 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Fair Division with Additional Information
May 30, 2025We study the problem of fairly allocating indivisible goods to agents in an online setting, where goods arrive sequentially and must be allocated irrevocably to agents. Focusing on the popular fairness notions of envy-freeness, proportionality, and maximin share fairness (and their approximate variants), we ask how the availability of information on future goods influences the existence and approximability of fair allocations. In the absence of any such information, we establish strong impossibility results, demonstrating the inherent difficulty of achieving even approximate fairness guarantees. In contrast, we demonstrate that knowledge of additional information -- such as aggregate of each agent's total valuations (equivalently, normalized valuations) or the multiset of future goods values (frequency predictions) -- would enable the design of fairer online algorithms. Given normalization information, we propose an algorithm that achieves stronger fairness guarantees than previously known results. Given frequency predictions, we introduce a meta-algorithm that leverages frequency predictions to match the best-known offline guarantees for a broad class of ''share-based'' fairness notions. Our complementary impossibility results in each setting underscore both the limitations imposed by uncertainty about future goods and the potential of leveraging structured information to achieve fairer outcomes in online fair division.
Verifying Proportionality in Temporal Voting
Feb 09, 2025We study a model of temporal voting where there is a fixed time horizon, and at each round the voters report their preferences over the available candidates and a single candidate is selected. Prior work has adapted popular notions of justified representation as well as voting rules that provide strong representation guarantees from the multiwinner election setting to this model. In our work, we focus on the complexity of verifying whether a given outcome offers proportional representation. We show that in the temporal setting verification is strictly harder than in multiwinner voting, but identify natural special cases that enable efficient algorithms.
A Survey on Emergent Language
Sep 04, 2024



The field of emergent language represents a novel area of research within the domain of artificial intelligence, particularly within the context of multi-agent reinforcement learning. Although the concept of studying language emergence is not new, early approaches were primarily concerned with explaining human language formation, with little consideration given to its potential utility for artificial agents. In contrast, studies based on reinforcement learning aim to develop communicative capabilities in agents that are comparable to or even superior to human language. Thus, they extend beyond the learned statistical representations that are common in natural language processing research. This gives rise to a number of fundamental questions, from the prerequisites for language emergence to the criteria for measuring its success. This paper addresses these questions by providing a comprehensive review of 181 scientific publications on emergent language in artificial intelligence. Its objective is to serve as a reference for researchers interested in or proficient in the field. Consequently, the main contributions are the definition and overview of the prevailing terminology, the analysis of existing evaluation methods and metrics, and the description of the identified research gaps.
Decision Transformer for Enhancing Neural Local Search on the Job Shop Scheduling Problem
Sep 04, 2024



The job shop scheduling problem (JSSP) and its solution algorithms have been of enduring interest in both academia and industry for decades. In recent years, machine learning (ML) is playing an increasingly important role in advancing existing and building new heuristic solutions for the JSSP, aiming to find better solutions in shorter computation times. In this paper we build on top of a state-of-the-art deep reinforcement learning (DRL) agent, called Neural Local Search (NLS), which can efficiently and effectively control a large local neighborhood search on the JSSP. In particular, we develop a method for training the decision transformer (DT) algorithm on search trajectories taken by a trained NLS agent to further improve upon the learned decision-making sequences. Our experiments show that the DT successfully learns local search strategies that are different and, in many cases, more effective than those of the NLS agent itself. In terms of the tradeoff between solution quality and acceptable computational time needed for the search, the DT is particularly superior in application scenarios where longer computational times are acceptable. In this case, it makes up for the longer inference times required per search step, which are caused by the larger neural network architecture, through better quality decisions per step. Thereby, the DT achieves state-of-the-art results for solving the JSSP with ML-enhanced search.
Beyond Training: Optimizing Reinforcement Learning Based Job Shop Scheduling Through Adaptive Action Sampling
Jun 11, 2024



