 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

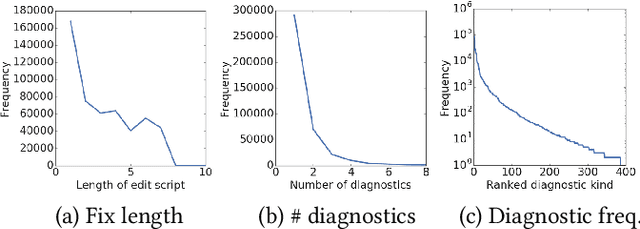

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.
Fast Training of Sparse Graph Neural Networks on Dense Hardware
Jun 27, 2019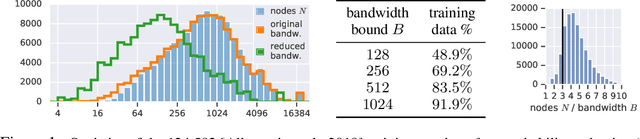


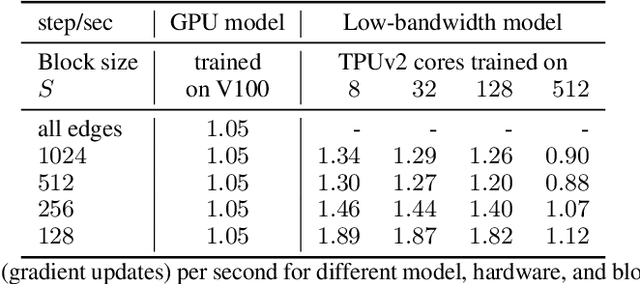
Graph neural networks have become increasingly popular in recent years due to their ability to naturally encode relational input data and their ability to scale to large graphs by operating on a sparse representation of graph adjacency matrices. As we look to scale up these models using custom hardware, a natural assumption would be that we need hardware tailored to sparse operations and/or dynamic control flow. In this work, we question this assumption by scaling up sparse graph neural networks using a platform targeted at dense computation on fixed-size data. Drawing inspiration from optimization of numerical algorithms on sparse matrices, we develop techniques that enable training the sparse graph neural network model from Allamanis et al. [2018] in 13 minutes using a 512-core TPUv2 Pod, whereas the original training takes almost a day.
Distributional reinforcement learning with linear function approximation
Feb 08, 2019
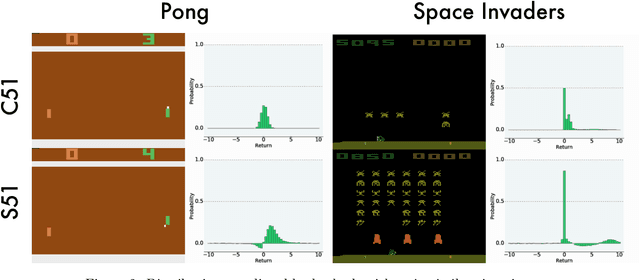
Despite many algorithmic advances, our theoretical understanding of practical distributional reinforcement learning methods remains limited. One exception is Rowland et al. (2018)'s analysis of the C51 algorithm in terms of the Cram\'er distance, but their results only apply to the tabular setting and ignore C51's use of a softmax to produce normalized distributions. In this paper we adapt the Cram\'er distance to deal with arbitrary vectors. From it we derive a new distributional algorithm which is fully Cram\'er-based and can be combined to