 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing GANs to Synthesise Minimum Training Data for Deepfake Generation
Paper and Code
Nov 10, 2020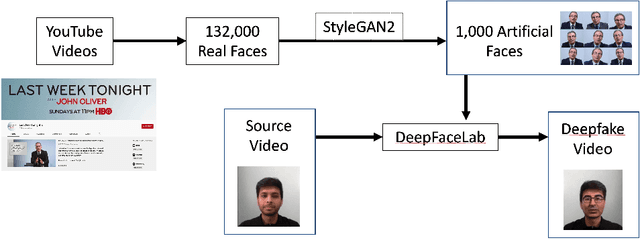
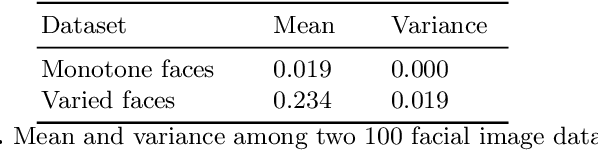
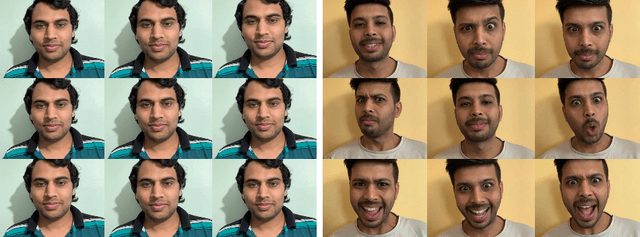
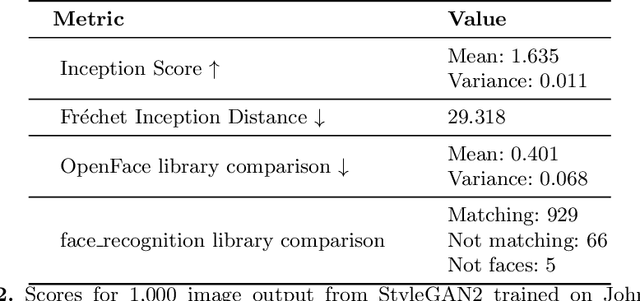
There are many applications of Generative Adversarial Networks (GANs) in fields like computer vision, natural language processing, speech synthesis, and more. Undoubtedly the most notable results have been in the area of image synthesis and in particular in the generation of deepfake videos. While deepfakes have received much negative media coverage, they can be a useful technology in applications like entertainment, customer relations, or even assistive care. One problem with generating deepfakes is the requirement for a lot of image training data of the subject which is not an issue if the subject is a celebrity for whom many images already exist. If there are only a small number of training images then the quality of the deepfake will be poor. Some media reports have indicated that a good deepfake can be produced with as few as 500 images but in practice, quality deepfakes require many thousands of images, one of the reasons why deepfakes of celebrities and politicians have become so popular. In this study, we exploit the property of a GAN to produce images of an individual with variable facial expressions which we then use to generate a deepfake. We observe that with such variability in facial expressions of synthetic GAN-generated training images and a reduced quantity of them, we can produce a near-realistic deepfake videos.