129x energy reduction compared with low-power microcontrollers running the same ML application.
ETHEREAL: Energy-efficient and High-throughput Inference using Compressed Tsetlin Machine
Feb 08, 2025The Tsetlin Machine (TM) is a novel alternative to deep neural networks (DNNs). Unlike DNNs, which rely on multi-path arithmetic operations, a TM learns propositional logic patterns from data literals using Tsetlin automata. This fundamental shift from arithmetic to logic underpinning makes TM suitable for empowering new applications with low-cost implementations. In TM, literals are often included by both positive and negative clauses within the same class, canceling out their impact on individual class definitions. This property can be exploited to develop compressed TM models, enabling energy-efficient and high-throughput inferences for machine learning (ML) applications. We introduce a training approach that incorporates excluded automata states to sparsify TM logic patterns in both positive and negative clauses. This exclusion is iterative, ensuring that highly class-correlated (and therefore significant) literals are retained in the compressed inference model, ETHEREAL, to maintain strong classification accuracy. Compared to standard TMs, ETHEREAL TM models can reduce model size by up to 87.54%, with only a minor accuracy compromise. We validate the impact of this compression on eight real-world Tiny machine learning (TinyML) datasets against standard TM, equivalent Random Forest (RF) and Binarized Neural Network (BNN) on the STM32F746G-DISCO platform. Our results show that ETHEREAL TM models achieve over an order of magnitude reduction in inference time (resulting in higher throughput) and energy consumption compared to BNNs, while maintaining a significantly smaller memory footprint compared to RFs.
An All-digital 65-nm Tsetlin Machine Image Classification Accelerator with 8.6 nJ per MNIST Frame at 60.3k Frames per Second
Jan 31, 2025



We present an all-digital programmable machine learning accelerator chip for image classification, underpinning on the Tsetlin machine (TM) principles. The TM is a machine learning algorithm founded on propositional logic, utilizing sub-pattern recognition expressions called clauses. The accelerator implements the coalesced TM version with convolution, and classifies booleanized images of 28$\times$28 pixels with 10 categories. A configuration with 128 clauses is used in a highly parallel architecture. Fast clause evaluation is obtained by keeping all clause weights and Tsetlin automata (TA) action signals in registers. The chip is implemented in a 65 nm low-leakage CMOS technology, and occupies an active area of 2.7mm$^2$. At a clock frequency of 27.8 MHz, the accelerator achieves 60.3k classifications per second, and consumes 8.6 nJ per classification. The latency for classifying a single image is 25.4 $\mu$s which includes system timing overhead. The accelerator achieves 97.42%, 84.54% and 82.55% test accuracies for the datasets MNIST, Fashion-MNIST and Kuzushiji-MNIST, respectively, matching the TM software models.
IMPACT:InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference
Dec 04, 2024



The increasing demand for processing large volumes of data for machine learning models has pushed data bandwidth requirements beyond the capability of traditional von Neumann architecture. In-memory computing (IMC) has recently emerged as a promising solution to address this gap by enabling distributed data storage and processing at the micro-architectural level, significantly reducing both latency and energy. In this paper, we present the IMPACT: InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference, underpinned on a cutting-edge memory device, Y-Flash, fabricated on a 180 nm CMOS process. Y-Flash devices have recently been demonstrated for digital and analog memory applications, offering high yield, non-volatility, and low power consumption. The IMPACT leverages the Y-Flash array to implement the inference of a novel machine learning algorithm: coalesced Tsetlin machine (CoTM) based on propositional logic. CoTM utilizes Tsetlin automata (TA) to create Boolean feature selections stochastically across parallel clauses. The IMPACT is organized into two computational crossbars for storing the TA and weights. Through validation on the MNIST dataset, IMPACT achieved 96.3% accuracy. The IMPACT demonstrated improvements in energy efficiency, e.g., 2.23X over CNN-based ReRAM, 2.46X over Neuromorphic using NOR-Flash, and 2.06X over DNN-based PCM, suited for modern ML inference applications.
In-Memory Learning Automata Architecture using Y-Flash Cell
Aug 18, 2024



