 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Single Camera BEV Perception Using Multi-Camera Training
Sep 04, 2024



Bird's Eye View (BEV) map prediction is essential for downstream autonomous driving tasks like trajectory prediction. In the past, this was accomplished through the use of a sophisticated sensor configuration that captured a surround view from multiple cameras. However, in large-scale production, cost efficiency is an optimization goal, so that using fewer cameras becomes more relevant. But the consequence of fewer input images correlates with a performance drop. This raises the problem of developing a BEV perception model that provides a sufficient performance on a low-cost sensor setup. Although, primarily relevant for inference time on production cars, this cost restriction is less problematic on a test vehicle during training. Therefore, the objective of our approach is to reduce the aforementioned performance drop as much as possible using a modern multi-camera surround view model reduced for single-camera inference. The approach includes three features, a modern masking technique, a cyclic Learning Rate (LR) schedule, and a feature reconstruction loss for supervising the transition from six-camera inputs to one-camera input during training. Our method outperforms versions trained strictly with one camera or strictly with six-camera surround view for single-camera inference resulting in reduced hallucination and better quality of the BEV map.
How Do You Act? An Empirical Study to Understand Behavior of Deep Reinforcement Learning Agents
Apr 07, 2020
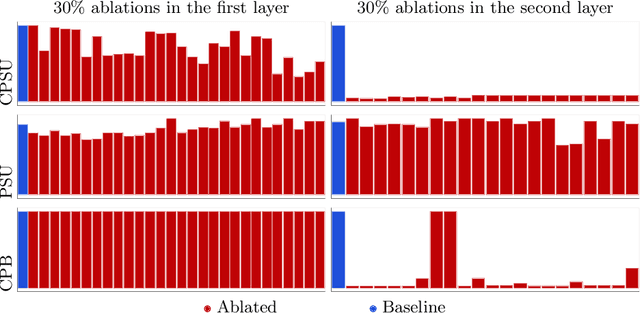
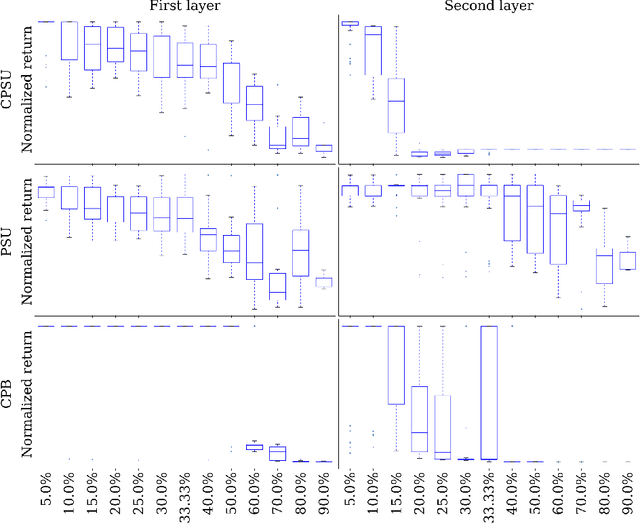
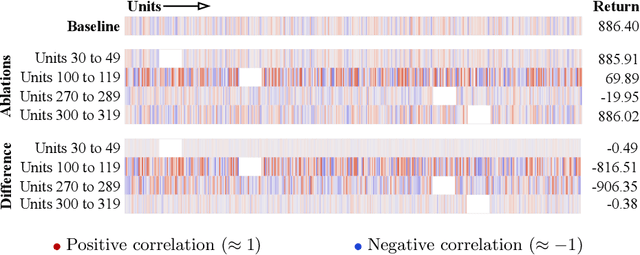
The demand for more transparency of decision-making processes of deep reinforcement learning agents is greater than ever, due to their increased use in safety critical and ethically challenging domains such as autonomous driving. In this empirical study, we address this lack of transparency following an idea that is inspired by research in the field of neuroscience. We characterize the learned representations of an agent's policy network through its activation space and perform partial network ablations to compare the representations of the healthy and the intentionally damaged networks. We show that the healthy agent's behavior is characterized by a distinct correlation pattern between the network's layer activation and the performed actions during an episode and that network ablations, which cause a strong change of this pattern, lead to the agent failing its trained control task. Furthermore, the learned representation of the healthy agent is characterized by a distinct pattern in its activation space reflecting its different behavioral stages during an episode, which again, when distorted by network ablations, leads to the agent failing its trained control task. Concludingly, we argue in favor of a new perspective on artificial neural networks as objects of empirical investigations, just as biological neural systems in neuroscientific studies, paving the way towards a new standard of scientific falsifiability with respect to research on transparency and interpretability of artificial neural networks.
