 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOISMA: On-the-fly In-memory Stochastic Multiplication Architecture for Matrix-Multiplication Workloads
Aug 12, 2025Artificial Intelligence models are currently driven by a significant up-scaling of their complexity, with massive matrix multiplication workloads representing the major computational bottleneck. In-memory computing architectures are proposed to avoid the Von Neumann bottleneck. However, both digital/binary-based and analogue in-memory computing architectures suffer from various limitations, which significantly degrade the performance and energy efficiency gains. This work proposes OISMA, a novel in-memory computing architecture that utilizes the computational simplicity of a quasi-stochastic computing domain (Bent-Pyramid system), while keeping the same efficiency, scalability, and productivity of digital memories. OISMA converts normal memory read operations into in-situ stochastic multiplication operations with a negligible cost. An accumulation periphery then accumulates the output multiplication bitstreams, achieving the matrix multiplication functionality. Extensive matrix multiplication benchmarking was conducted to analyze the accuracy of the Bent-Pyramid system, using matrix dimensions ranging from 4x4 to 512x512. The accuracy results show a significant decrease in the average relative Frobenius error, from 9.42% (for 4x4) to 1.81% (for 512x512), compared to 64-bit double precision floating-point format. A 1T1R OISMA array of 4 KB capacity was implemented using a commercial 180nm technology node and in-house RRAM technology. At 50 MHz, OISMA achieves 0.891 TOPS/W and 3.98 GOPS/mm2 for energy and area efficiency, respectively, occupying an effective computing area of 0.804241 mm2. Scaling OISMA from 180nm to 22nm technology shows a significant improvement of two orders of magnitude in energy efficiency and one order of magnitude in area efficiency, compared to dense matrix multiplication in-memory computing architectures.
Adiabatic Capacitive Neuron: An Energy-Efficient Functional Unit for Artificial Neural Networks
Jul 01, 2025This paper introduces a new, highly energy-efficient, Adiabatic Capacitive Neuron (ACN) hardware implementation of an Artificial Neuron (AN) with improved functionality, accuracy, robustness and scalability over previous work. The paper describes the implementation of a \mbox{12-bit} single neuron, with positive and negative weight support, in an $\mathbf{0.18\mu m}$ CMOS technology. The paper also presents a new Threshold Logic (TL) design for a binary AN activation function that generates a low symmetrical offset across three process corners and five temperatures between $-55^o$C and $125^o$C. Post-layout simulations demonstrate a maximum rising and falling offset voltage of 9$mV$ compared to conventional TL, which has rising and falling offset voltages of 27$mV$ and 5$mV$ respectively, across temperature and process. Moreover, the proposed TL design shows a decrease in average energy of 1.5$\%$ at the SS corner and 2.3$\%$ at FF corner compared to the conventional TL design. The total synapse energy saving for the proposed ACN was above 90$\%$ (over 12x improvement) when compared to a non-adiabatic CMOS Capacitive Neuron (CCN) benchmark for a frequency ranging from 500$kHz$ to 100$MHz$. A 1000-sample Monte Carlo simulation including process variation and mismatch confirms the worst-case energy savings of $\>$90$\%$ compared to CCN in the synapse energy profile. Finally, the impact of supply voltage scaling shows consistent energy savings of above 90$\%$ (except all zero inputs) without loss of functionality.
