 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntime Tunable Tsetlin Machines for Edge Inference on eFPGAs
Feb 10, 2025Embedded Field-Programmable Gate Arrays (eFPGAs) allow for the design of hardware accelerators of edge Machine Learning (ML) applications at a lower power budget compared with traditional FPGA platforms. However, the limited eFPGA logic and memory significantly constrain compute capabilities and model size. As such, ML application deployment on eFPGAs is in direct contrast with the most recent FPGA approaches developing architecture-specific implementations and maximizing throughput over resource frugality. This paper focuses on the opposite side of this trade-off: the proposed eFPGA accelerator focuses on minimizing resource usage and allowing flexibility for on-field recalibration over throughput. This allows for runtime changes in model size, architecture, and input data dimensionality without offline resynthesis. This is made possible through the use of a bitwise compressed inference architecture of the Tsetlin Machine (TM) algorithm. TM compute does not require any multiplication operations, being limited to only bitwise AND, OR, NOT, summations and additions. Additionally, TM model compression allows the entire model to fit within the on-chip block RAM of the eFPGA. The paper uses this accelerator to propose a strategy for runtime model tuning in the field. The proposed approach uses 2.5x fewer Look-up-Tables (LUTs) and 3.38x fewer registers than the current most resource-fugal design and achieves up to 129x energy reduction compared with low-power microcontrollers running the same ML application.
An Energy-efficient Capacitive-Memristive Content Addressable Memory
Jan 17, 2024



Content addressable memory is popular in the field of intelligent computing systems with its searching nature. Emerging CAMs show a promising increase in pixel density and a decrease in power consumption than pure CMOS solutions. This article introduced an energy-efficient 3T1R1C TCAM cooperating with capacitor dividers and RRAM devices. The RRAM as a storage element also acts as a switch to the capacitor divider while searching for content. CAM cells benefit from working parallel in an array structure. We implemented a 64 x 64 array and digital controllers to perform with an internal built-in clock frequency of 875MHz. Both data searches and reads take 3x clock cycles. Its worst average energy for data match is reported to be 1.71 fJ/bit-search and the worst average energy for data miss is found with 4.69 fJ/bit-search. The prototype is simulated and fabricated in 0.18 um technology with in-lab RRAM post-processing. Such memory explores the charge domain searching mechanism and can be applied to data centers that are power-hungry.
An FPGA Architecture for Online Learning using the Tsetlin Machine
Jun 01, 2023


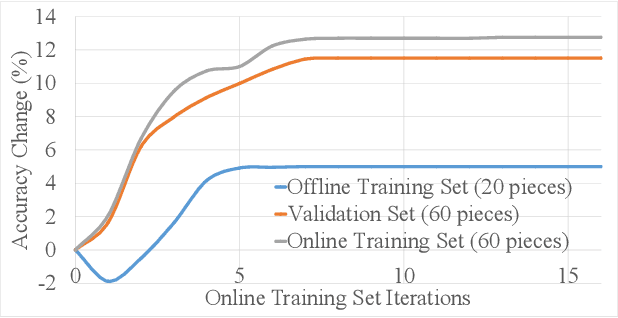
There is a need for machine learning models to evolve in unsupervised circumstances. New classifications may be introduced, unexpected faults may occur, or the initial dataset may be small compared to the data-points presented to the system during normal operation. Implementing such a system using neural networks involves significant mathematical complexity, which is a major issue in power-critical edge applications. This paper proposes a novel field-programmable gate-array infrastructure for online learning, implementing a low-complexity machine learning algorithm called the Tsetlin Machine. This infrastructure features a custom-designed architecture for run-time learning management, providing on-chip offline and online learning. Using this architecture, training can be carried out on-demand on the \ac{FPGA} with pre-classified data before inference takes place. Additionally, our architecture provisions online learning, where training can be interleaved with inference during operation. Tsetlin Machine (TM) training naturally descends to an optimum, with training also linked to a threshold hyper-parameter which is used to reduce the probability of issuing feedback as the TM becomes trained further. The proposed architecture is modular, allowing the data input source to be easily changed, whilst inbuilt cross-validation infrastructure allows for reliable and representative results during system testing. We present use cases for online learning using the proposed infrastructure and demonstrate the energy/performance/accuracy trade-offs.
Energy-frugal and Interpretable AI Hardware Design using Learning Automata
May 19, 2023



