 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrIM: Triangular Input Movement Systolic Array for Convolutional Neural Networks -- Part I: Dataflow and Analytical Modelling
Aug 02, 2024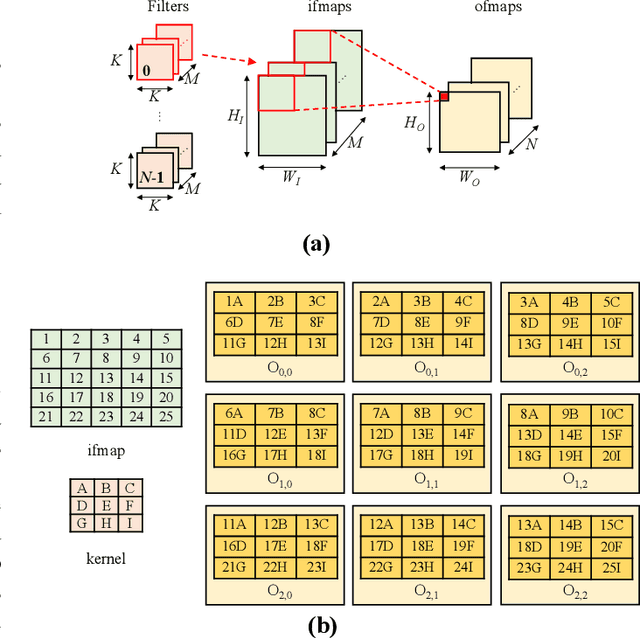
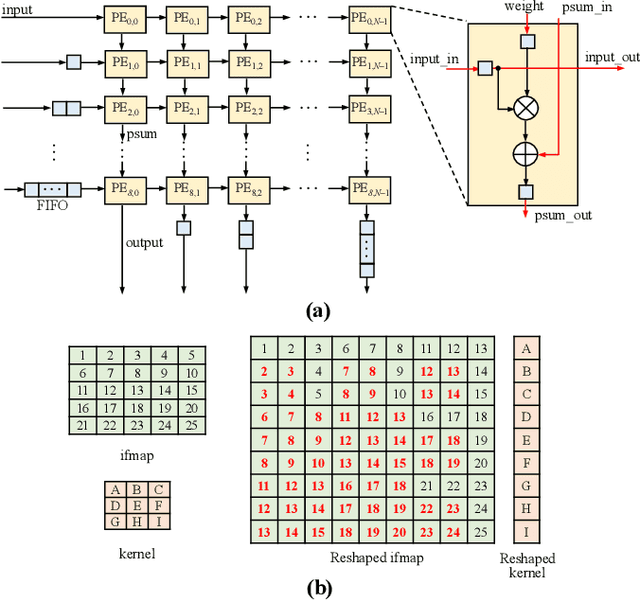
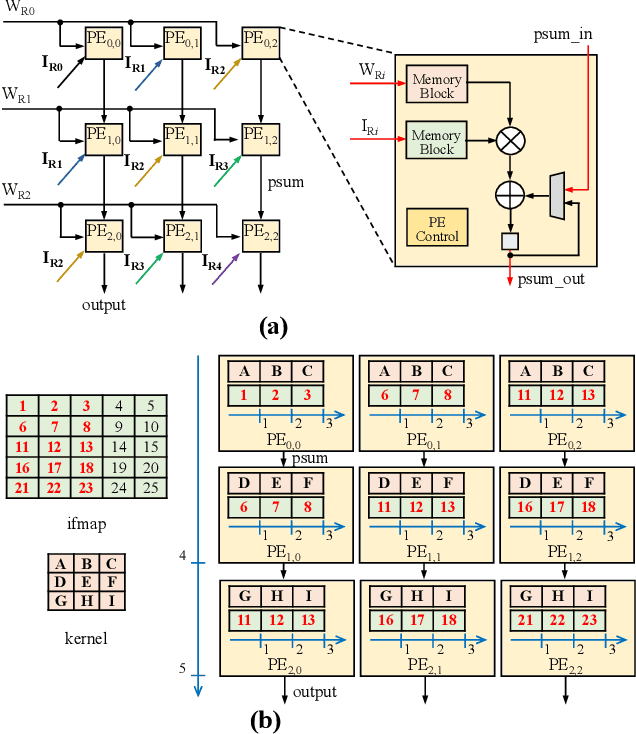
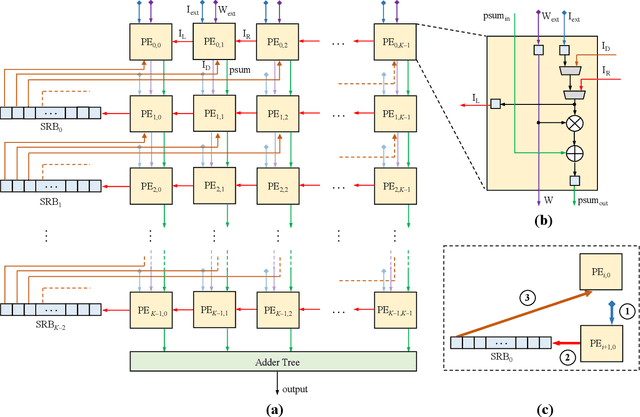
In order to follow the ever-growing computational complexity and data intensity of state-of-the-art AI models, new computing paradigms are being proposed. These paradigms aim at achieving high energy efficiency, by mitigating the Von Neumann bottleneck that relates to the energy cost of moving data between the processing cores and the memory. Convolutional Neural Networks (CNNs) are particularly susceptible to this bottleneck, given the massive data they have to manage. Systolic Arrays (SAs) are promising architectures to mitigate the data transmission cost, thanks to high data utilization carried out by an array of Processing Elements (PEs). These PEs continuously exchange and process data locally based on specific dataflows (like weight stationary and row stationary), in turn reducing the number of memory accesses to the main memory. The hardware specialization of SAs can meet different workloads, ranging from matrix multiplications to multi-dimensional convolutions. In this paper, we propose TrIM: a novel dataflow for SAs based on a Triangular Input Movement and compatible with CNN computing. When compared to state-of-the-art SA dataflows, like weight stationary and row stationary, the high data utilization offered by TrIM guarantees ~10x less memory access. Furthermore, considering that PEs continuously overlap multiplications and accumulations, TrIM achieves high throughput (up to 81.8% higher than row stationary), other than requiring a limited number of registers (up to 15.6x fewer registers than row stationary).