Under the Hood of Neural Networks: Characterizing Learned Representations by Functional Neuron Populations and Network Ablations
Apr 02, 2020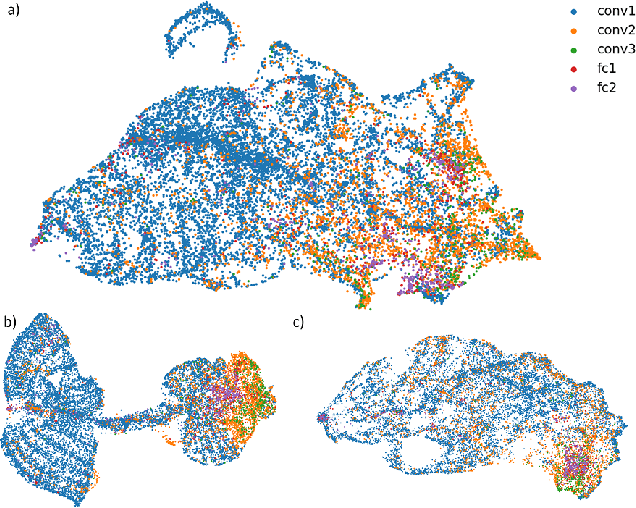
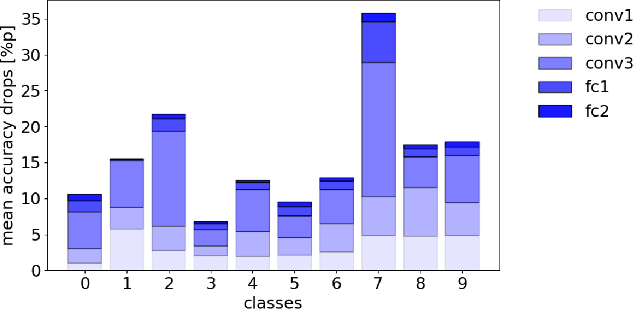
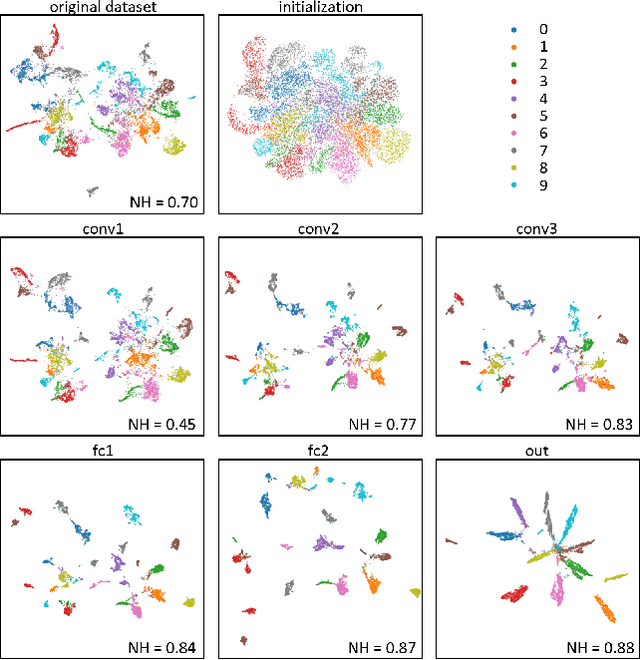
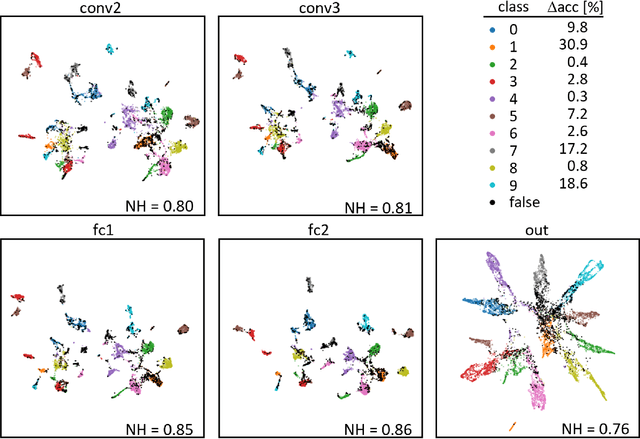
The need for more transparency of the decision-making processes in artificial neural networks steadily increases driven by their applications in safety critical and ethically challenging domains such as autonomous driving or medical diagnostics. We address today's lack of transparency of neural networks and shed light on the roles of single neurons and groups of neurons within the network fulfilling a learned task. Inspired