TrIM: Triangular Input Movement Systolic Array for Convolutional Neural Networks -- Part I: Dataflow and Analytical Modelling
Aug 02, 2024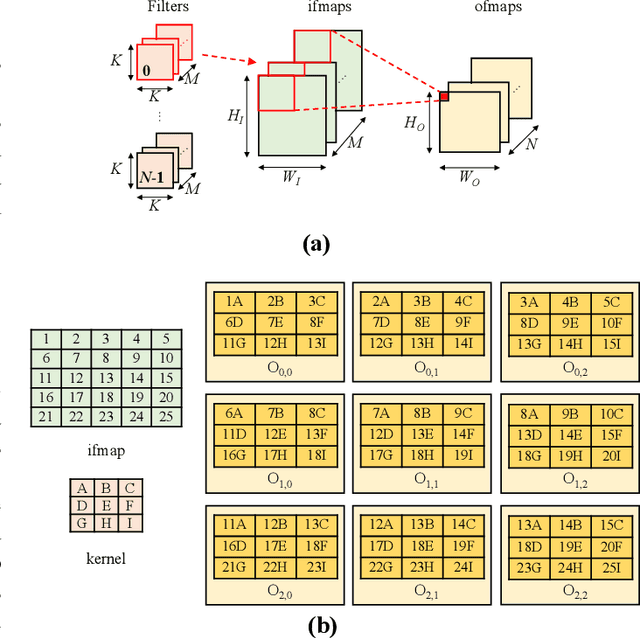
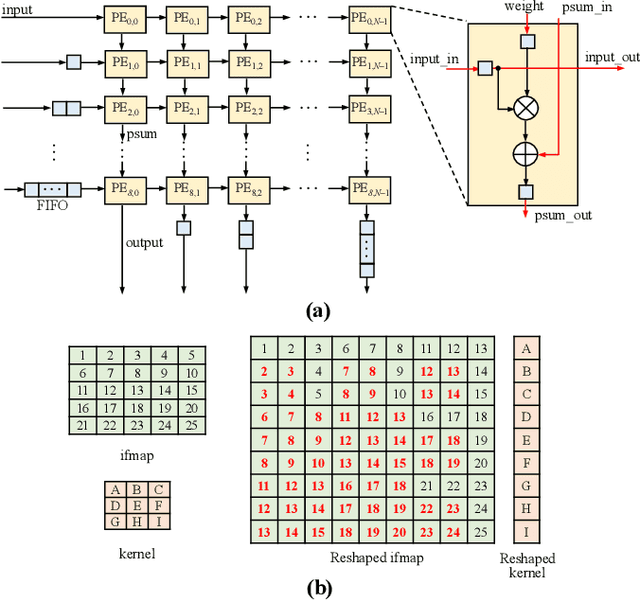
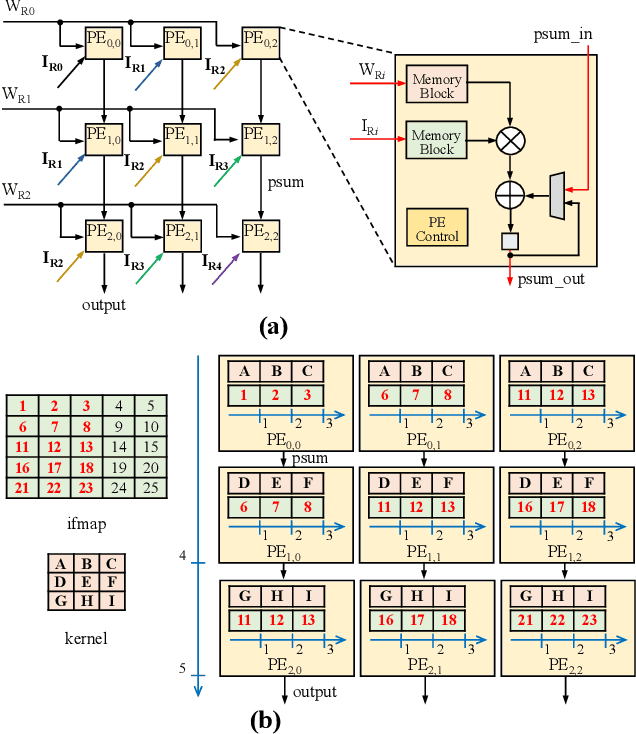
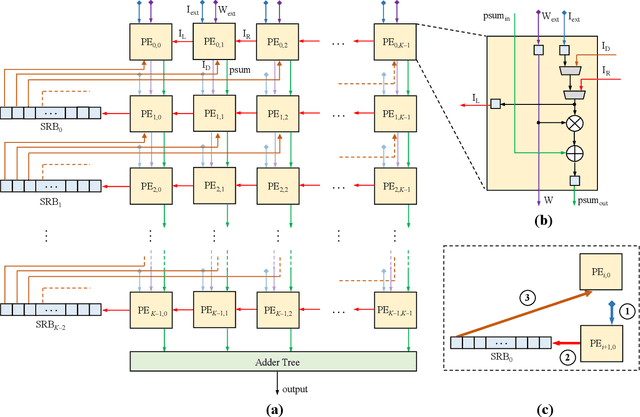
In order to follow the ever-growing computational complexity and data intensity of state-of-the-art AI models, new computing paradigms are being proposed. These paradigms aim at achieving high energy efficiency, by mitigating the Von Neumann bottleneck that relates to the energy cost of moving data between the processing cores and the memory. Convolutional Neural Networks (CNNs) are particularly susceptible to this bottleneck, given the massive data they have to manage. Systolic Arrays (SAs) are promising architectures to mitigate the data transmission cost, thanks to high data utilization carried out by an array of Processing Elements (PEs). These PEs continuously exchange and process data locally based on specific dataflows (like weight stationary and row stationary), in turn reducing the number of memory accesses to the main memory. The hardware specialization of SAs can meet different workloads, ranging from matrix multiplications to multi-dimensional convolutions. In this paper, we propose TrIM: a novel dataflow for SAs based on a Triangular Input Movement and compatible with CNN computing. When compared to state-of-the-art SA dataflows, like weight stationary and row stationary, the high data utilization offered by TrIM guarantees ~10x less memory access. Furthermore, considering that PEs continuously overlap multiplications and accumulations, TrIM achieves high throughput (up to 81.8% higher than row stationary), other than requiring a limited number of registers (up to 15.6x fewer registers than row stationary).
