 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Emergent Language
Sep 04, 2024



The field of emergent language represents a novel area of research within the domain of artificial intelligence, particularly within the context of multi-agent reinforcement learning. Although the concept of studying language emergence is not new, early approaches were primarily concerned with explaining human language formation, with little consideration given to its potential utility for artificial agents. In contrast, studies based on reinforcement learning aim to develop communicative capabilities in agents that are comparable to or even superior to human language. Thus, they extend beyond the learned statistical representations that are common in natural language processing research. This gives rise to a number of fundamental questions, from the prerequisites for language emergence to the criteria for measuring its success. This paper addresses these questions by providing a comprehensive review of 181 scientific publications on emergent language in artificial intelligence. Its objective is to serve as a reference for researchers interested in or proficient in the field. Consequently, the main contributions are the definition and overview of the prevailing terminology, the analysis of existing evaluation methods and metrics, and the description of the identified research gaps.
Decision Transformer for Enhancing Neural Local Search on the Job Shop Scheduling Problem
Sep 04, 2024



The job shop scheduling problem (JSSP) and its solution algorithms have been of enduring interest in both academia and industry for decades. In recent years, machine learning (ML) is playing an increasingly important role in advancing existing and building new heuristic solutions for the JSSP, aiming to find better solutions in shorter computation times. In this paper we build on top of a state-of-the-art deep reinforcement learning (DRL) agent, called Neural Local Search (NLS), which can efficiently and effectively control a large local neighborhood search on the JSSP. In particular, we develop a method for training the decision transformer (DT) algorithm on search trajectories taken by a trained NLS agent to further improve upon the learned decision-making sequences. Our experiments show that the DT successfully learns local search strategies that are different and, in many cases, more effective than those of the NLS agent itself. In terms of the tradeoff between solution quality and acceptable computational time needed for the search, the DT is particularly superior in application scenarios where longer computational times are acceptable. In this case, it makes up for the longer inference times required per search step, which are caused by the larger neural network architecture, through better quality decisions per step. Thereby, the DT achieves state-of-the-art results for solving the JSSP with ML-enhanced search.
Beyond Training: Optimizing Reinforcement Learning Based Job Shop Scheduling Through Adaptive Action Sampling
Jun 11, 2024



Learned construction heuristics for scheduling problems have become increasingly competitive with established solvers and heuristics in recent years. In particular, significant improvements have been observed in solution approaches using deep reinforcement learning (DRL). While much attention has been paid to the design of network architectures and training algorithms to achieve state-of-the-art results, little research has investigated the optimal use of trained DRL agents during inference. Our work is based on the hypothesis that, similar to search algorithms, the utilization of trained DRL agents should be dependent on the acceptable computational budget. We propose a simple yet effective parameterization, called $\delta$-sampling that manipulates the trained action vector to bias agent behavior towards exploration or exploitation during solution construction. By following this approach, we can achieve a more comprehensive coverage of the search space while still generating an acceptable number of solutions. In addition, we propose an algorithm for obtaining the optimal parameterization for such a given number of solutions and any given trained agent. Experiments extending existing training protocols for job shop scheduling problems with our inference method validate our hypothesis and result in the expected improvements of the generated solutions.