The modern implementation of machine learning architectures faces significant challenges due to frequent data transfer between memory and processing units. In-memory computing, primarily through memristor-based analog computing, offers a promising solution to overcome this von Neumann bottleneck. In this technology, data processing and storage are located inside the memory. Here, we introduce a novel approach that utilizes floating-gate Y-Flash memristive devices manufactured with a standard 180 nm CMOS process. These devices offer attractive features, including analog tunability and moderate device-to-device variation; such characteristics are essential for reliable decision-making in ML applications. This paper uses a new machine learning algorithm, the Tsetlin Machine (TM), for in-memory processing architecture. The TM's learning element, Automaton, is mapped into a single Y-Flash cell, where the Automaton's range is transferred into the Y-Flash's conductance scope. Through comprehensive simulations, the proposed hardware implementation of the learning automata, particularly for Tsetlin machines, has demonstrated enhanced scalability and on-edge learning capabilities.
Contracting Tsetlin Machine with Absorbing Automata
Oct 17, 2023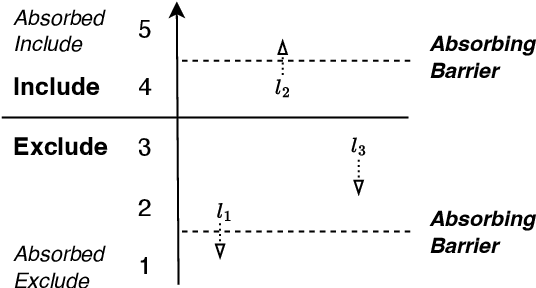
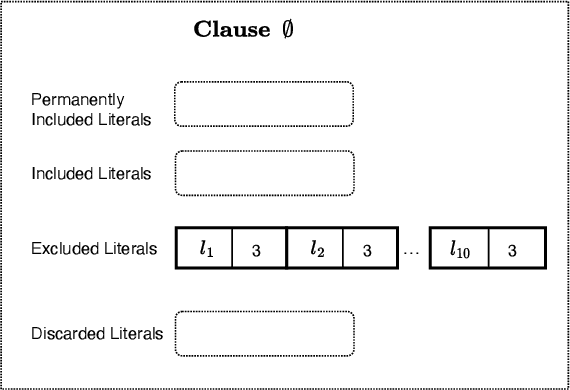
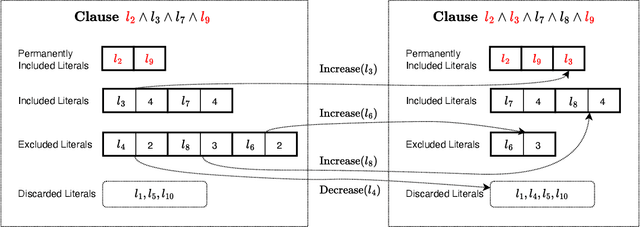
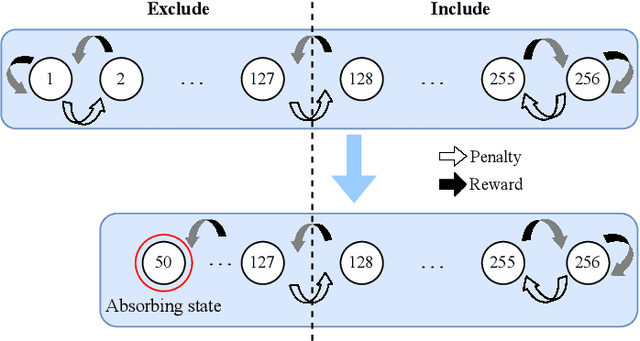
In this paper, we introduce a sparse Tsetlin Machine (TM) with absorbing Tsetlin Automata (TA) states. In brief, the TA of each clause literal has both an absorbing Exclude- and an absorbing Include state, making the learning scheme absorbing instead of ergodic. When a TA reaches an absorbing state, it will never leave that state again. If the absorbing state is an Exclude state, both the automaton and the literal can be removed from further consideration. The literal will as a result never participates in that clause. If the absorbing state is an Include state, on the other hand, the literal is stored as a permanent part of the clause while the TA is discarded. A novel sparse data structure supports these updates by means of three action lists: Absorbed Include, Include, and Exclude. By updating these lists, the TM gets smaller and smaller as the literals and their TA withdraw. In this manner, the computation accelerates during learning, leading to faster learning and less energy consumption.
An FPGA Architecture for Online Learning using the Tsetlin Machine
Jun 01, 2023


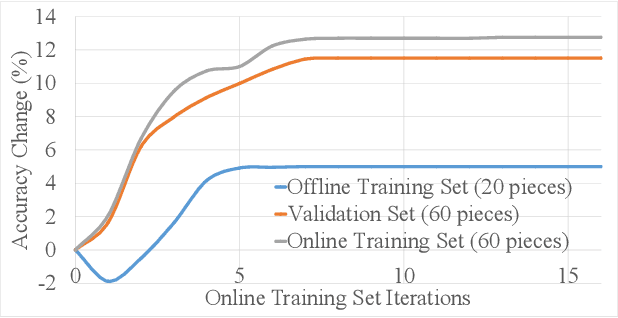
There is a need for machine learning models to evolve in unsupervised circumstances. New classifications may be introduced, unexpected faults may occur, or the initial dataset may be small compared to the data-points presented to the system during normal operation. Implementing such a system using neural networks involves significant mathematical complexity, which is a major issue in power-critical edge applications. This paper proposes a novel field-programmable gate-array infrastructure for online learning, implementing a low-complexity machine learning algorithm called the Tsetlin Machine. This infrastructure features a custom-designed architecture for run-time learning management, providing on-chip offline and online learning. Using this architecture, training can be carried out on-demand on the \ac{FPGA} with pre-classified data before inference takes place. Additionally, our architecture provisions online learning, where training can be interleaved with inference during operation. Tsetlin Machine (TM) training naturally descends to an optimum, with training also linked to a threshold hyper-parameter which is used to reduce the probability of issuing feedback as the TM becomes trained further. The proposed architecture is modular, allowing the data input source to be easily changed, whilst inbuilt cross-validation infrastructure allows for reliable and representative results during system testing. We present use cases for online learning using the proposed infrastructure and demonstrate the energy/performance/accuracy trade-offs.