An Energy-efficient Capacitive-Memristive Content Addressable Memory
Jan 17, 2024



Content addressable memory is popular in the field of intelligent computing systems with its searching nature. Emerging CAMs show a promising increase in pixel density and a decrease in power consumption than pure CMOS solutions. This article introduced an energy-efficient 3T1R1C TCAM cooperating with capacitor dividers and RRAM devices. The RRAM as a storage element also acts as a switch to the capacitor divider while searching for content. CAM cells benefit from working parallel in an array structure. We implemented a 64 x 64 array and digital controllers to perform with an internal built-in clock frequency of 875MHz. Both data searches and reads take 3x clock cycles. Its worst average energy for data match is reported to be 1.71 fJ/bit-search and the worst average energy for data miss is found with 4.69 fJ/bit-search. The prototype is simulated and fabricated in 0.18 um technology with in-lab RRAM post-processing. Such memory explores the charge domain searching mechanism and can be applied to data centers that are power-hungry.
A Dual Threshold Analogue Content Addressable Memory
Mar 05, 2023



Advances in machine learning and neuromorphic systems are fuelled by the development of architectures required for these applications, such as content addressable memory. In an attempt to address this need, this paper presents a new RRAM tuned window comparator, building upon existing work in reconfigurable computing. The circuit uses a low component count at 6T2R2M, comparable with the most compact existing cells of this type. This paper will present this design, demonstrating its operation with TiOx memristive devices, showing its controllability and specificity. This paper will then simulate the energy dissipated in its operation, showing it to be below 100pJ per test, comparable to existing works.