linear function approximation, with formal guarantees in the context of policy evaluation. In allowing the model's prediction to be any real vector, we lose the probabilistic interpretation behind the method, but otherwise maintain the appealing properties of distributional approaches. To the best of our knowledge, ours is the first proof of convergence of a distributional algorithm combined with function approximation. Perhaps surprisingly, our results provide evidence that Cram\'er-based distributional methods may perform worse than directly approximating the value function.
* To appear
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019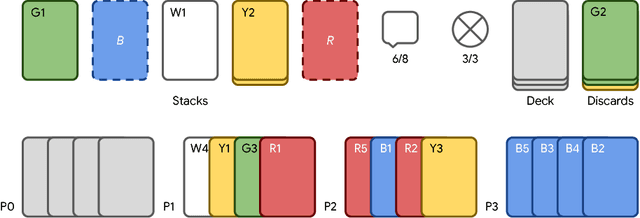
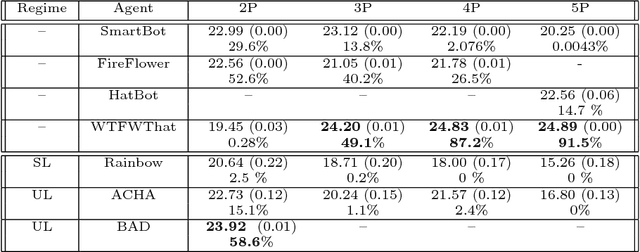
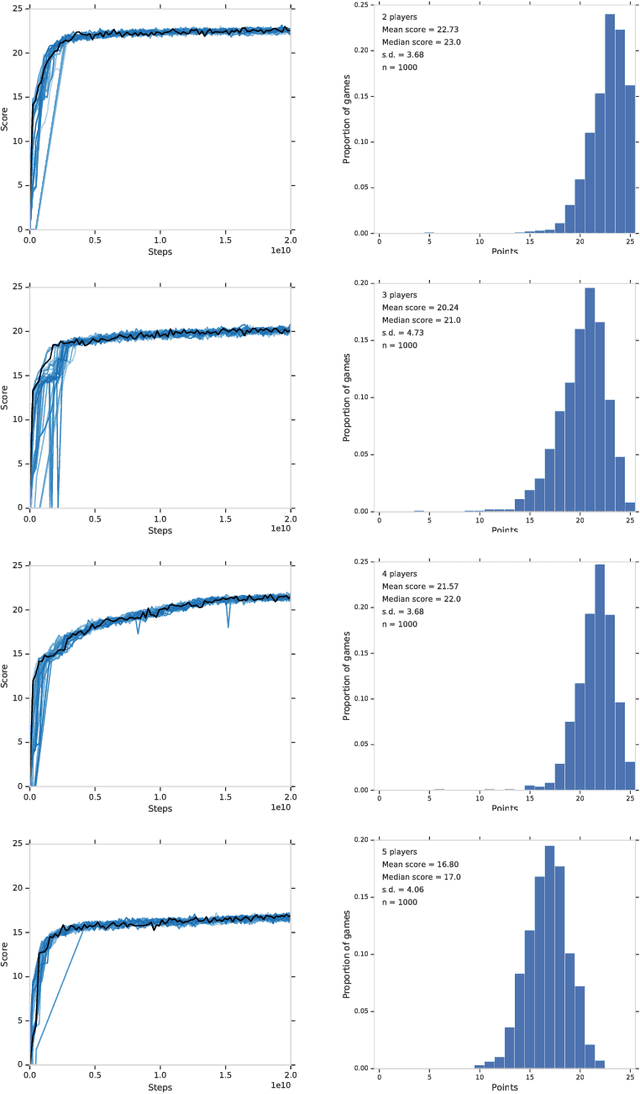
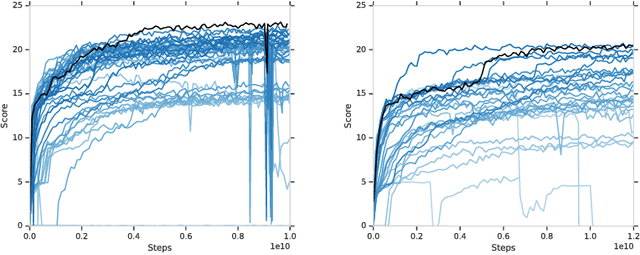
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Dopamine: A Research Framework for Deep Reinforcement Learning
Dec 14, 2018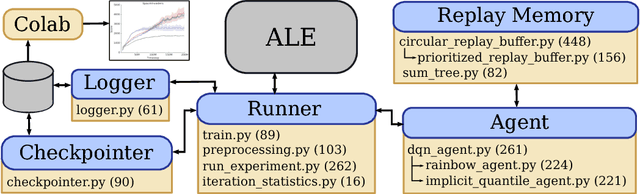
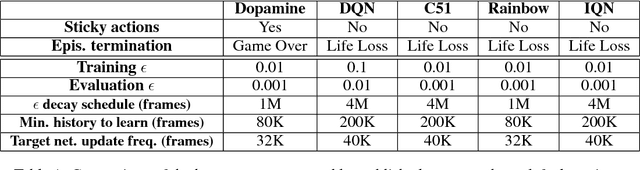

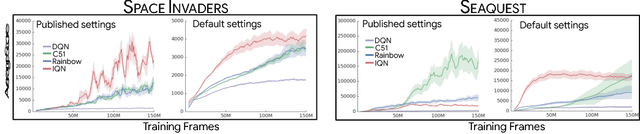
Deep reinforcement learning (deep RL) research has grown significantly in recent years. A number of software offerings now exist that provide stable, comprehensive implementations for benchmarking. At the same time, recent deep RL research has become more diverse in its goals. In this paper we introduce Dopamine, a new research framework for deep RL that aims to support some of that diversity. Dopamine is open-source, TensorFlow-based, and provides compact and reliable implementations of some state-of-the-art deep RL agents. We complement this offering with a taxonomy of the different research objectives in deep RL research. While by no means exhaustive, our analysis highlights the heterogeneity of research in the field, and the value of frameworks such as ours.