 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripCraft: A Benchmark for Spatio-Temporally Fine Grained Travel Planning
Feb 27, 2025



Recent advancements in probing Large Language Models (LLMs) have explored their latent potential as personalized travel planning agents, yet existing benchmarks remain limited in real world applicability. Existing datasets, such as TravelPlanner and TravelPlanner+, suffer from semi synthetic data reliance, spatial inconsistencies, and a lack of key travel constraints, making them inadequate for practical itinerary generation. To address these gaps, we introduce TripCraft, a spatiotemporally coherent travel planning dataset that integrates real world constraints, including public transit schedules, event availability, diverse attraction categories, and user personas for enhanced personalization. To evaluate LLM generated plans beyond existing binary validation methods, we propose five continuous evaluation metrics, namely Temporal Meal Score, Temporal Attraction Score, Spatial Score, Ordering Score, and Persona Score which assess itinerary quality across multiple dimensions. Our parameter informed setting significantly enhances meal scheduling, improving the Temporal Meal Score from 61% to 80% in a 7 day scenario. TripCraft establishes a new benchmark for LLM driven personalized travel planning, offering a more realistic, constraint aware framework for itinerary generation. Dataset and Codebase will be made publicly available upon acceptance.
Simba: Mamba augmented U-ShiftGCN for Skeletal Action Recognition in Videos
Apr 11, 2024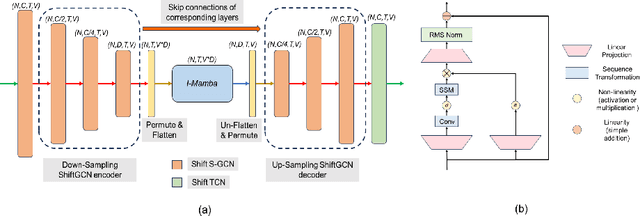
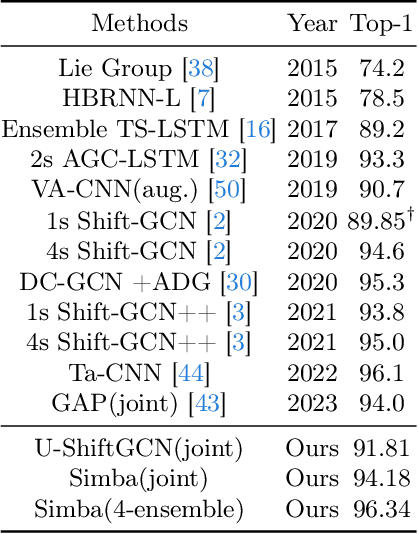
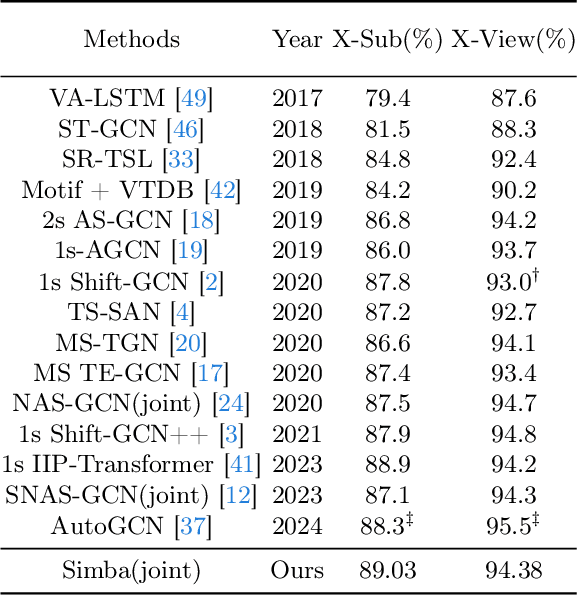
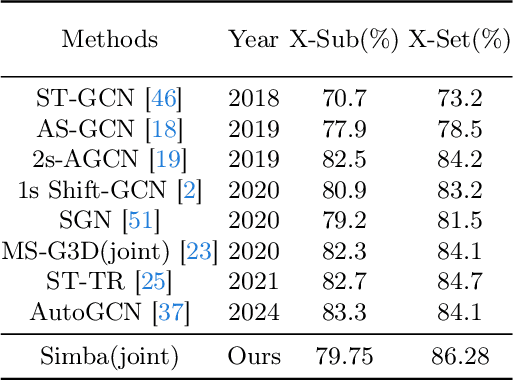
Skeleton Action Recognition (SAR) involves identifying human actions using skeletal joint coordinates and their interconnections. While plain Transformers have been attempted for this task, they still fall short compared to the current leading methods, which are rooted in Graph Convolutional Networks (GCNs) due to the absence of structural priors. Recently, a novel selective state space model, Mamba, has surfaced as a compelling alternative to the attention mechanism in Transformers, offering efficient modeling of long sequences. In this work, to the utmost extent of our awareness, we present the first SAR framework incorporating Mamba. Each fundamental block of our model adopts a novel U-ShiftGCN architecture with Mamba as its core component. The encoder segment of the U-ShiftGCN is devised to extract spatial features from the skeletal data using downsampling vanilla Shift S-GCN blocks. These spatial features then undergo intermediate temporal modeling facilitated by the Mamba block before progressing to the encoder section, which comprises vanilla upsampling Shift S-GCN blocks. Additionally, a Shift T-GCN (ShiftTCN) temporal modeling unit is employed before the exit of each fundamental block to refine temporal representations. This particular integration of downsampling spatial, intermediate temporal, upsampling spatial, and ultimate temporal subunits yields promising results for skeleton action recognition. We dub the resulting model \textbf{Simba}, which attains state-of-the-art performance across three well-known benchmark skeleton action recognition datasets: NTU RGB+D, NTU RGB+D 120, and Northwestern-UCLA. Interestingly, U-ShiftGCN (Simba without Intermediate Mamba Block) by itself is capable of performing reasonably well and surpasses our baseline.
ViLP: Knowledge Exploration using Vision, Language, and Pose Embeddings for Video Action Recognition
Aug 07, 2023Video Action Recognition (VAR) is a challenging task due to its inherent complexities. Though different approaches have been explored in the literature, designing a unified framework to recognize a large number of human actions is still a challenging problem. Recently, Multi-Modal Learning (MML) has demonstrated promising results in this domain. In literature, 2D skeleton or pose modality has often been used for this task, either independently or in conjunction with the visual information (RGB modality) present in videos. However, the combination of pose, visual information, and text attributes has not been explored yet, though text and pose attributes independently have been proven to be effective in numerous computer vision tasks. In this paper, we present the first pose augmented Vision-language model (VLM) for VAR. Notably, our scheme achieves an accuracy of 92.81% and 73.02% on two popular human video action recognition benchmark datasets, UCF-101 and HMDB-51, respectively, even without any video data pre-training, and an accuracy of 96.11% and 75.75% after kinetics pre-training.