Curriculum Learning in Job Shop Scheduling using Reinforcement Learning
May 17, 2023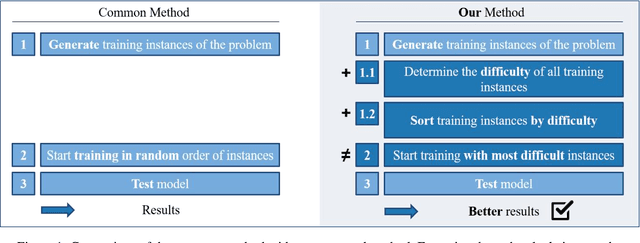
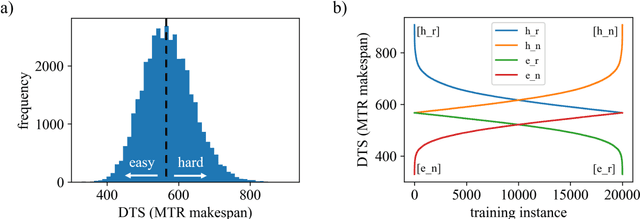
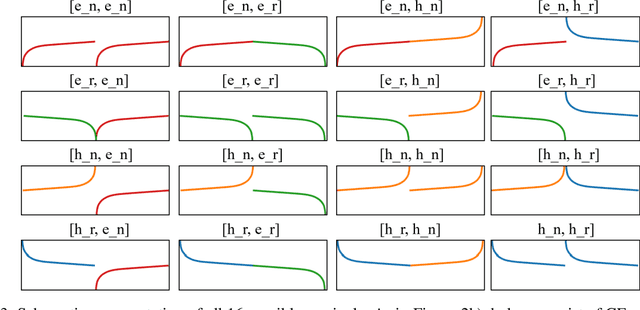
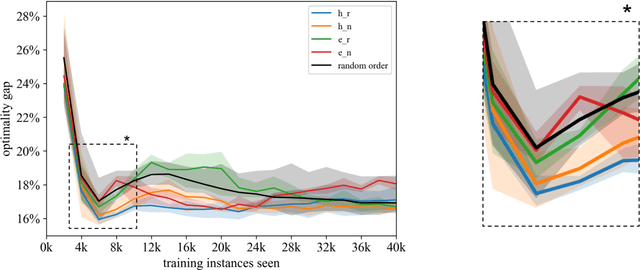
Solving job shop scheduling problems (JSSPs) with a fixed strategy, such as a priority dispatching rule, may yield satisfactory results for several problem instances but, nevertheless, insufficient results for others. From this single-strategy perspective finding a near optimal solution to a specific JSSP varies in difficulty even if the machine setup remains the same. A recent intensively researched and promising method to deal with difficulty variability is Deep Reinforcement Learning (DRL), which dynamically adjusts an agent's planning strategy in response to difficult instances not only during training, but also when applied to new situations. In this paper, we further improve DLR as an underlying method by actively incorporating the variability of difficulty within the same problem size into the design of the learning process. We base our approach on a state-of-the-art methodology that solves JSSP by means of DRL and graph neural network embeddings. Our work supplements the training routine of the agent by a curriculum learning strategy that ranks the problem instances shown during training by a new metric of problem instance difficulty. Our results show that certain curricula lead to significantly better performances of the DRL solutions. Agents trained on these curricula beat the top performance of those trained on randomly distributed training data, reaching 3.2% shorter average makespans.
schlably: A Python Framework for Deep Reinforcement Learning Based Scheduling Experiments
Jan 10, 2023Research on deep reinforcement learning (DRL) based production scheduling (PS) has gained a lot of attention in recent years, primarily due to the high demand for optimizing scheduling problems in diverse industry settings. Numerous studies are carried out and published as stand-alone experiments that often vary only slightly with respect to problem setups and solution approaches. The programmatic core of these experiments is typically very similar. Despite this fact, no standardized and resilient framework for experimentation on PS problems with DRL algorithms could be established so far. In this paper, we introduce schlably, a Python-based framework that provides researchers a comprehensive toolset to facilitate the development of PS solution strategies based on DRL. schlably eliminates the redundant overhead work that the creation of a sturdy and flexible backbone requires and increases the comparability and reusability of conducted research work.
