 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Paper and Code



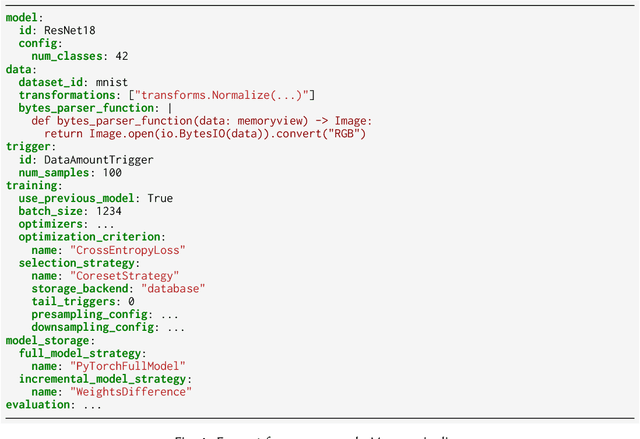
Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.