 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimba: Mamba augmented U-ShiftGCN for Skeletal Action Recognition in Videos
Paper and Code
Apr 11, 2024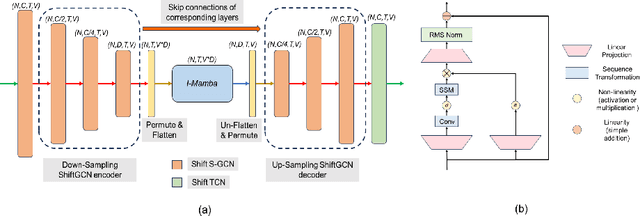
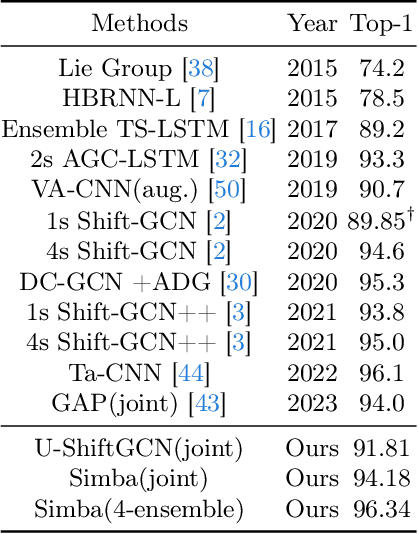
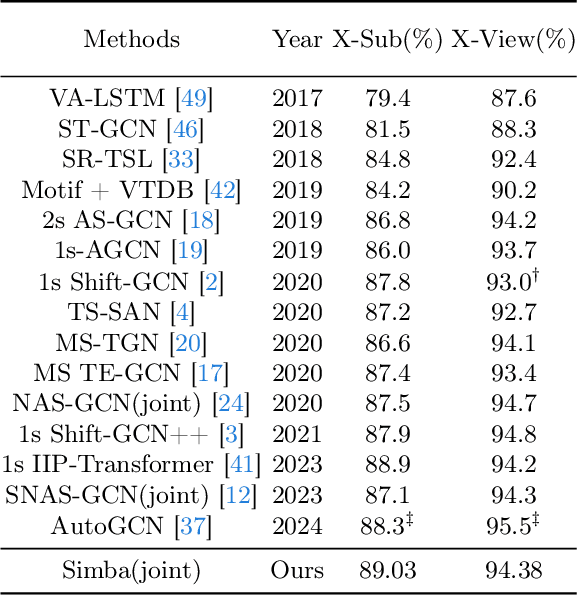
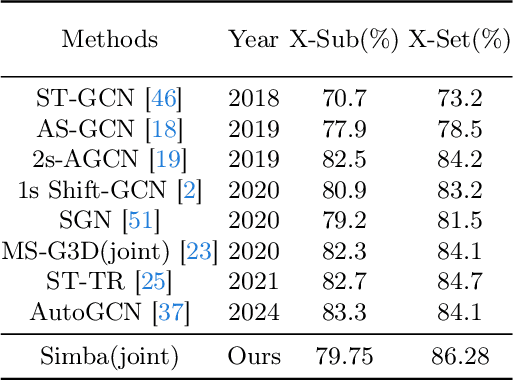
Skeleton Action Recognition (SAR) involves identifying human actions using skeletal joint coordinates and their interconnections. While plain Transformers have been attempted for this task, they still fall short compared to the current leading methods, which are rooted in Graph Convolutional Networks (GCNs) due to the absence of structural priors. Recently, a novel selective state space model, Mamba, has surfaced as a compelling alternative to the attention mechanism in Transformers, offering efficient modeling of long sequences. In this work, to the utmost extent of our awareness, we present the first SAR framework incorporating Mamba. Each fundamental block of our model adopts a novel U-ShiftGCN architecture with Mamba as its core component. The encoder segment of the U-ShiftGCN is devised to extract spatial features from the skeletal data using downsampling vanilla Shift S-GCN blocks. These spatial features then undergo intermediate temporal modeling facilitated by the Mamba block before progressing to the encoder section, which comprises vanilla upsampling Shift S-GCN blocks. Additionally, a Shift T-GCN (ShiftTCN) temporal modeling unit is employed before the exit of each fundamental block to refine temporal representations. This particular integration of downsampling spatial, intermediate temporal, upsampling spatial, and ultimate temporal subunits yields promising results for skeleton action recognition. We dub the resulting model \textbf{Simba}, which attains state-of-the-art performance across three well-known benchmark skeleton action recognition datasets: NTU RGB+D, NTU RGB+D 120, and Northwestern-UCLA. Interestingly, U-ShiftGCN (Simba without Intermediate Mamba Block) by itself is capable of performing reasonably well and surpasses our baseline.