Under the Hood of Neural Networks: Characterizing Learned Representations by Functional Neuron Populations and Network Ablations
Apr 02, 2020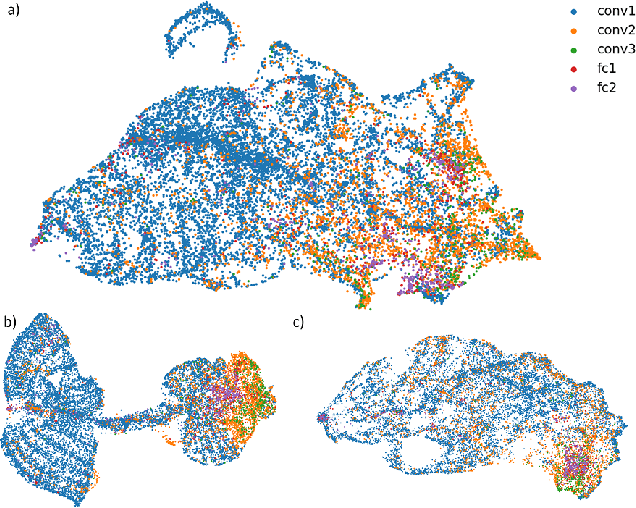
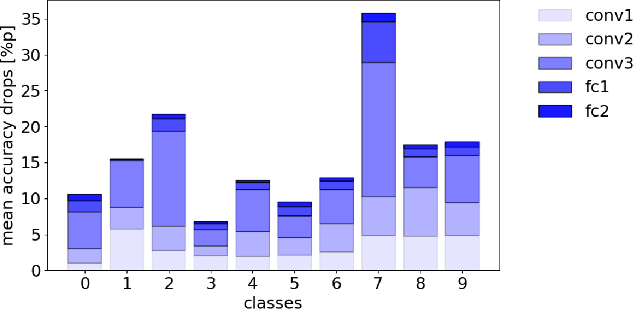
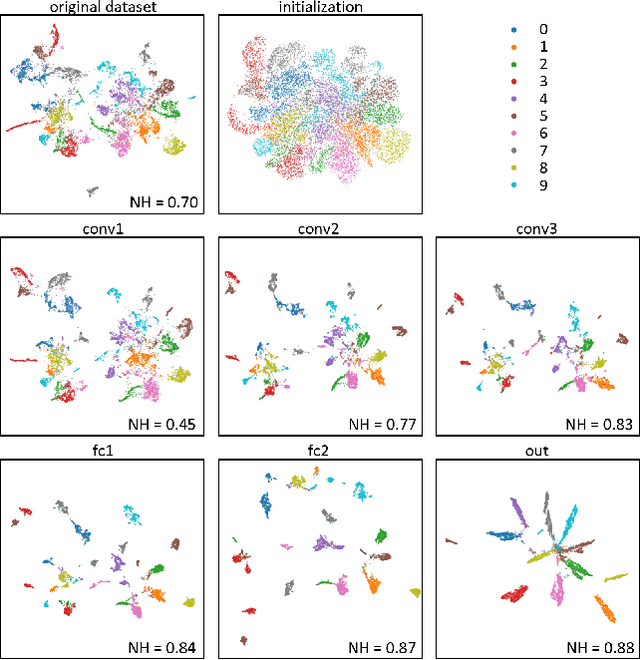
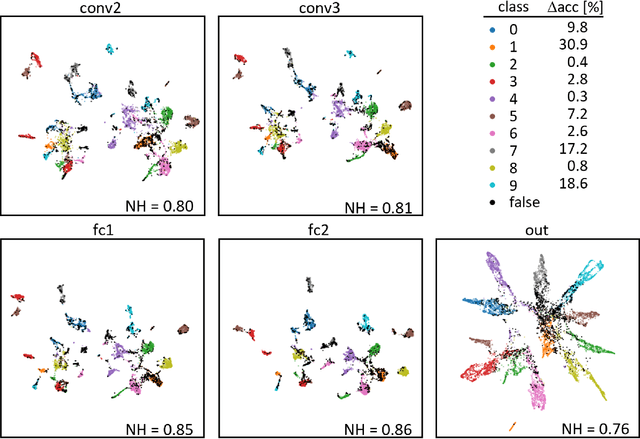
The need for more transparency of the decision-making processes in artificial neural networks steadily increases driven by their applications in safety critical and ethically challenging domains such as autonomous driving or medical diagnostics. We address today's lack of transparency of neural networks and shed light on the roles of single neurons and groups of neurons within the network fulfilling a learned task. Inspired by research in the field of neuroscience, we characterize the learned representations by activation patterns and network ablations, revealing functional neuron populations that a) act jointly in response to specific stimuli or b) have similar impact on the network's performance after being ablated. We find that neither a neuron's magnitude or selectivity of activation, nor its impact on network performance are sufficient stand-alone indicators for its importance for the overall task. We argue that such indicators are essential for future advances in transfer learning and modern neuroscience.
