 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do You Act? An Empirical Study to Understand Behavior of Deep Reinforcement Learning Agents
Paper and Code
Apr 07, 2020
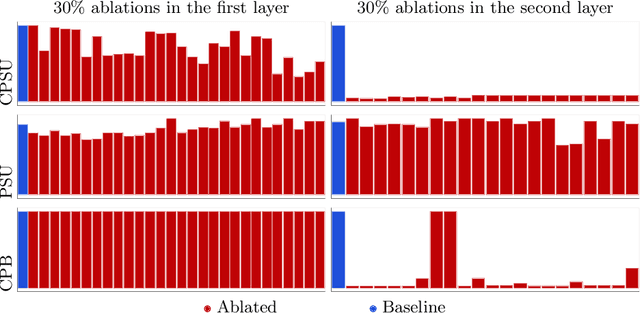
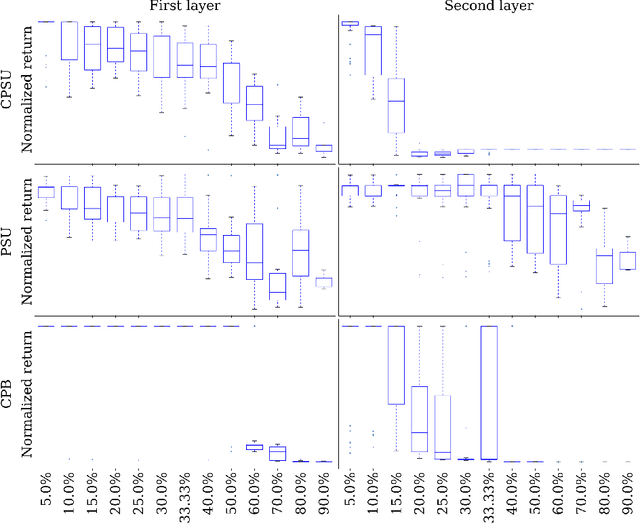
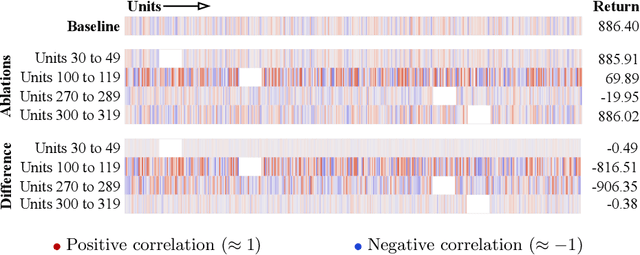
The demand for more transparency of decision-making processes of deep reinforcement learning agents is greater than ever, due to their increased use in safety critical and ethically challenging domains such as autonomous driving. In this empirical study, we address this lack of transparency following an idea that is inspired by research in the field of neuroscience. We characterize the learned representations of an agent's policy network through its activation space and perform partial network ablations to compare the representations of the healthy and the intentionally damaged networks. We show that the healthy agent's behavior is characterized by a distinct correlation pattern between the network's layer activation and the performed actions during an episode and that network ablations, which cause a strong change of this pattern, lead to the agent failing its trained control task. Furthermore, the learned representation of the healthy agent is characterized by a distinct pattern in its activation space reflecting its different behavioral stages during an episode, which again, when distorted by network ablations, leads to the agent failing its trained control task. Concludingly, we argue in favor of a new perspective on artificial neural networks as objects of empirical investigations, just as biological neural systems in neuroscientific studies, paving the way towards a new standard of scientific falsifiability with respect to research on transparency and interpretability of artificial neural networks.