 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOISMA: On-the-fly In-memory Stochastic Multiplication Architecture for Matrix-Multiplication Workloads
Aug 12, 2025Artificial Intelligence models are currently driven by a significant up-scaling of their complexity, with massive matrix multiplication workloads representing the major computational bottleneck. In-memory computing architectures are proposed to avoid the Von Neumann bottleneck. However, both digital/binary-based and analogue in-memory computing architectures suffer from various limitations, which significantly degrade the performance and energy efficiency gains. This work proposes OISMA, a novel in-memory computing architecture that utilizes the computational simplicity of a quasi-stochastic computing domain (Bent-Pyramid system), while keeping the same efficiency, scalability, and productivity of digital memories. OISMA converts normal memory read operations into in-situ stochastic multiplication operations with a negligible cost. An accumulation periphery then accumulates the output multiplication bitstreams, achieving the matrix multiplication functionality. Extensive matrix multiplication benchmarking was conducted to analyze the accuracy of the Bent-Pyramid system, using matrix dimensions ranging from 4x4 to 512x512. The accuracy results show a significant decrease in the average relative Frobenius error, from 9.42% (for 4x4) to 1.81% (for 512x512), compared to 64-bit double precision floating-point format. A 1T1R OISMA array of 4 KB capacity was implemented using a commercial 180nm technology node and in-house RRAM technology. At 50 MHz, OISMA achieves 0.891 TOPS/W and 3.98 GOPS/mm2 for energy and area efficiency, respectively, occupying an effective computing area of 0.804241 mm2. Scaling OISMA from 180nm to 22nm technology shows a significant improvement of two orders of magnitude in energy efficiency and one order of magnitude in area efficiency, compared to dense matrix multiplication in-memory computing architectures.
TrIM: Triangular Input Movement Systolic Array for Convolutional Neural Networks -- Part I: Dataflow and Analytical Modelling
Aug 02, 2024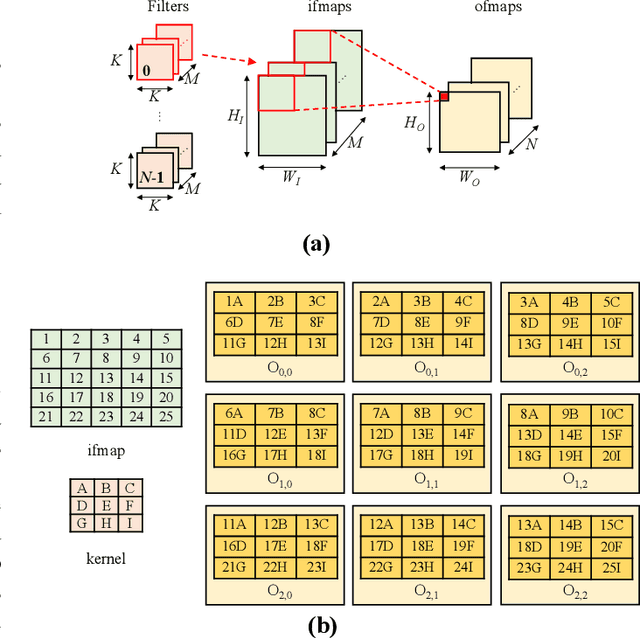
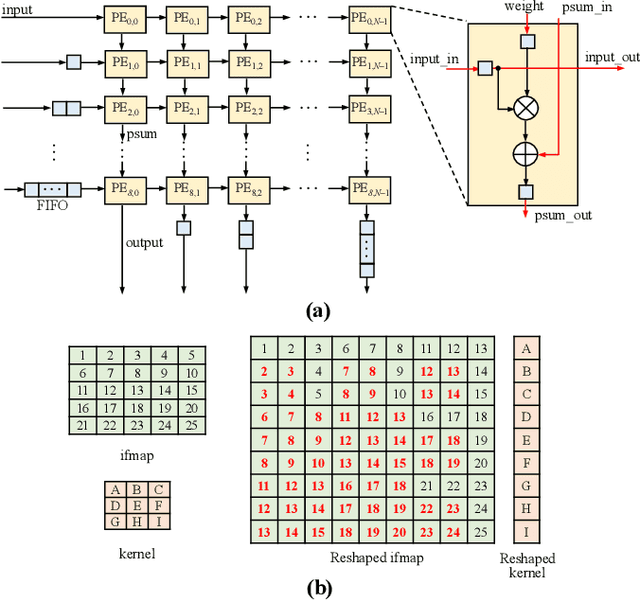
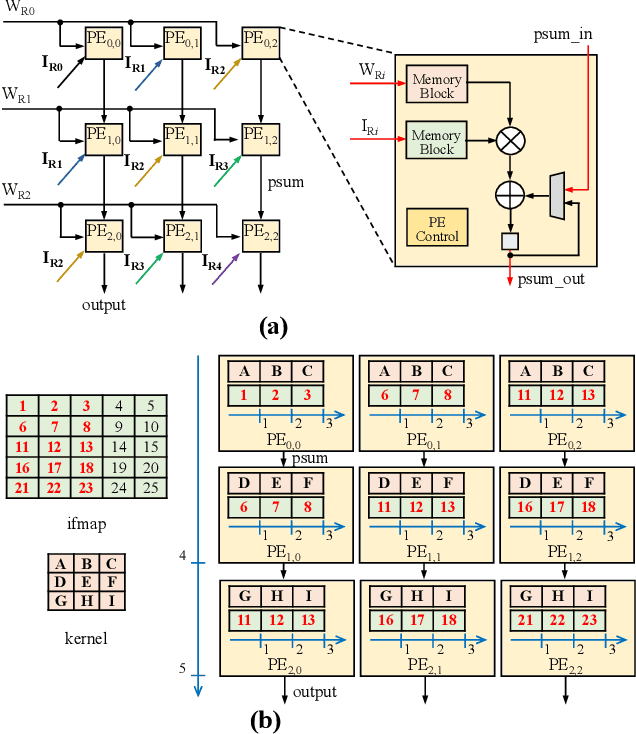
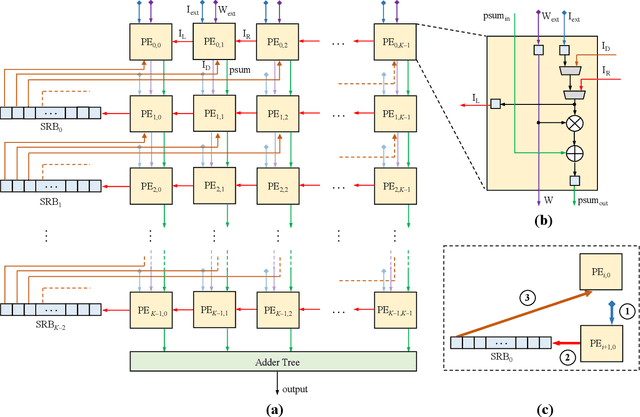