Ablation Studies in Artificial Neural Networks
Jan 24, 2019
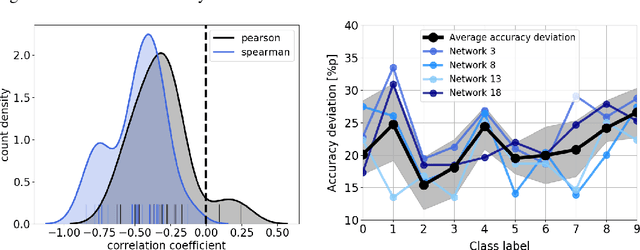
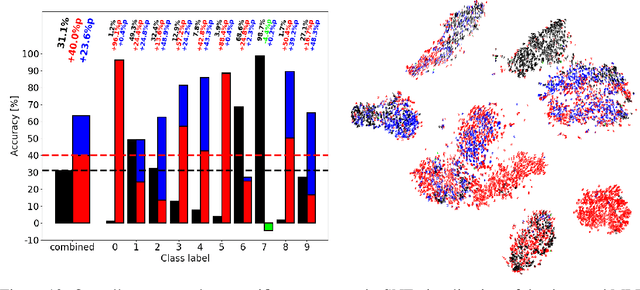
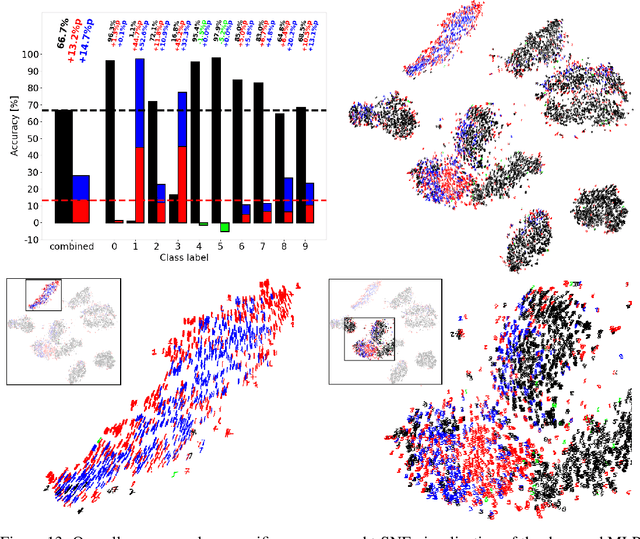
Ablation studies have been widely used in the field of neuroscience to tackle complex biological systems such as the extensively studied Drosophila central nervous system, the vertebrate brain and more interestingly and most delicately, the human brain. In the past, these kinds of studies were utilized to uncover structure and organization in the brain, i.e. a mapping of features inherent to external stimuli onto different areas of the neocortex. considering the growth in size and complexity of state-of-the-art artificial neural networks (ANNs) and the corresponding growth in complexity of the tasks that are tackled by these networks, the question arises whether ablation studies may be used to investigate these networks for a similar organization of their inner representations. In this paper, we address this question and performed two ablation studies in two fundamentally different ANNs to investigate their inner representations of two well-known benchmark datasets from the computer vision domain. We found that features distinct to the local and global structure of the data are selectively represented in specific parts of the network. Furthermore, some of these representations are redundant, awarding the network a certain robustness to structural damages. We further determined the importance of specific parts of the network for the classification task solely based on the weight structure of single units. Finally, we examined the ability of damaged networks to recover from the consequences of ablations by means of recovery training. We argue that ablations studies are a feasible method to investigate knowledge representations in ANNs and are especially helpful to examine a networks robustness to structural damages, a feature of ANNs that will become increasingly important for future safety-critical applications.