 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tsetlin Machine Accelerators for On-Chip Training at the Edge using FPGAs
Apr 28, 2025The increased demand for data privacy and security in machine learning (ML) applications has put impetus on effective edge training on Internet-of-Things (IoT) nodes. Edge training aims to leverage speed, energy efficiency and adaptability within the resource constraints of the nodes. Deploying and training Deep Neural Networks (DNNs)-based models at the edge, although accurate, posit significant challenges from the back-propagation algorithm's complexity, bit precision trade-offs, and heterogeneity of DNN layers. This paper presents a Dynamic Tsetlin Machine (DTM) training accelerator as an alternative to DNN implementations. DTM utilizes logic-based on-chip inference with finite-state automata-driven learning within the same Field Programmable Gate Array (FPGA) package. Underpinned on the Vanilla and Coalesced Tsetlin Machine algorithms, the dynamic aspect of the accelerator design allows for a run-time reconfiguration targeting different datasets, model architectures, and model sizes without resynthesis. This makes the DTM suitable for targeting multivariate sensor-based edge tasks. Compared to DNNs, DTM trains with fewer multiply-accumulates, devoid of derivative computation. It is a data-centric ML algorithm that learns by aligning Tsetlin automata with input data to form logical propositions enabling efficient Look-up-Table (LUT) mapping and frugal Block RAM usage in FPGA training implementations. The proposed accelerator offers 2.54x more Giga operations per second per Watt (GOP/s per W) and uses 6x less power than the next-best comparable design.
Runtime Tunable Tsetlin Machines for Edge Inference on eFPGAs
Feb 10, 2025Embedded Field-Programmable Gate Arrays (eFPGAs) allow for the design of hardware accelerators of edge Machine Learning (ML) applications at a lower power budget compared with traditional FPGA platforms. However, the limited eFPGA logic and memory significantly constrain compute capabilities and model size. As such, ML application deployment on eFPGAs is in direct contrast with the most recent FPGA approaches developing architecture-specific implementations and maximizing throughput over resource frugality. This paper focuses on the opposite side of this trade-off: the proposed eFPGA accelerator focuses on minimizing resource usage and allowing flexibility for on-field recalibration over throughput. This allows for runtime changes in model size, architecture, and input data dimensionality without offline resynthesis. This is made possible through the use of a bitwise compressed inference architecture of the Tsetlin Machine (TM) algorithm. TM compute does not require any multiplication operations, being limited to only bitwise AND, OR, NOT, summations and additions. Additionally, TM model compression allows the entire model to fit within the on-chip block RAM of the eFPGA. The paper uses this accelerator to propose a strategy for runtime model tuning in the field. The proposed approach uses 2.5x fewer Look-up-Tables (LUTs) and 3.38x fewer registers than the current most resource-fugal design and achieves up to 129x energy reduction compared with low-power microcontrollers running the same ML application.
An FPGA Architecture for Online Learning using the Tsetlin Machine
Jun 01, 2023


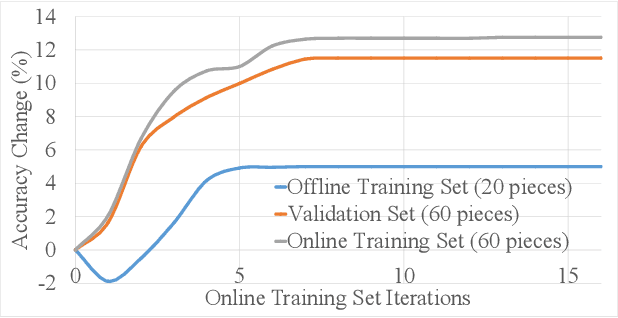
There is a need for machine learning models to evolve in unsupervised circumstances. New classifications may be introduced, unexpected faults may occur, or the initial dataset may be small compared to the data-points presented to the system during normal operation. Implementing such a system using neural networks involves significant mathematical complexity, which is a major issue in power-critical edge applications. This paper proposes a novel field-programmable gate-array infrastructure for online learning, implementing a low-complexity machine learning algorithm called the Tsetlin Machine. This infrastructure features a custom-designed architecture for run-time learning management, providing on-chip offline and online learning. Using this architecture, training can be carried out on-demand on the \ac{FPGA} with pre-classified data before inference takes place. Additionally, our architecture provisions online learning, where training can be interleaved with inference during operation. Tsetlin Machine (TM) training naturally descends to an optimum, with training also linked to a threshold hyper-parameter which is used to reduce the probability of issuing feedback as the TM becomes trained further. The proposed architecture is modular, allowing the data input source to be easily changed, whilst inbuilt cross-validation infrastructure allows for reliable and representative results during system testing. We present use cases for online learning using the proposed infrastructure and demonstrate the energy/performance/accuracy trade-offs.
IMBUE: In-Memory Boolean-to-CUrrent Inference ArchitecturE for Tsetlin Machines
May 22, 2023