Text Classification in Memristor-based Spiking Neural Networks
Jul 31, 2022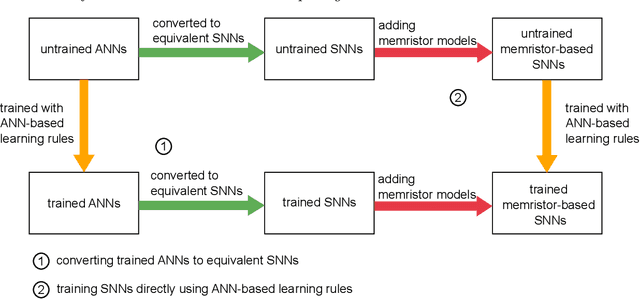

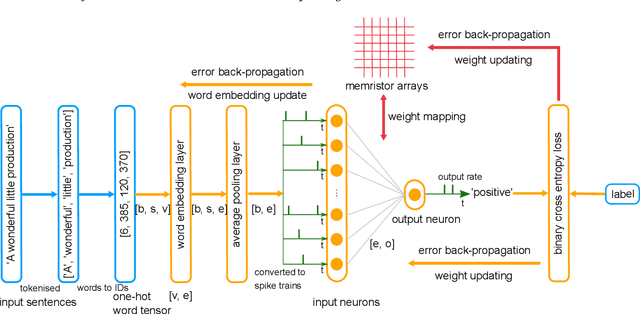
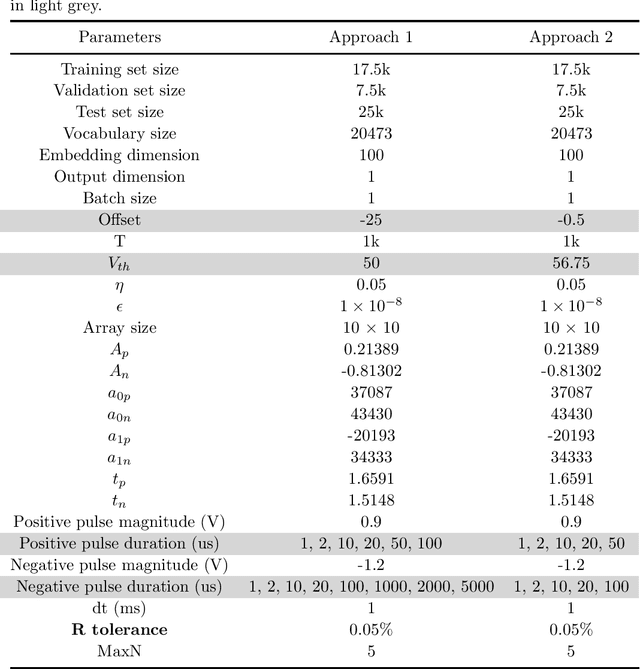
Memristors, emerging non-volatile memory devices, have shown promising potential in neuromorphic hardware designs, especially in spiking neural network (SNN) hardware implementation. Memristor-based SNNs have been successfully applied in a wide range of various applications, including image classification and pattern recognition. However, implementing memristor-based SNNs in text classification is still under exploration. One of the main reasons is that training memristor-based SNNs for text classification is costly due to the lack of efficient learning rules and memristor non-idealities. To address these issues and accelerate the research of exploring memristor-based spiking neural networks in text classification applications, we develop a simulation framework with a virtual memristor array using an empirical memristor model. We use this framework to demonstrate a sentiment analysis task in the IMDB movie reviews dataset. We take two approaches to obtain trained spiking neural networks with memristor models: 1) by converting a pre-trained artificial neural network (ANN) to a memristor-based SNN, or 2) by training a memristor-based SNN directly. These two approaches can be applied in two scenarios: offline classification and online training. We achieve the classification accuracy of 85.88% by converting a pre-trained ANN to a memristor-based SNN and 84.86% by training the memristor-based SNN directly, given that the baseline training accuracy of the equivalent ANN is 86.02%. We conclude that it is possible to achieve similar classification accuracy in simulation from ANNs to SNNs and from non-memristive synapses to data-driven memristive synapses. We also investigate how global parameters such as spike train length, the read noise, and the weight updating stop conditions affect the neural networks in both approaches.