by research in the field of neuroscience, we characterize the learned representations by activation patterns and network ablations, revealing functional neuron populations that a) act jointly in response to specific stimuli or b) have similar impact on the network's performance after being ablated. We find that neither a neuron's magnitude or selectivity of activation, nor its impact on network performance are sufficient stand-alone indicators for its importance for the overall task. We argue that such indicators are essential for future advances in transfer learning and modern neuroscience.
Ablation of a Robot's Brain: Neural Networks Under a Knife
Feb 01, 2019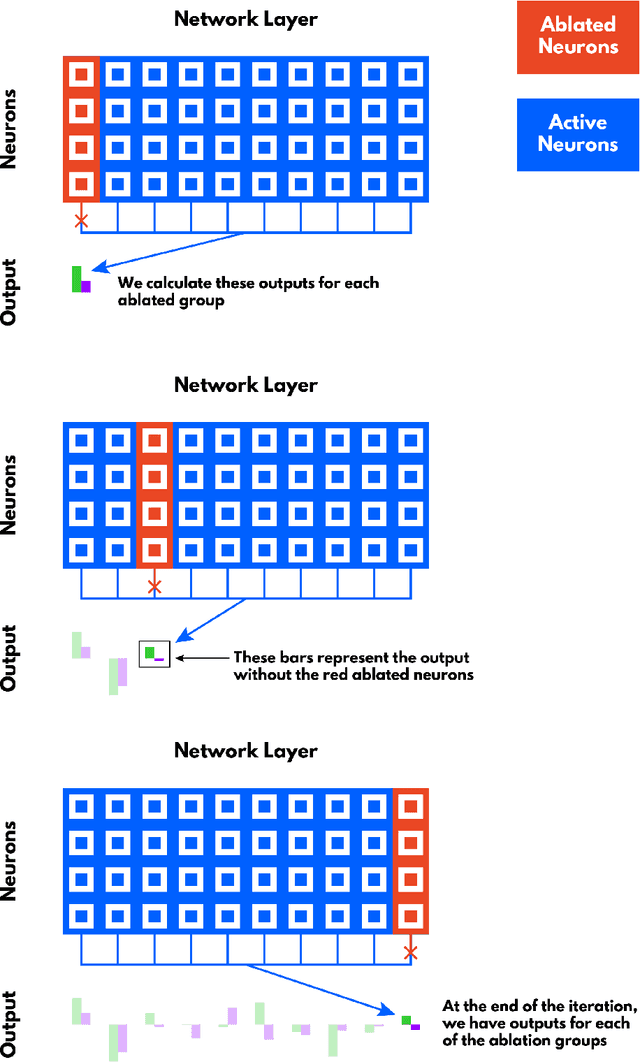
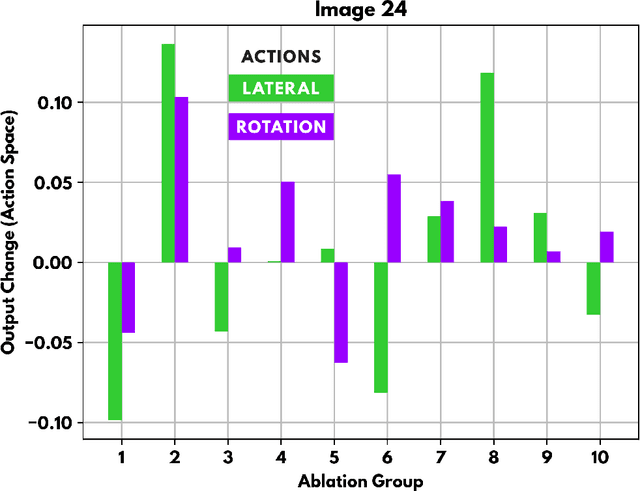