In order to follow the ever-growing computational complexity and data intensity of state-of-the-art AI models, new computing paradigms are being proposed. These paradigms aim at achieving high energy efficiency, by mitigating the Von Neumann bottleneck that relates to the energy cost of moving data between the processing cores and the memory. Convolutional Neural Networks (CNNs) are particularly susceptible to this bottleneck, given the massive data they have to manage. Systolic Arrays (SAs) are promising architectures to mitigate the data transmission cost, thanks to high data utilization carried out by an array of Processing Elements (PEs). These PEs continuously exchange and process data locally based on specific dataflows (like weight stationary and row stationary), in turn reducing the number of memory accesses to the main memory. The hardware specialization of SAs can meet different workloads, ranging from matrix multiplications to multi-dimensional convolutions. In this paper, we propose TrIM: a novel dataflow for SAs based on a Triangular Input Movement and compatible with CNN computing. When compared to state-of-the-art SA dataflows, like weight stationary and row stationary, the high data utilization offered by TrIM guarantees ~10x less memory access. Furthermore, considering that PEs continuously overlap multiplications and accumulations, TrIM achieves high throughput (up to 81.8% higher than row stationary), other than requiring a limited number of registers (up to 15.6x fewer registers than row stationary).
An Energy-efficient Capacitive-Memristive Content Addressable Memory
Jan 17, 2024



Content addressable memory is popular in the field of intelligent computing systems with its searching nature. Emerging CAMs show a promising increase in pixel density and a decrease in power consumption than pure CMOS solutions. This article introduced an energy-efficient 3T1R1C TCAM cooperating with capacitor dividers and RRAM devices. The RRAM as a storage element also acts as a switch to the capacitor divider while searching for content. CAM cells benefit from working parallel in an array structure. We implemented a 64 x 64 array and digital controllers to perform with an internal built-in clock frequency of 875MHz. Both data searches and reads take 3x clock cycles. Its worst average energy for data match is reported to be 1.71 fJ/bit-search and the worst average energy for data miss is found with 4.69 fJ/bit-search. The prototype is simulated and fabricated in 0.18 um technology with in-lab RRAM post-processing. Such memory explores the charge domain searching mechanism and can be applied to data centers that are power-hungry.