Energy efficiency is a crucial requirement for enabling powerful artificial intelligence applications at the microedge. Hardware acceleration with frugal architectural allocation is an effective method for reducing energy. Many emerging applications also require the systems design to incorporate interpretable decision models to establish responsibility and transparency. The design needs to provision for additional resources to provide reachable states in real-world data scenarios, defining conflicting design tradeoffs between energy efficiency. is challenging. Recently a new machine learning algorithm, called the Tsetlin machine, has been proposed. The algorithm is fundamentally based on the principles of finite-state automata and benefits from natural logic underpinning rather than arithmetic. In this paper, we investigate methods of energy-frugal artificial intelligence hardware design by suitably tuning the hyperparameters, while maintaining high learning efficacy. To demonstrate interpretability, we use reachability and game-theoretic analysis in two simulation environments: a SystemC model to study the bounded state transitions in the presence of hardware faults and Nash equilibrium between states to analyze the learning convergence. Our analyses provides the first insights into conflicting design tradeoffs involved in energy-efficient and interpretable decision models for this new artificial intelligence hardware architecture. We show that frugal resource allocation coupled with systematic prodigality between randomized reinforcements can provide decisive energy reduction while also achieving robust and interpretable learning.
Self-timed Reinforcement Learning using Tsetlin Machine
Sep 02, 2021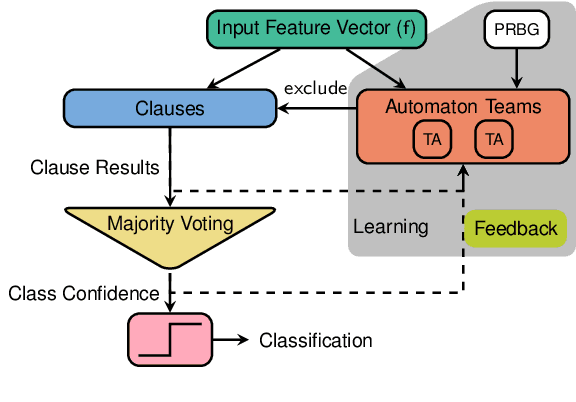

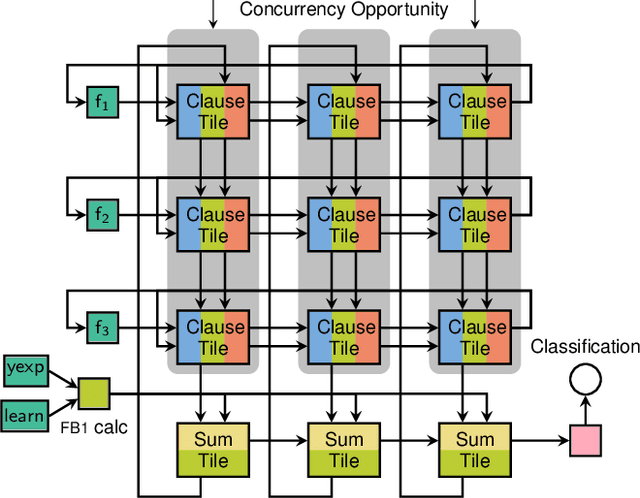
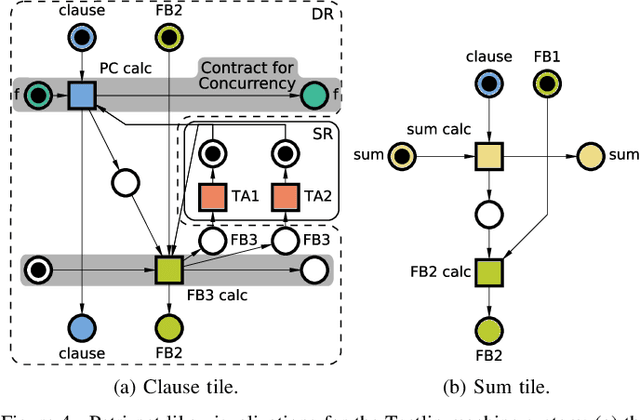
We present a hardware design for the learning datapath of the Tsetlin machine algorithm, along with a latency analysis of the inference datapath. In order to generate a low energy hardware which is suitable for pervasive artificial intelligence applications, we use a mixture of asynchronous design techniques - including Petri nets, signal transition graphs, dual-rail and bundled-data. The work builds on previous design of the inference hardware, and includes an in-depth breakdown of the automaton feedback, probability generation and Tsetlin automata. Results illustrate the advantages of asynchronous design in applications such as personalized healthcare and battery-powered internet of things devices, where energy is limited and latency is an important figure of merit. Challenges of static timing analysis in asynchronous circuits are also addressed.
Low-Power Audio Keyword Spotting using Tsetlin Machines
Jan 27, 2021The emergence of Artificial Intelligence (AI) driven Keyword Spotting (KWS) technologies has revolutionized human to machine interaction. Yet, the challenge of end-to-end energy efficiency, memory footprint and system complexity of current Neural Network (NN) powered AI-KWS pipelines has remained ever present. This paper evaluates KWS utilizing a learning automata powered machine learning algorithm called the Tsetlin Machine (TM). Through significant reduction in parameter requirements and choosing logic over arithmetic based processing, the TM offers new opportunities for low-power KWS while maintaining high learning efficacy. In this paper we explore a TM based keyword spotting (KWS) pipeline to demonstrate low complexity with faster rate of convergence compared to NNs. Further, we investigate the scalability with increasing keywords and explore the potential for enabling low-power on-chip KWS.
* 20 pp
Low-Latency Asynchronous Logic Design for Inference at the Edge
Dec 07, 2020



