 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause
Paper and Code
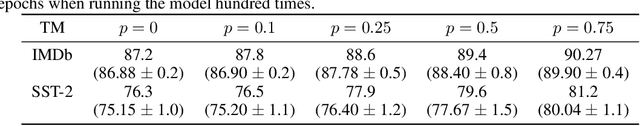


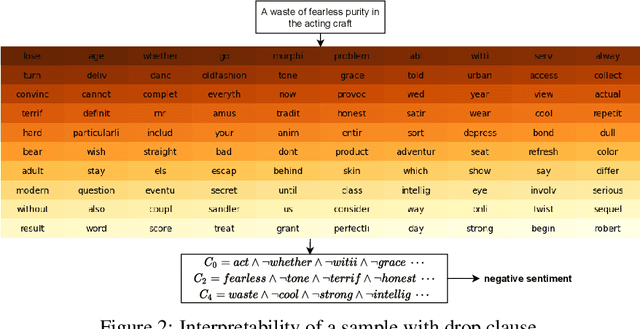
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. Along with producing more distinct and well-structured patterns that improve the performance, we also show that dropping clauses increases learning robustness. To explore the effects clause dropping has on accuracy, training time, and interpretability, we conduct extensive experiments on various benchmark datasets in natural language processing (NLP) (IMDb and SST2) as well as computer vision (MNIST and CIFAR10). In brief, we observe from +2% to +4% increase in accuracy and 2x to 4x faster learning. We further employ the Convolutional TM to document interpretable results on the CIFAR10 dataset. To the best of our knowledge, this is the first time an interpretable machine learning algorithm has been used to produce pixel-level human-interpretable results on CIFAR10. Also, unlike previous interpretable methods that focus on attention visualisation or gradient interpretability, we show that the TM is a more general interpretable method. That is, by producing rule-based propositional logic expressions that are \emph{human}-interpretable, the TM can explain how it classifies a particular instance at the pixel level for computer vision and at the word level for NLP.