 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment Sound Classification using Multiple Feature Channels and Deep Convolutional Neural Networks
Paper and Code
Sep 25, 2019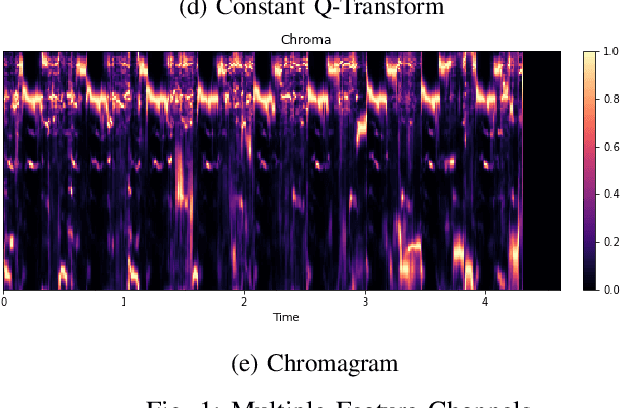
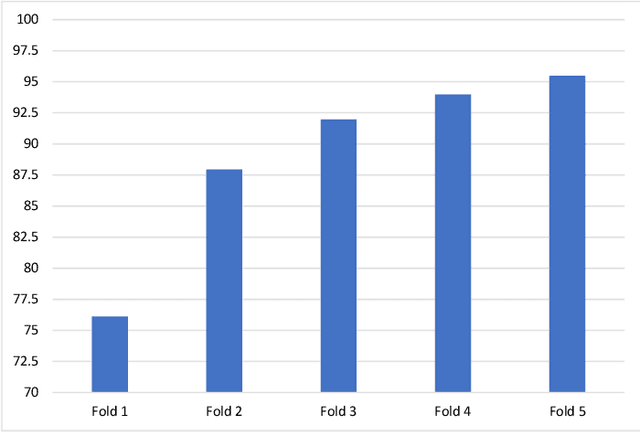
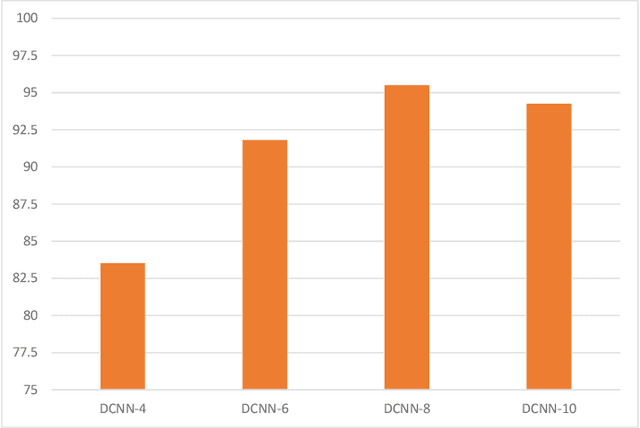
In this paper, we propose a model for the Environment Sound Classification Task (ESC) that consists of multiple feature channels given as input to a Deep Convolutional Neural Network (CNN). The novelty of the paper lies in using multiple feature channels consisting of Mel-Frequency Cepstral Coefficients (MFCC), Gammatone Frequency Cepstral Coefficients (GFCC), the Constant Q-transform (CQT) and Chromagram. Such multiple features have never been used before for signal or audio processing. Also, we employ a deeper CNN (DCNN) compared to previous models, consisting of 2D separable convolutions working on time and feature domain separately. The model also consists of max pooling layers that downsample time and feature domain separately. We use some data augmentation techniques to further boost performance. Our model is able to achieve state-of-the-art performance on all three benchmark environment sound classification datasets, i.e. the UrbanSound8K (97.35%), ESC-10 (95.75%) and ESC-50 (90.48%). To the best of our knowledge, this is the first time that a single environment sound classification model is able to achieve state-of-the-art results on all three datasets. For ESC-10 and ESC-50 datasets, the accuracy achieved by the proposed model is beyond human accuracy of 95.7% and 81.3% respectively.