In-memory computing for Machine Learning (ML) applications remedies the von Neumann bottlenecks by organizing computation to exploit parallelism and locality. Non-volatile memory devices such as Resistive RAM (ReRAM) offer integrated switching and storage capabilities showing promising performance for ML applications. However, ReRAM devices have design challenges, such as non-linear digital-analog conversion and circuit overheads. This paper proposes an In-Memory Boolean-to-Current Inference Architecture (IMBUE) that uses ReRAM-transistor cells to eliminate the need for such conversions. IMBUE processes Boolean feature inputs expressed as digital voltages and generates parallel current paths based on resistive memory states. The proportional column current is then translated back to the Boolean domain for further digital processing. The IMBUE architecture is inspired by the Tsetlin Machine (TM), an emerging ML algorithm based on intrinsically Boolean logic. The IMBUE architecture demonstrates significant performance improvements over binarized convolutional neural networks and digital TM in-memory implementations, achieving up to a 12.99x and 5.28x increase, respectively.
Energy-frugal and Interpretable AI Hardware Design using Learning Automata
May 19, 2023



Energy efficiency is a crucial requirement for enabling powerful artificial intelligence applications at the microedge. Hardware acceleration with frugal architectural allocation is an effective method for reducing energy. Many emerging applications also require the systems design to incorporate interpretable decision models to establish responsibility and transparency. The design needs to provision for additional resources to provide reachable states in real-world data scenarios, defining conflicting design tradeoffs between energy efficiency. is challenging. Recently a new machine learning algorithm, called the Tsetlin machine, has been proposed. The algorithm is fundamentally based on the principles of finite-state automata and benefits from natural logic underpinning rather than arithmetic. In this paper, we investigate methods of energy-frugal artificial intelligence hardware design by suitably tuning the hyperparameters, while maintaining high learning efficacy. To demonstrate interpretability, we use reachability and game-theoretic analysis in two simulation environments: a SystemC model to study the bounded state transitions in the presence of hardware faults and Nash equilibrium between states to analyze the learning convergence. Our analyses provides the first insights into conflicting design tradeoffs involved in energy-efficient and interpretable decision models for this new artificial intelligence hardware architecture. We show that frugal resource allocation coupled with systematic prodigality between randomized reinforcements can provide decisive energy reduction while also achieving robust and interpretable learning.
Low-Power Audio Keyword Spotting using Tsetlin Machines
Jan 27, 2021The emergence of Artificial Intelligence (AI) driven Keyword Spotting (KWS) technologies has revolutionized human to machine interaction. Yet, the challenge of end-to-end energy efficiency, memory footprint and system complexity of current Neural Network (NN) powered AI-KWS pipelines has remained ever present. This paper evaluates KWS utilizing a learning automata powered machine learning algorithm called the Tsetlin Machine (TM). Through significant reduction in parameter requirements and choosing logic over arithmetic based processing, the TM offers new opportunities for low-power KWS while maintaining high learning efficacy. In this paper we explore a TM based keyword spotting (KWS) pipeline to demonstrate low complexity with faster rate of convergence compared to NNs. Further, we investigate the scalability with increasing keywords and explore the potential for enabling low-power on-chip KWS.
* 20 pp