A tool for emulating neuromorphic architectures with memristive models and devices
Jul 16, 2022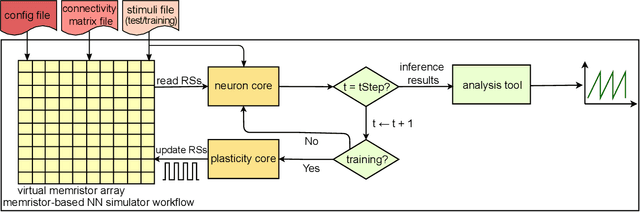
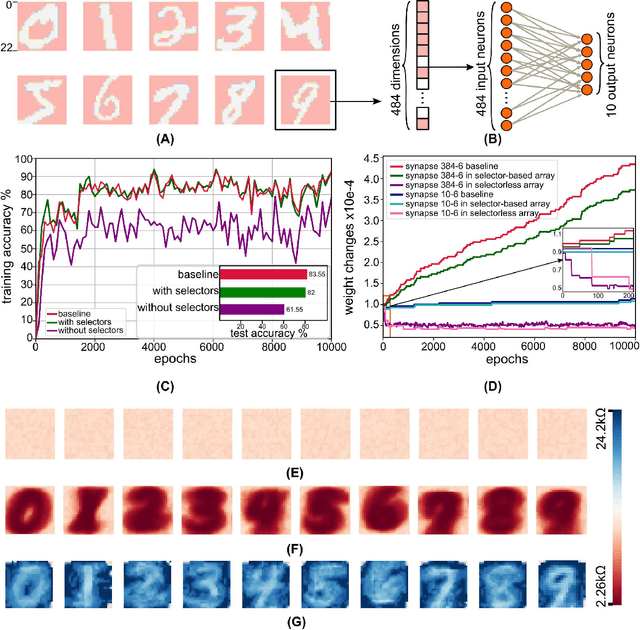
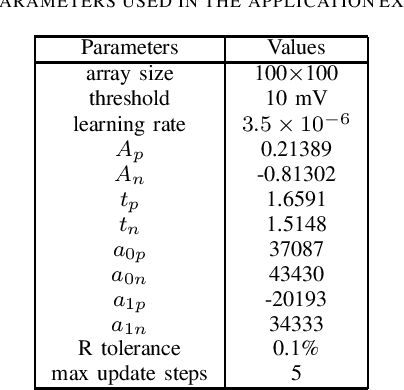
Memristors have shown promising features for enhancing neuromorphic computing concepts and AI hardware accelerators. In this paper, we present a user-friendly software infrastructure that allows emulating a wide range of neuromorphic architectures with memristor models. This tool empowers studies that exploit memristors for online learning and online classification tasks, predicting memristor resistive state changes during the training process. The versatility of the tool is showcased through the capability for users to customise parameters in the employed memristor and neuronal models as well as the employed learning rules. This further allows users to validate concepts and their sensitivity across a wide range of parameters. We demonstrate the use of the tool via an MNIST classification task. Finally, we show how this tool can also be used to emulate the concepts under study in-silico with practical memristive devices via appropriate interfacing with commercially available characterisation tools.
An FPGA-based System for Generalised Electron Devices Testing
Feb 01, 2022Electronic systems are becoming more and more ubiquitous as our world digitises. Simultaneously, even basic components are experiencing a wave of improvements with new transistors, memristors, voltage/current references, data converters, etc, being designed every year by hundreds of R&D groups world-wide. To date, the workhorse for testing all these designs has been a suite of lab instruments including oscilloscopes and signal generators, to mention the most popular. However, as components become more complex and pin numbers soar, the need for more parallel and versatile testing tools also becomes more pressing. In this work, we describe and benchmark an FPGA system developed that addresses this need. This general purpose testing system features a 64-channel source-meter unit (SMU), and 2x banks of 32 digital pins for digital I/O. We demonstrate that this bench-top system can obtain $170 pA$ current noise floor, $40 ns$ pulse delivery at $\pm13.5 V$ and $12 mA$ maximum current drive/channel. We then showcase the instrument's use in performing a selection of three characteristic measurement tasks: a) current-voltage (IV) characterisation of a diode and a transistor, b) fully parallel read-out of a memristor crossbar array and c) an integral non-linearity (INL) test on a DAC. This work introduces a down-scaled electronics laboratory packaged in a single instrument which provides a shift towards more affordable, reliable, compact and multi-functional instrumentation for emerging electronic technologies.