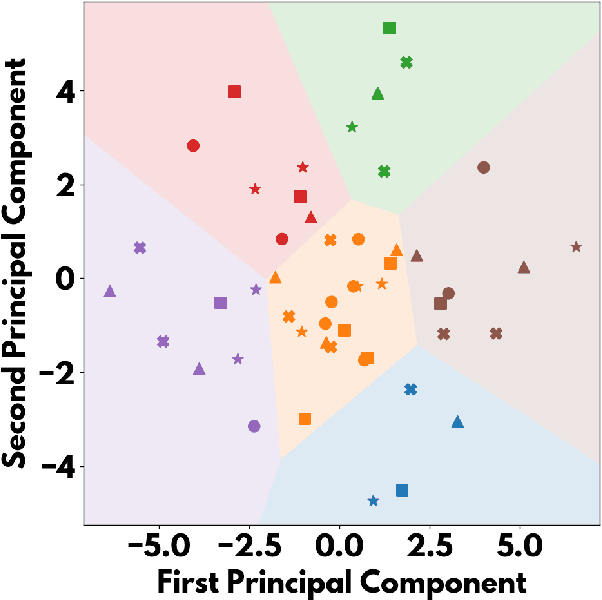
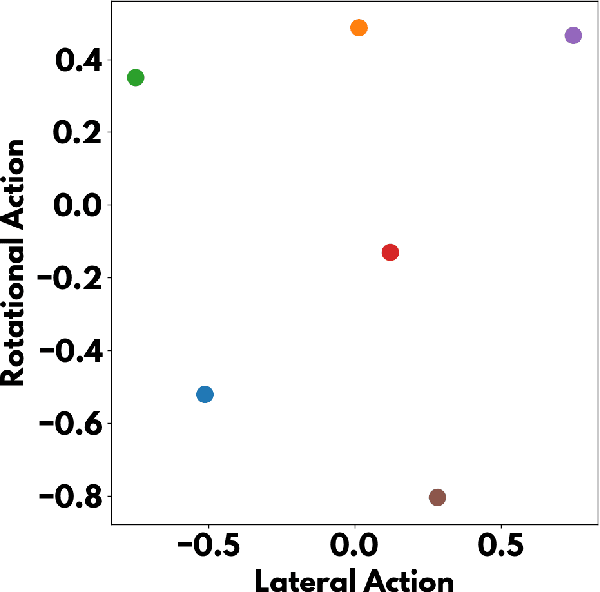
It is still not fully understood exactly how neural networks are able to solve the complex tasks that have recently pushed AI research forward. We present a novel method for determining how information is structured inside a neural network. Using ablation (a neuroscience technique for cutting away parts of a brain to determine their function), we approach several neural network architectures from a biological perspective. Through an analysis of this method's results, we examine important similarities between biological and artificial neural networks to search for the implicit knowledge locked away in the network's weights.
