 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based indoor localization of nano drones in controlled environment with its applications
Dec 11, 2024



Navigating unmanned aerial vehicles in environments where GPS signals are unavailable poses a compelling and intricate challenge. This challenge is further heightened when dealing with Nano Aerial Vehicles (NAVs) due to their compact size, payload restrictions, and computational capabilities. This paper proposes an approach for localization using off-board computing, an off-board monocular camera, and modified open-source algorithms. The proposed method uses three parallel proportional-integral-derivative controllers on the off-board computer to provide velocity corrections via wireless communication, stabilizing the NAV in a custom-controlled environment. Featuring a 3.1cm localization error and a modest setup cost of 50 USD, this approach proves optimal for environments where cost considerations are paramount. It is especially well-suited for applications like teaching drone control in academic institutions, where the specified error margin is deemed acceptable. Various applications are designed to validate the proposed technique, such as landing the NAV on a moving ground vehicle, path planning in a 3D space, and localizing multi-NAVs. The created package is openly available at https://github.com/simmubhangu/eyantra_drone to foster research in this field.
IMBUE: In-Memory Boolean-to-CUrrent Inference ArchitecturE for Tsetlin Machines
May 22, 2023



In-memory computing for Machine Learning (ML) applications remedies the von Neumann bottlenecks by organizing computation to exploit parallelism and locality. Non-volatile memory devices such as Resistive RAM (ReRAM) offer integrated switching and storage capabilities showing promising performance for ML applications. However, ReRAM devices have design challenges, such as non-linear digital-analog conversion and circuit overheads. This paper proposes an In-Memory Boolean-to-Current Inference Architecture (IMBUE) that uses ReRAM-transistor cells to eliminate the need for such conversions. IMBUE processes Boolean feature inputs expressed as digital voltages and generates parallel current paths based on resistive memory states. The proportional column current is then translated back to the Boolean domain for further digital processing. The IMBUE architecture is inspired by the Tsetlin Machine (TM), an emerging ML algorithm based on intrinsically Boolean logic. The IMBUE architecture demonstrates significant performance improvements over binarized convolutional neural networks and digital TM in-memory implementations, achieving up to a 12.99x and 5.28x increase, respectively.
Using GANs to Synthesise Minimum Training Data for Deepfake Generation
Nov 10, 2020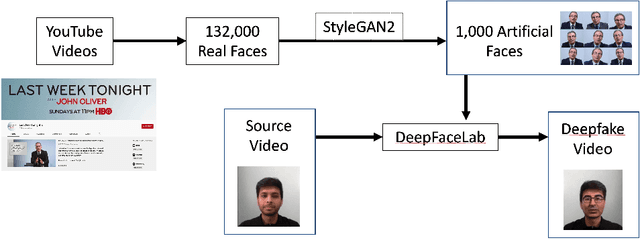
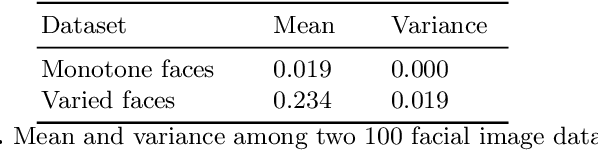
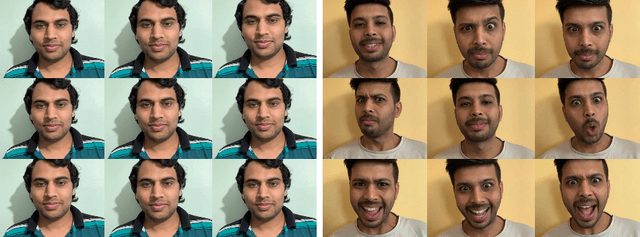
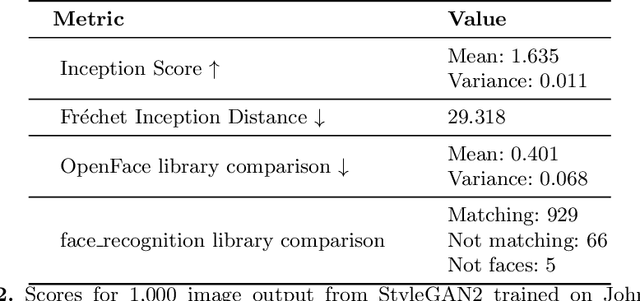
There are many applications of Generative Adversarial Networks (GANs) in fields like computer vision, natural language processing, speech synthesis, and more. Undoubtedly the most notable results have been in the area of image synthesis and in particular in the generation of deepfake videos. While deepfakes have received much negative media coverage, they can be a useful technology in applications like entertainment, customer relations, or even assistive care. One problem with generating deepfakes is the requirement for a lot of image training data of the subject which is not an issue if the subject is a celebrity for whom many images already exist. If there are only a small number of training images then the quality of the deepfake will be poor. Some media reports have indicated that a good deepfake can be produced with as few as 500 images but in practice, quality deepfakes require many thousands of images, one of the reasons why deepfakes of celebrities and politicians have become so popular. In this study, we exploit the property of a GAN to produce images of an individual with variable facial expressions which we then use to generate a deepfake. We observe that with such variability in facial expressions of synthetic GAN-generated training images and a reduced quantity of them, we can produce a near-realistic deepfake videos.