 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning
Apr 24, 2025Agents that can autonomously navigate the web through a graphical user interface (GUI) using a unified action space (e.g., mouse and keyboard actions) can require very large amounts of domain-specific expert demonstrations to achieve good performance. Low sample efficiency is often exacerbated in sparse-reward and large-action-space environments, such as a web GUI, where only a few actions are relevant in any given situation. In this work, we consider the low-data regime, with limited or no access to expert behavior. To enable sample-efficient learning, we explore the effect of constraining the action space through $\textit{intent-based affordances}$ -- i.e., considering in any situation only the subset of actions that achieve a desired outcome. We propose $\textbf{Code as Generative Affordances}$ $(\textbf{$\texttt{CoGA}$})$, a method that leverages pre-trained vision-language models (VLMs) to generate code that determines affordable actions through implicit intent-completion functions and using a fully-automated program generation and verification pipeline. These programs are then used in-the-loop of a reinforcement learning agent to return a set of affordances given a pixel observation. By greatly reducing the number of actions that an agent must consider, we demonstrate on a wide range of tasks in the MiniWob++ benchmark that: $\textbf{1)}$ $\texttt{CoGA}$ is orders of magnitude more sample efficient than its RL agent, $\textbf{2)}$ $\texttt{CoGA}$'s programs can generalize within a family of tasks, and $\textbf{3)}$ $\texttt{CoGA}$ performs better or on par compared with behavior cloning when a small number of expert demonstrations is available.
Parseval Regularization for Continual Reinforcement Learning
Dec 10, 2024



Loss of plasticity, trainability loss, and primacy bias have been identified as issues arising when training deep neural networks on sequences of tasks -- all referring to the increased difficulty in training on new tasks. We propose to use Parseval regularization, which maintains orthogonality of weight matrices, to preserve useful optimization properties and improve training in a continual reinforcement learning setting. We show that it provides significant benefits to RL agents on a suite of gridworld, CARL and MetaWorld tasks. We conduct comprehensive ablations to identify the source of its benefits and investigate the effect of certain metrics associated to network trainability including weight matrix rank, weight norms and policy entropy.
Learning diverse attacks on large language models for robust red-teaming and safety tuning
May 28, 2024Red-teaming, or identifying prompts that elicit harmful responses, is a critical step in ensuring the safe and responsible deployment of large language models (LLMs). Developing effective protection against many modes of attack prompts requires discovering diverse attacks. Automated red-teaming typically uses reinforcement learning to fine-tune an attacker language model to generate prompts that elicit undesirable responses from a target LLM, as measured, for example, by an auxiliary toxicity classifier. We show that even with explicit regularization to favor novelty and diversity, existing approaches suffer from mode collapse or fail to generate effective attacks. As a flexible and probabilistically principled alternative, we propose to use GFlowNet fine-tuning, followed by a secondary smoothing phase, to train the attacker model to generate diverse and effective attack prompts. We find that the attacks generated by our method are effective against a wide range of target LLMs, both with and without safety tuning, and transfer well between target LLMs. Finally, we demonstrate that models safety-tuned using a dataset of red-teaming prompts generated by our method are robust to attacks from other RL-based red-teaming approaches.
Evaluation of Key Spatiotemporal Learners for Print Track Anomaly Classification Using Melt Pool Image Streams
Aug 28, 2023
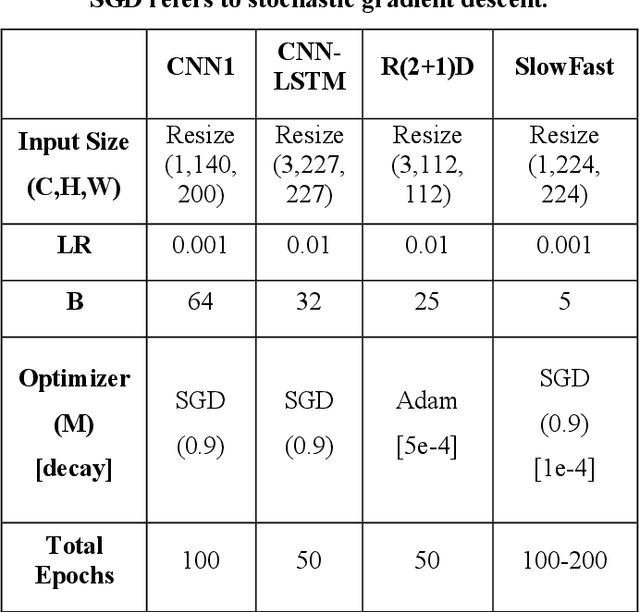


Recent applications of machine learning in metal additive manufacturing (MAM) have demonstrated significant potential in addressing critical barriers to the widespread adoption of MAM technology. Recent research in this field emphasizes the importance of utilizing melt pool signatures for real-time defect prediction. While high-quality melt pool image data holds the promise of enabling precise predictions, there has been limited exploration into the utilization of cutting-edge spatiotemporal models that can harness the inherent transient and sequential characteristics of the additive manufacturing process. This research introduces and puts into practice some of the leading deep spatiotemporal learning models that can be adapted for the classification of melt pool image streams originating from various materials, systems, and applications. Specifically, it investigates two-stream networks comprising spatial and temporal streams, a recurrent spatial network, and a factorized 3D convolutional neural network. The capacity of these models to generalize when exposed to perturbations in melt pool image data is examined using data perturbation techniques grounded in real-world process scenarios. The implemented architectures demonstrate the ability to capture the spatiotemporal features of melt pool image sequences. However, among these models, only the Kinetics400 pre-trained SlowFast network, categorized as a two-stream network, exhibits robust generalization capabilities in the presence of data perturbations.