Ablation Studies in Artificial Neural Networks
Jan 24, 2019
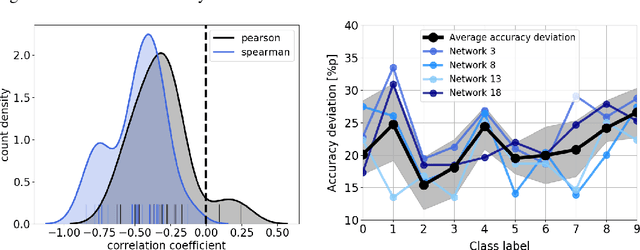
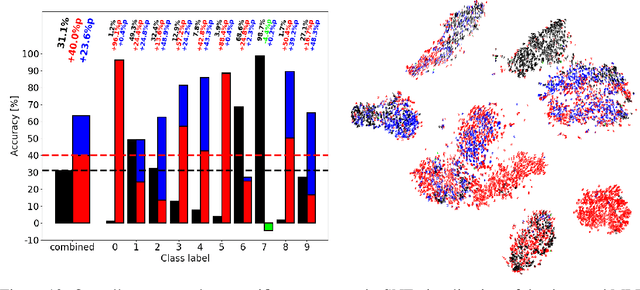
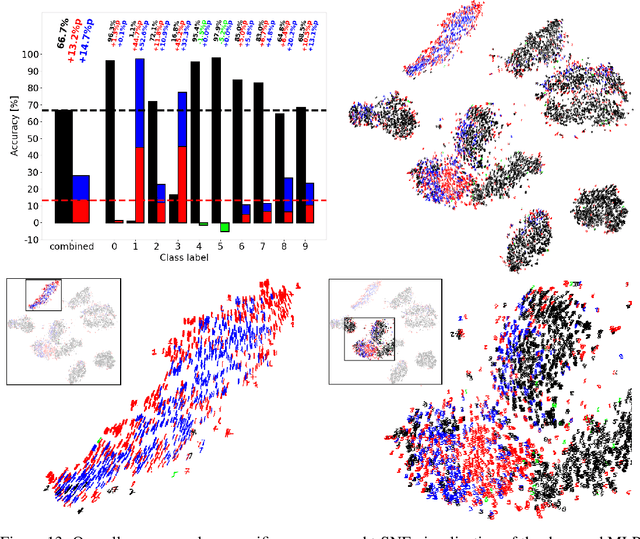
Ablation studies have been widely used in the field of neuroscience to tackle complex biological systems such as the extensively studied Drosophila central nervous system, the vertebrate brain and more interestingly and most delicately, the human brain. In the past, these kinds of studies were utilized to uncover structure and organization in the brain, i.e. a mapping of features inherent to external stimuli onto different areas of the neocortex. considering the growth in size and complexity of state-of-the-art artificial neural networks (ANNs) and the corresponding growth in complexity of the tasks that are tackled by these networks, the question arises whether ablation studies may be used to investigate these networks for a similar organization of their inner representations. In this paper, we address this question and performed two ablation studies in two fundamentally different ANNs to investigate their inner representations of two well-known benchmark datasets from the computer vision domain. We found that features distinct to the local and global structure of the data are selectively represented in specific parts of the network. Furthermore, some of these representations are redundant, awarding the network a certain robustness to structural damages. We further determined the importance of specific parts of the network for the classification task solely based on the weight structure of single units. Finally, we examined the ability of damaged networks to recover from the consequences of ablations by means of recovery training. We argue that ablations studies are a feasible method to investigate knowledge representations in ANNs and are especially helpful to examine a networks robustness to structural damages, a feature of ANNs that will become increasingly important for future safety-critical applications.