Learned construction heuristics for scheduling problems have become increasingly competitive with established solvers and heuristics in recent years. In particular, significant improvements have been observed in solution approaches using deep reinforcement learning (DRL). While much attention has been paid to the design of network architectures and training algorithms to achieve state-of-the-art results, little research has investigated the optimal use of trained DRL agents during inference. Our work is based on the hypothesis that, similar to search algorithms, the utilization of trained DRL agents should be dependent on the acceptable computational budget. We propose a simple yet effective parameterization, called $\delta$-sampling that manipulates the trained action vector to bias agent behavior towards exploration or exploitation during solution construction. By following this approach, we can achieve a more comprehensive coverage of the search space while still generating an acceptable number of solutions. In addition, we propose an algorithm for obtaining the optimal parameterization for such a given number of solutions and any given trained agent. Experiments extending existing training protocols for job shop scheduling problems with our inference method validate our hypothesis and result in the expected improvements of the generated solutions.
Proportional Fairness in Clustering: A Social Choice Perspective
Oct 27, 2023



We study the proportional clustering problem of Chen et al. [ICML'19] and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters [EC'23] simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al. [ICML'19], but also to individual fairness [Jung et al., FORC'20] and the "core" [Li et al. ICML'21]. In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters [EC'23] imply approximations to these stronger guarantees.
schlably: A Python Framework for Deep Reinforcement Learning Based Scheduling Experiments
Jan 10, 2023Research on deep reinforcement learning (DRL) based production scheduling (PS) has gained a lot of attention in recent years, primarily due to the high demand for optimizing scheduling problems in diverse industry settings. Numerous studies are carried out and published as stand-alone experiments that often vary only slightly with respect to problem setups and solution approaches. The programmatic core of these experiments is typically very similar. Despite this fact, no standardized and resilient framework for experimentation on PS problems with DRL algorithms could be established so far. In this paper, we introduce schlably, a Python-based framework that provides researchers a comprehensive toolset to facilitate the development of PS solution strategies based on DRL. schlably eliminates the redundant overhead work that the creation of a sturdy and flexible backbone requires and increases the comparability and reusability of conducted research work.
Maps for Learning Indexable Classes
Oct 15, 2020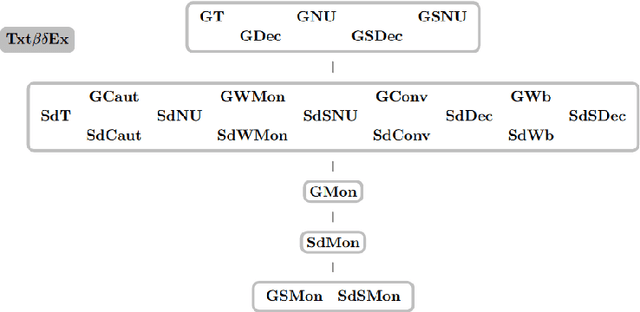
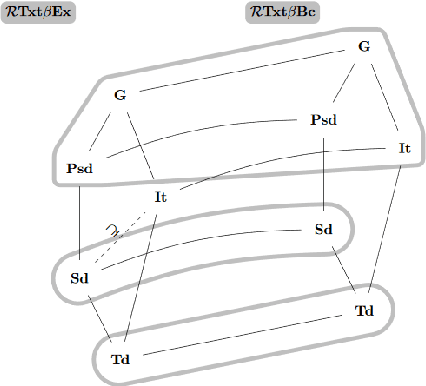
We study learning of indexed families from positive data where a learner can freely choose a hypothesis space (with uniformly decidable membership) comprising at least the languages to be learned. This abstracts a very universal learning task which can be found in many areas, for example learning of (subsets of) regular languages or learning of natural languages. We are interested in various restrictions on learning, such as consistency, conservativeness or set-drivenness, exemplifying various natural learning restrictions. Building on previous results from the literature, we provide several maps (depictions of all pairwise relations) of various groups of learning criteria, including a map for monotonicity restrictions and similar criteria and a map for restrictions on data presentation. Furthermore, we consider, for various learning criteria, whether learners can be assumed consistent.