Modern internet of things (IoT) devices leverage machine learning inference using sensed data on-device rather than offloading them to the cloud. Commonly known as inference at-the-edge, this gives many benefits to the users, including personalization and security. However, such applications demand high energy efficiency and robustness. In this paper we propose a method for reduced area and power overhead of self-timed early-propagative asynchronous inference circuits, designed using the principles of learning automata. Due to natural resilience to timing as well as logic underpinning, the circuits are tolerant to variations in environment and supply voltage whilst enabling the lowest possible latency. Our method is exemplified through an inference datapath for a low power machine learning application. The circuit builds on the Tsetlin machine algorithm further enhancing its energy efficiency. Average latency of the proposed circuit is reduced by 10x compared with the synchronous implementation whilst maintaining similar area. Robustness of the proposed circuit is proven through post-synthesis simulation with 0.25 V to 1.2 V supply. Functional correctness is maintained and latency scales with gate delay as voltage is decreased.
A Novel Multi-Step Finite-State Automaton for Arbitrarily Deterministic Tsetlin Machine Learning
Jul 04, 2020

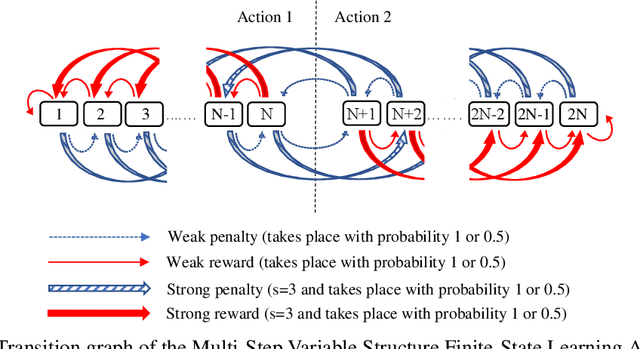
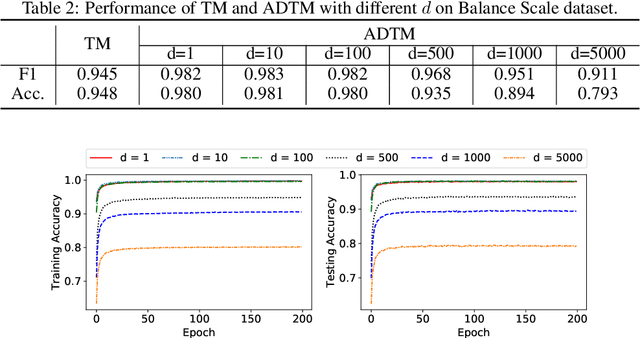
Due to the high energy consumption and scalability challenges of deep learning, there is a critical need to shift research focus towards dealing with energy consumption constraints. Tsetlin Machines (TMs) are a recent approach to machine learning that has demonstrated significantly reduced energy usage compared to neural networks alike, while performing competitively accuracy-wise on several benchmarks. However, TMs rely heavily on energy-costly random number generation to stochastically guide a team of Tsetlin Automata to a Nash Equilibrium of the TM game. In this paper, we propose a novel finite-state learning automaton that can replace the Tsetlin Automata in TM learning, for increased determinism. The new automaton uses multi-step deterministic state jumps to reinforce sub-patterns. Simultaneously, flipping a coin to skip every $d$'th state update ensures diversification by randomization. The $d$-parameter thus allows the degree of randomization to be finely controlled. E.g., $d=1$ makes every update random and $d=\infty$ makes the automaton completely deterministic. Our empirical results show that, overall, only substantial degrees of determinism reduces accuracy. Energy-wise, random number generation constitutes switching energy consumption of the TM, saving up to 11 mW power for larger datasets with high $d$ values. We can thus use the new $d$-parameter to trade off accuracy against energy consumption, to facilitate low-energy machine learning.